フォーム読み込み中
BookRAG紹介:階層構造・知識グラフ・エージェント検索による高精度RAG

TASUKI事業部 エンジニア
CHEN CHEN
2025年1月よりソフトバンクに入社し、データ構造化ツール「TASUKI」の技術研究に携わっています。新たにAgent技術の探究にも注力し、コンサルティング業務を含め複数のプロジェクトで活躍中。データ構造化とAgent開発の両面から、組織や社会の課題解決に寄与し、新しい価値を創出することを目指しています。
2026年3月13日掲載

RAG(Retrieval-Augmented Generation)は、LLMに外部知識を与えて回答精度を高める技術です。しかし、従来のRAGには固定長チャンク分割による文脈の分断、構造認識チャンクでも解消できない階層構造の喪失やチャンク間の関連性断絶といった課題があります。
本記事では、Tree構造とGraph構造(BookIndex)を組み合わせて文書の階層性と関連性を保持し、Agent-based Retrievalでクエリに応じた最適な検索を実行する「BookRAG」の仕組みを解説します。
BookRAGは、2025年12月に発表された論文「BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents」(Shu Wang et al.)で提案された手法です。
1. はじめに
RAG(Retrieval-Augmented Generation)は、LLMに外部知識を与えて回答精度を高める技術です。社内文書やPDFをLLMに読ませて質問応答させる場面で広く使われています。
しかし、従来のRAGには検索精度の限界があります。固定長チャンクでは文章の途中で分割され文脈が失われます。構造認識チャンク(Layout認識)を使っても、目次→章→節といった階層構造やチャンク間の関連性は保持できません。本記事では、これらの課題を解決するBookRAGの仕組みを紹介します。
2. 従来RAGの課題
固定長チャンクの課題
従来のRAGでは、文書を一定の長さ(トークン数)で分割する固定長チャンクが一般的です。しかし、この方法には以下の問題があります。
- 文脈の分断 — 文章の途中でチャンクが切れ、意味が失われる
- テーブルの分割 — 表が複数チャンクに分かれ、構造が壊れる
- 画像の切断 — 図表とキャプションが別チャンクに分離される
構造認識チャンクの課題
Layout認識を使った構造認識チャンクでは、段落や表などの構造単位で分割するため、固定長チャンクの問題は軽減されます。しかし、以下の課題が残ります。
- 階層構造の喪失 — 目次→章→節といった文書の階層構造が失われる
- チャンク間の関連性の断絶 — ある章で定義された用語が別の章で参照されている場合、その関連性を追跡できない
また、複数のチャンクにまたがる情報を統合して回答する必要がある質問にも対応が困難です。
3. BookRAGとは
BookRAGは、2つのアプローチで従来RAGの課題を解決します。
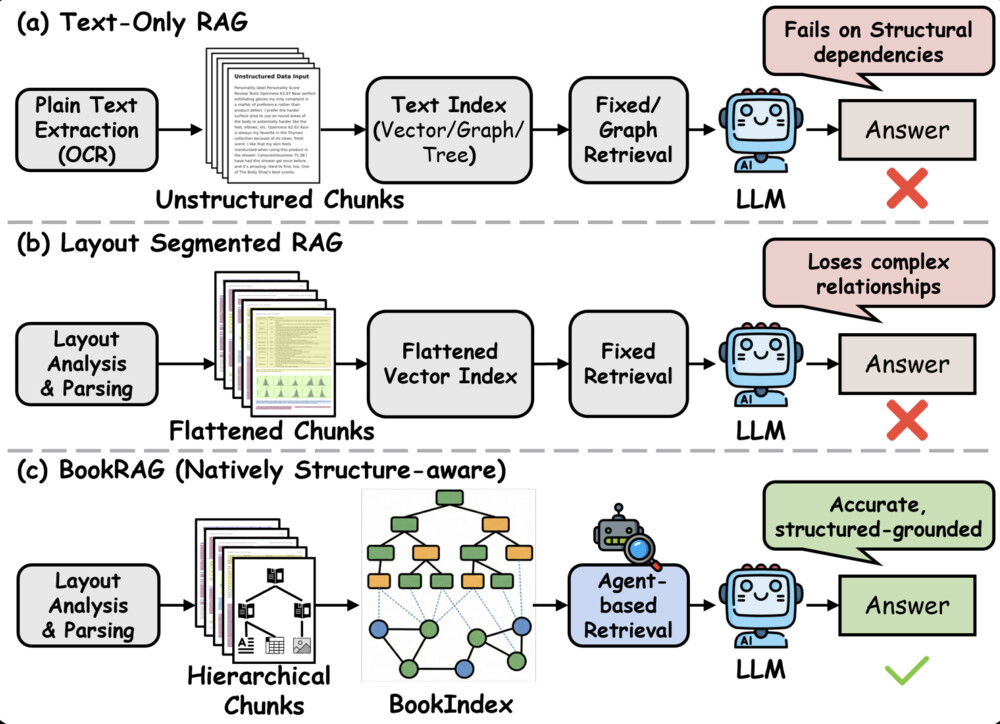
図1:従来RAGとBookRAGの比較
| アプローチ | 内容 |
|---|---|
| データ整備:BookIndex | 文書の階層構造(Tree)と概念間の関連性(Graph)を構築 |
| データ検索:Agent-based Retrieval | クエリの種類に応じてAgentが最適な検索戦略を選択 |
4. データ整備:BookIndex
BookRAGでは、文書を解析して2つの構造を構築します。
Tree構造
PDFの見出し階層を保持したツリー構造です。各ノードにはテキスト、テーブル(HTML形式)、画像が格納されます。
Graph構造
各ノードからエンティティと関係を抽出し、ナレッジグラフを構築します。
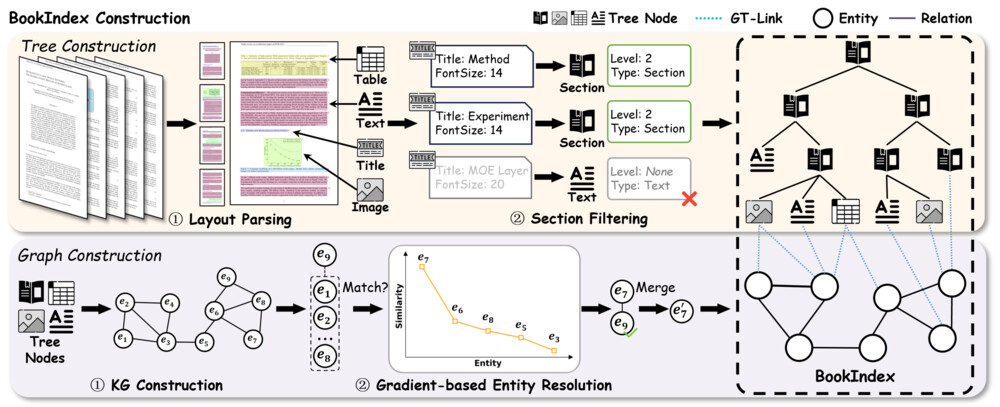
図2:Tree構造とGraph構造の連携(GT-Link)
GT-Link
GraphのエンティティとTreeのノードを紐づけることで、キーワードから関連するチャンクを階層的に取得できます。
5. データ検索:Agent-based Retrieval
BookRAGでは、クエリを3つのタイプに分類し、それぞれ最適な検索フローを実行します。
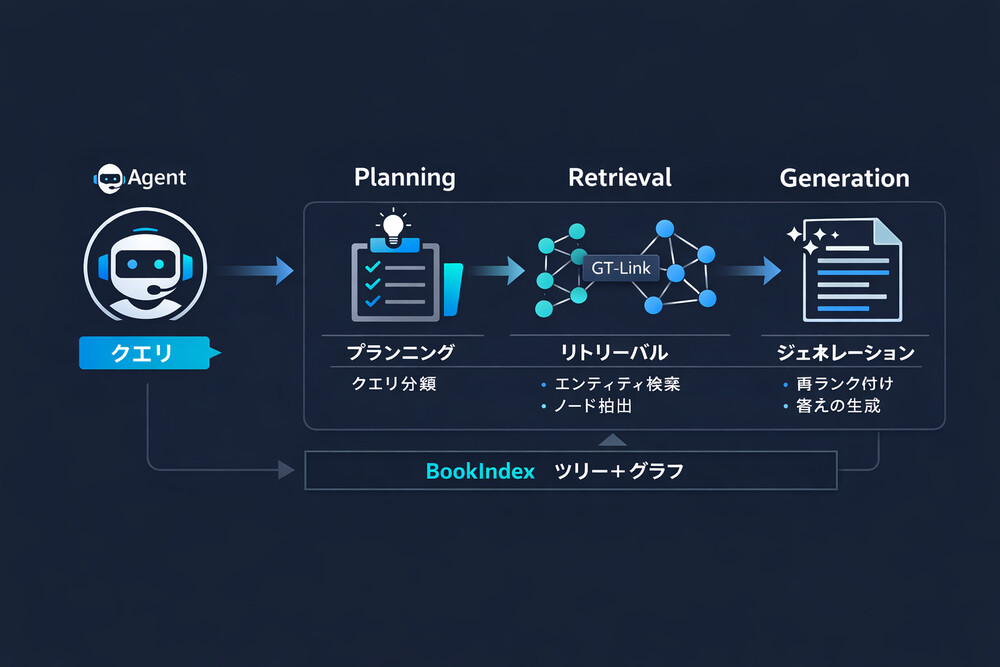
図3:Agent-based Retrievalの検索フロー
| タイプ | 特徴 | 例 |
|---|---|---|
| Simple | 1箇所の検索で回答可能 | 「2024年度の売上高は?」 |
| Complex | 複数箇所の検索が必要 | 「売上高と利益率の関係は?」 |
| Global | フィルタ+集約操作 | 「この報告書の要点は?」 |
6. 実装ステップ
BookRAGのデータ整備(BookIndex構築)は、以下の4つのステップで行います。
Step 1. PDF解析
Azure Document Intelligenceを使用して、PDFからタイトル・テキスト・テーブル・画像などの構造化データを抽出します。各要素にはページ番号や位置情報も付与されます。
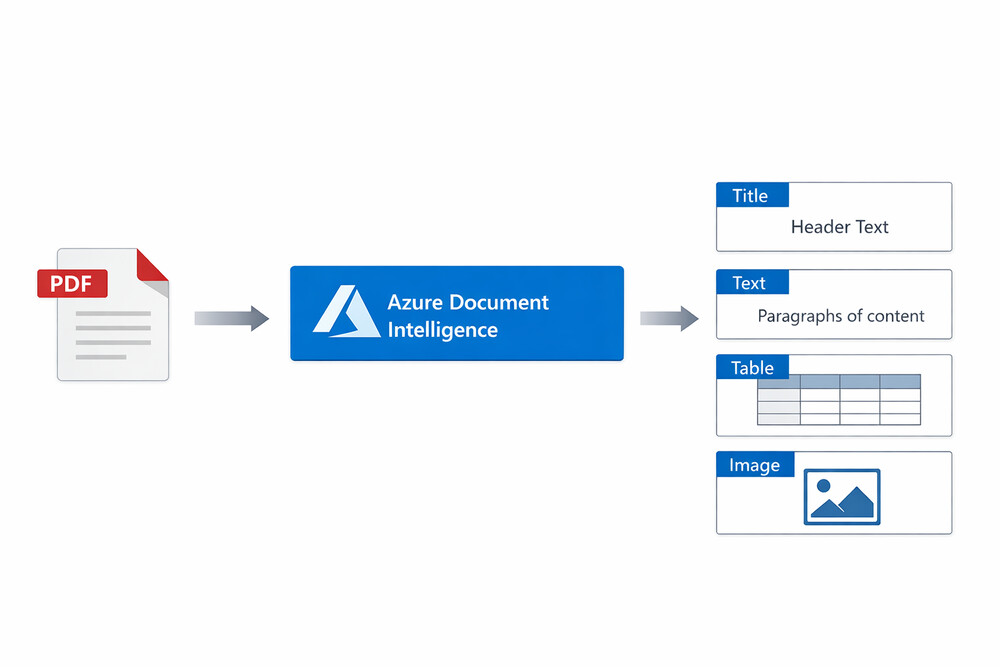
図4:PDF解析プロセス — Azure Document Intelligenceでタイトル・テキスト・テーブル・画像を抽出
Step 2. Tree構築
抽出した要素を見出し階層に基づいてツリー構造に整理します。各ノードにはtype(TITLE / TEXT / TABLE / IMAGE)、content、childrenなどの情報が格納されます。

図5:Tree構築プロセス — 見出し階層をツリーに整理し、各ノードにtype/content/childrenを格納
Step 3. Graph構築
各ノードのコンテンツからLLMを使ってエンティティと関係を抽出し、ナレッジグラフを構築します。これにより、文書内の概念間の関連性が明示的に表現されます。
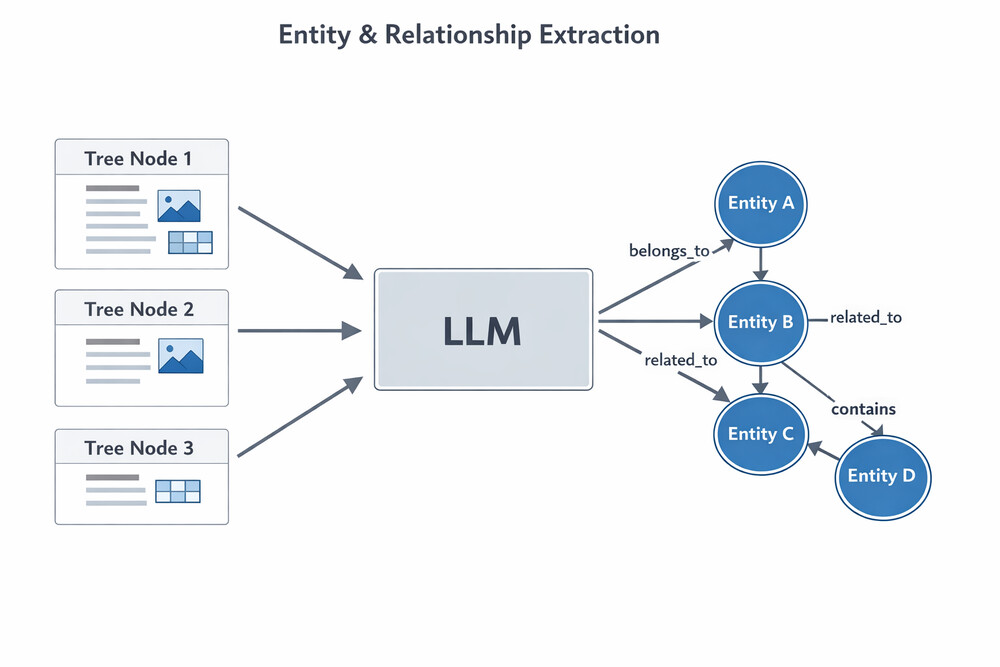
図6:Graph構築プロセス — 各ノードからエンティティと関係を抽出しナレッジグラフを構築
Step 4. Agent-based Retrieval
構築したBookIndexに対して、クエリタイプ(Simple / Complex / Global)を判定し、それぞれに最適な検索戦略を実行します。Tree構造とGraph構造を組み合わせて、必要な情報を階層的に取得します。
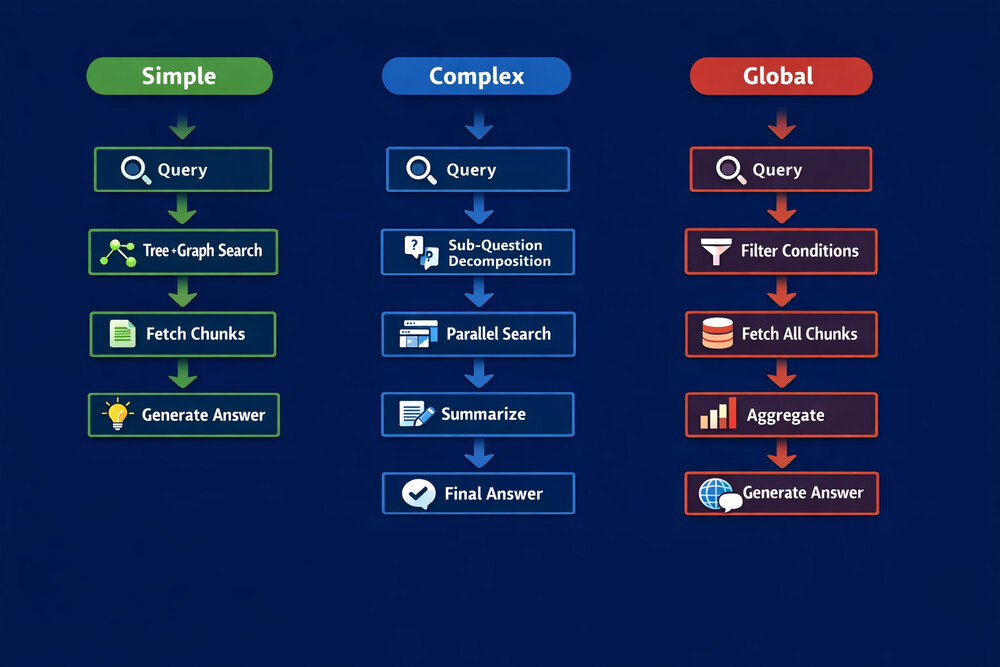
図7:Agent-based Retrieval — クエリタイプに応じた検索実行プラン
7. まとめ
BookRAGは、Tree+Graph (BookIndex)によるデータ整備とAgent-based Retrievalによる検索で、従来RAGの課題を解決します。
- Tree構造で文書の階層性を保持
- Graph構造でエンティティ間の関連性を構築
- Agent-based Retrievalでクエリに応じた最適な検索を実行
コスト・応答時間のトレードオフ
BookRAGは検索精度を向上させる一方で、コストと応答時間が増加するトレードオフがあります。導入を検討する際は、ユースケースに応じたコスト対効果の評価が重要です。高い検索精度が求められる場面(社内ナレッジ検索、複雑な文書のQAなど)では大きな価値を発揮しますが、シンプルな質問応答には従来のRAGで十分な場合もあります。
RAGの精度向上には、チャンク分割だけでなく、文書構造と関連性の理解が重要です。コストとのバランスを考慮し、ユースケースに応じた最適なアプローチを選択しましょう。
関連サービス
TASUKI Annotation RAGデータ作成ツールは、RAGを高度に活用する際に課題となるポイントをテクノロジーで支援するツールです。
RAGに関する知見がなくても、社内データを活用した精度の高いRAG回答生成を簡単に得ることが可能です。
おすすめの記事
条件に該当するページがございません



