フォーム読み込み中
Alibaba Cloudの最新技術で構築する リアルタイム分析をサポートしたDWH

クラウドテクノロジーブログ編集チーム
ソフトバンクのエンジニアが、その専門分野で様々な記事を日々執筆しています。
2020年10月16日掲載

前回のコラムではリアルタイム分析の重要性と、それを実現する3つのプロダクトをご紹介しました。
関連記事リンク
今回はより高度な取り組みとして、大規模かつ多様なデータを活用する場合のデータ分析基盤、そしてAlibaba Cloudが提案する次世代のデータ分析基盤、「リアルタイムDWH」についても解説していきます。
- DataWorksではデータの前処理やデータの統合を一元管理でき、ノンコードで開発やライブデータのシェアリングが可能
- MaxComputeでストレージコストを大幅に節約しながら無制限にスケーリングするDWH構築
- 最新プロダクトのHologresによりバッチレイヤー、スピードレイヤー、サービスレイヤーを統合したリアルタイムDWHを実現ここに記事概要が入ります。ここに記事概要が入ります。
「ビッグデータ」の本質的な活用
さまざまなデータを元にビジネス上の意思決定するにあたって、ビッグデータの3V(大量、多様性、速度)が増すほどに対応するのは難しくなります。 例えば、小売業における毎日の売上情報と顧客情報から、
①直近1週間分の売り上げや購入数を抽出するために毎日1,2回集計を実施するバッチレイヤー
②現在の売上情報などをリアルタイムで可視化するスピードレイヤー
③これらのデータを1つにまとめて、そこからリアルタイムレコメンデーションを表示するサービスレイヤー
を作るとなった場合、量も、種類も、時間軸も異なるデータが統合されたデータ基盤を構築する必要がありますが、これは技術的には非常に難易度の高いチャレンジになってきます。 今回はこれらを実現するAlibaba Cloudの3つのプロダクト、「DataWorks」「MaxCompute」「Hologres」を軸に解説していきます。
なぜDWHが必要か
DWH(データウェアハウス)はその名の通り「データの倉庫」として、通常のリレーショナルデータベースでは扱えきれない量のデータが蓄積され、そのデータの運用、そして分析を支える役割を持ちます。ビジネスの成長に伴ってさまざまな場所で発生する、まさに“ビッグデータ”の全てを集約して分析するための基盤として登場したのがDWHです。
各所に分散したデータを収集・分析しやすいように整形する工程(前処理)は非常に手間がかかります。これに対してDWHは、決まったパターンでデータが収集され、統一したフォーマットに変換して格納されるように設計することで、この前処理の工程を簡略化するものです。
したがって、DWHは大量のデータの取り込みから、保存、処理(OLTP、ETL)、分析までをシンプルに行えるよう設計されなければいけません。それによってDWH利用者は前処理ではなく分析作業(OLAP)に集中することができるからです。
DWH運用の課題
しかしDWHを実際に運用するにあたってはさまざまな課題があります。よくお客さまから耳にする声としては、
- 実際はデータの分析ではなく前処理に8割のリソースが費やされていること
- データ量の増加に伴い処理速度が落ちてしまうこと(Data Gravity)
- 利用頻度の高いデータ(Hot Data)と低いデータ(Cold Data)の混在によってデータ量が肥大化し、DWH保持コストが増大すること
- DWH運用を十分に使いこなすための学習コストがかかること
- リアルタイム処理をサポートするDWHを構築する上で、データの重複と欠損などデータの正当性が担保できないこと
などが挙げられます。近年、多くの企業では、これらのDWHの運用や処理遅延、コストなどの問題に頭を悩ませているのが実情です。
上記の課題を踏まえると、DWHの構築・運用は非常にハードルが高く見えますが、Alibaba Cloudを活用することでシンプルかつシームレスにDWHの構築・運用が可能になります。
ワンクリックでDWH構築ができるDataWorks
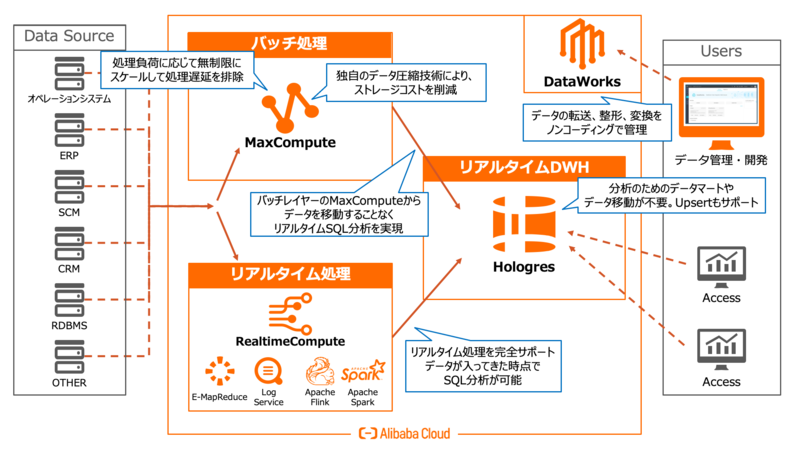
まず、DataWorksはデータ基盤を管理するプロダクトです。コーディング不要のワンクリックでDWHを構築できます。DataWorksはデータ処理を行うMaxComputeや異なるデータソースへ接続し、データの転送や整形・変換及び管理をGUI操作で簡単に実現するPaaS(Platform as α Service)です。これによりデータの前処理の負担を大幅に減らすことができます。
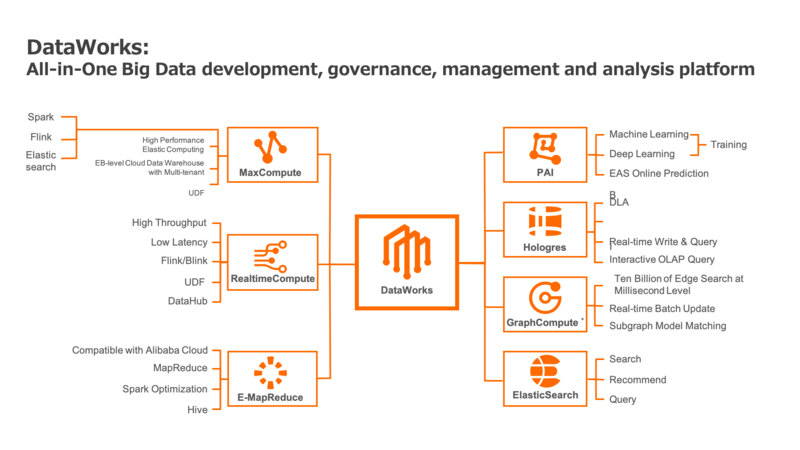 〈DataWorksによるデータ基盤管理〉
〈DataWorksによるデータ基盤管理〉
大規模データ処理とコスト圧縮を両立したMaxCompute
データ処理の中心となるのがサーバレス型のデータコンピューティングプロダクトのMaxComputeです。ストレージ層とコンピューティング層を分離したアーキテクチャになっており、EBクラスの大規模なDWH運用が可能です。
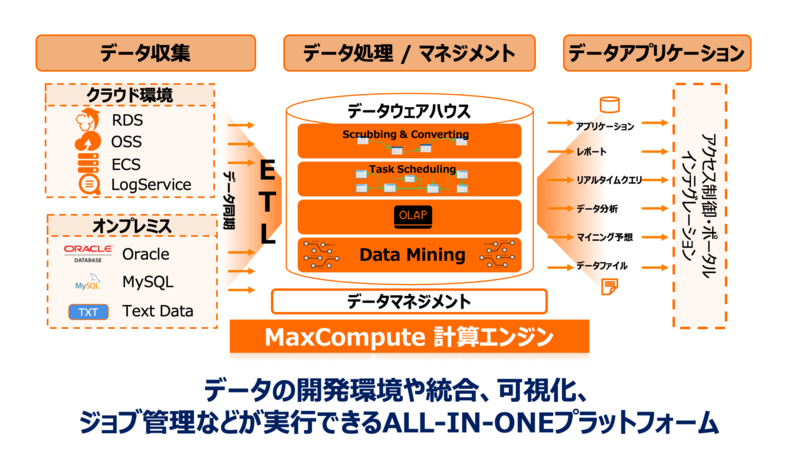 〈MaxComputeアーキテクチャ〉
〈MaxComputeアーキテクチャ〉
ストレージ層はCSV、JSON、HDFS_ORC、HDFS_Parquetなどのほか、Key-Valueや画像データ、SysLogなどの半構造化データもサポートします。データは独自の圧縮技術により通常のファイルサイズから約5倍圧縮されるので、コストを大幅に削減できます。
また、ユーザーはテーブルの操作インターフェースを利用するだけでストレージの管理や運用を意識する必要がなく、運用も手軽です。
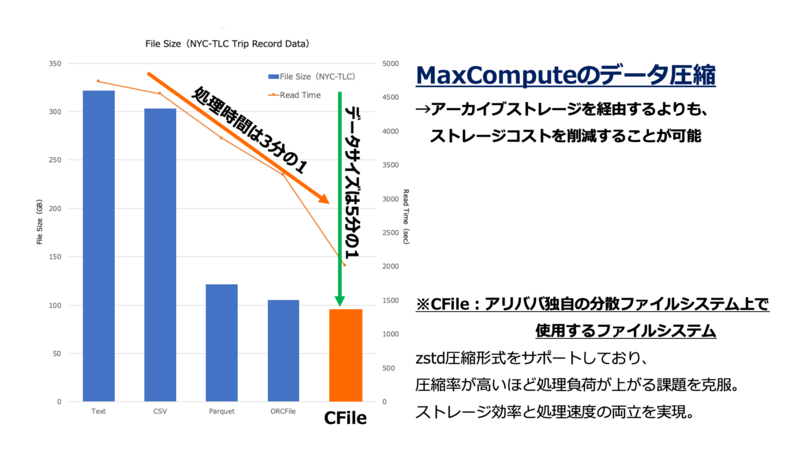 〈MaxComputeのストレージ圧縮技術〉
〈MaxComputeのストレージ圧縮技術〉
コンピューティング層はSQLクエリやジョブなど各種操作の処理負荷に応じてノード・クラスタが自動スケーリングし、MapReduceベースの分散並列処理を実行します。スケーリング上限は無制限です。こうした特長を活かし、BigData処理のベンチマークテストTPC-BBでも、毎年連続でNo.1を獲得しています。処理能力だけでなく、コストパフォーマンスでも他のプラットフォームを上回る結果を記録しています。
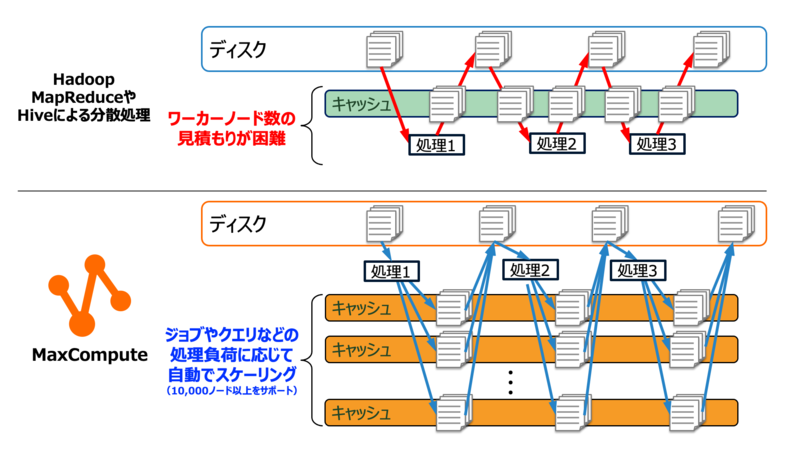 〈MapReduce処理のスケーリング〉
〈MapReduce処理のスケーリング〉
コストについては、ジョブやクエリが投げられた時にしか料金が発生しない仕組みとなっています。従って、データ規模が大きくなるほど他社と比較して高いコストパフォーマンスを発揮します。
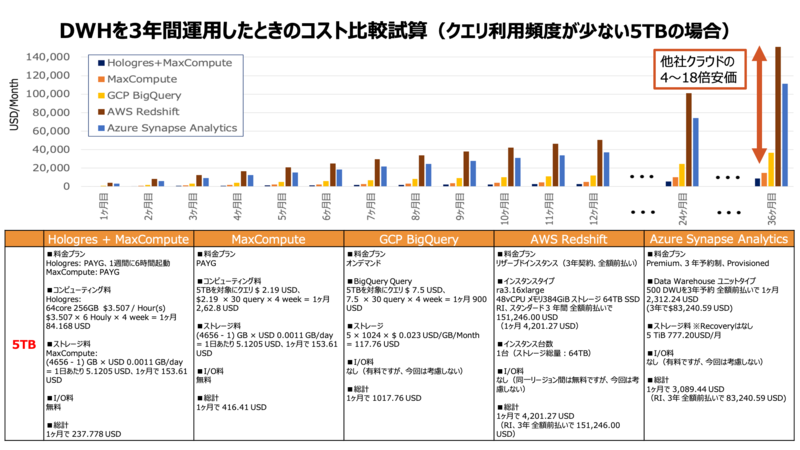
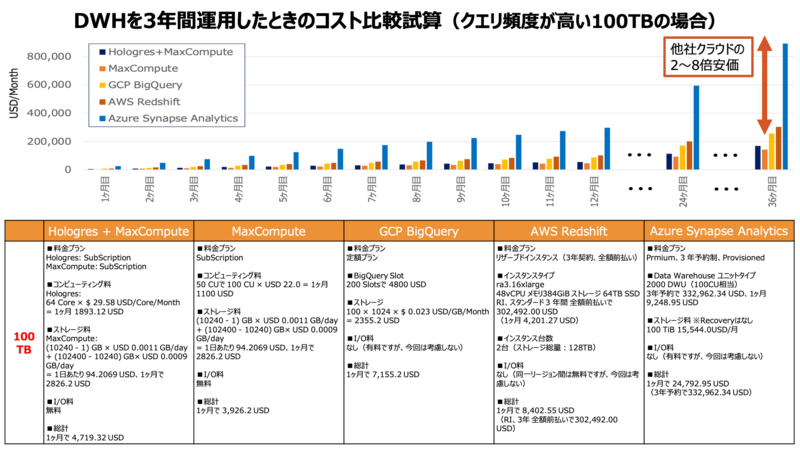
さらに、さまざまなデータ分析の要件にも対応しています。MaxComputeには SQL、MapReduce、Mars、PyODPS、Spark、機械学習などの機能が搭載されています。例えば機械学習用のコンポーネントであるMaxCompute Marsでは、数台のCPUまたはGPUクラスタを用いてNumpy, Pandas, scikit-learn, TensorFlow, PyTorch, XGBoostなどを、通常のGPUインスタンスを用いるより低コストかつ高速で処理できます。
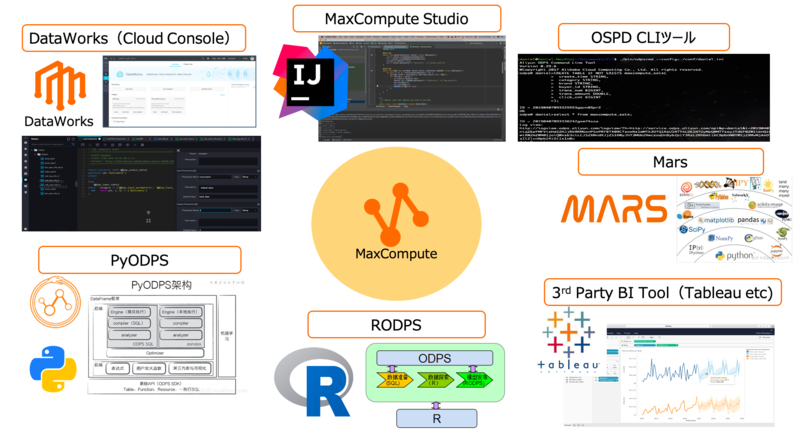 〈MaxComputeの操作環境〉
〈MaxComputeの操作環境〉
最先端の「リアルタイムDWH」 Hologres
一方でデータが収集された時点で分析まで実行するリアルタイム処理をDWHで実現できるのがAlibaba Cloudの最先端プロダクトのHologresです。データが入ってきた時点でSQLクエリによる分析・検索を可能にします。
Hologresはトランザクション処理と分析処理を同時にサポートするというコンセプトで、PostgreSQLと高い互換性を持ちながら、分析や更新、検索、削除クエリなどをサポートしています。
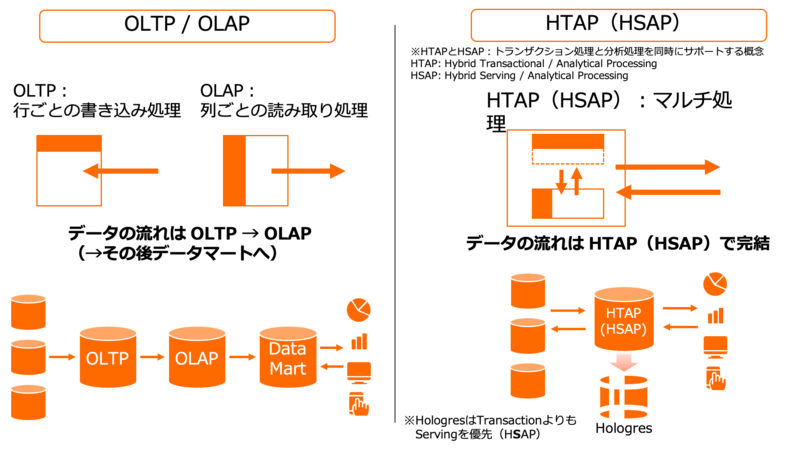 〈トランザクション処理と分析処理を同時にサポートするHTAP(HSAP)の概念〉
〈トランザクション処理と分析処理を同時にサポートするHTAP(HSAP)の概念〉
つまり分析のためにDWHからOLAPサービスやRDBなどのデータマートへデータを移動することなく、SQL分析することができるのです。MaxComputeからデータを移動せずに、MaxCompute Tableを使ってSQL分析することもできます。
これにより、データ分析のためにデータを移動することや、データマート自体が不要になる「リアルタイムDWH」が構築できます。
HologresはPostgreSQLと同じ操作インターフェースやSQLをサポートしており、学習コストがかかりにくいのも特長です。TableauなどのBIツール、embulkなどのデータ転送ツールともPostgreSQLベースで接続でき、気軽に利用できます。
 〈Hologresで実現できるアーキテクチャ〉
〈Hologresで実現できるアーキテクチャ〉
Alibaba Cloudでは、大規模データの処理や運用に強いDWHのMaxCompute、リアルタイム処理を実現するRealtimeCompute、それらを全て受け止めるリアルタイムエンジンHologresを組み合わせることで、バッチ処理とリアルタイム処理の両方を実行するためのDWHを構築できます。
まとめ
最後にまとめとして、前半で挙げたDWH運用における課題が、Alibaba Cloudでどのように解決策されるか振り返ってみましょう。(一部前回コラムの内容を含みます。)
- 実際はデータの分析ではなく前処理に8割のリソースが費やされていること
→DataWorksによるノーコードのGUI操作でデータの統合・シェアリングが可能なため手間を大幅に削減
- データ量の増加に伴い処理速度が落ちてしまうこと(Data Gravity)
→MaxComputeの無制限スケーリングと処理性能により大規模データも遅延なく処置・運用可能
- 利用頻度の高いデータ(Hot Data)と低いデータ(Cold Data)の混在によってデータ量が肥大化し、DWH保持コストが増大すること
→MaxComputeのストレージ圧縮機能によりコストを大幅に節約
- DWH運用を十分に使いこなすための学習コストがかかること
→Hologresでバッチ処理とリアルタイム処理の並行運用をPostgresSQLベースの操作・処理で実現
- リアルタイム処理をサポートしするDWHを構築するうえで、データの重複と欠損などデータの正当性が担保できないこと
→バッチレイヤー(大規模データの定例集計)はMaxCompute、スピードレイヤー(exactly once仕様によるリアルタイムデータのキャッチ)はRealtime Compute、サービスレイヤー(SQLによるOLAPやKeyValue検索)はHologres、という配置で重複・欠損のないデータ正当性を担保
 〈Alibaba Cloudが解決するDWH運用における課題〉
〈Alibaba Cloudが解決するDWH運用における課題〉
Alibaba CloudでDWHを構築することで、最先端技術を容易に活用することができます。大規模かつ多種多様なデータでも低コストで運用負担を最小限に抑えたリアルタイムな分析を可能にする、「リアルタイムDWH」が実現できるのです。
さて今回は、Alibaba CloudによるリアルタイムDWHについて解説しました。次回はデータの大きさや種類の多さだけでなく、システムの偏在によってサイロ化したデータ運用環境でも、統合データ基盤(DataLake)を構築するための方法について解説したいと思います。
関連サービス
Alibaba Cloud
Alibaba Cloudは中国国内でのクラウド利用はもちろん、日本-中国間のネットワークの不安定さの解消、中国サイバーセキュリティ法への対策など、中国進出に際する課題を解消できるパブリッククラウドサービスです。

大原 陽宣
ソフトバンク株式会社
クラウドエンジニアリング本部 PaaSエンジニアリング統括部
2019年からSBクラウドにJoin。収集、分散処理、ETL、検索、分析、機械学習基盤の構築、運用等を経て、現在分散系をメインとしたビッグデータとデータベースを得意・専門とするデータエンジニア。 AlibabaCloud MVP。
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



