目次
- 01.なぜ新しいAI for RANアーキテクチャーが必要か
- 02.出発点:単一タスクのベースライン(MWC 2025)
- 03.ConvolutionとSelf-Attentionの技術比較
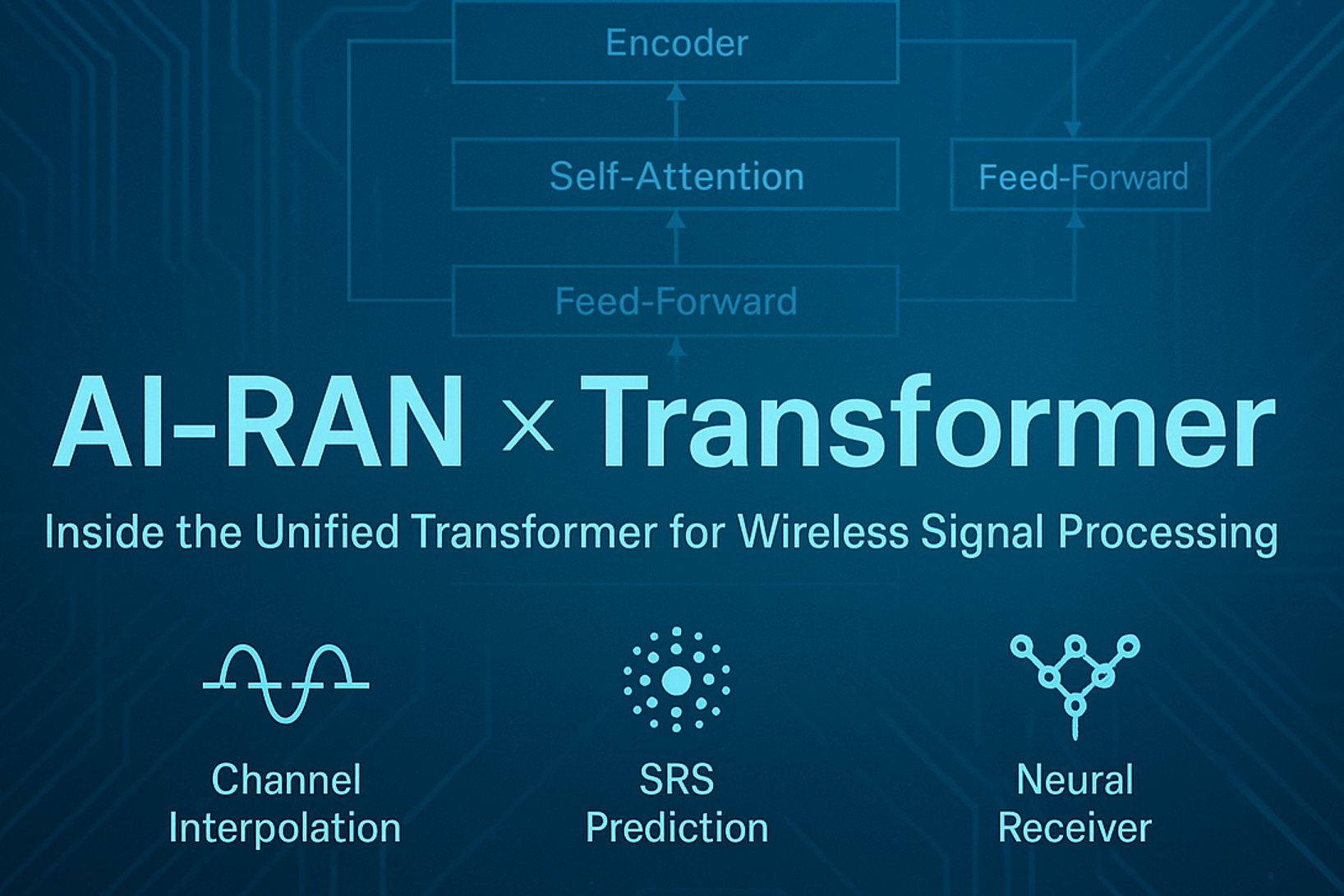
- 04.統一Transformer:設計原則
- 05.実行時の処理フロー
- 06.代表的なユースケース
- 07.実行時間の分析
- 08.その他の適用例(概要)
- 09.今後の課題と方向性
- 10.AIネイティブなRANの実現に向けて
#AI-RAN #AI-for-RAN #Transformer
2025.10.01
ソフトバンク株式会社
Topicsトピック
※本記事の一部は、現在IEEEで査読中の原稿をもとに再構成しています。プレプリントはこちら
現行の5G/6Gでは、ヌメロロジーの切替、パイロット配置の変更、周波数帯の追加、高移動ユーザーや干渉条件の変化などにより、受信条件が短いスロット単位で変動します。従来の受信処理(同期 → チャネル推定 → 等化 → デマッピング → 復号)は、設計時に想定したチャネル統計・パイロット構成に依存しており、前提がずれるとブロックごとのチューニングや置き換えが必要になります。
このため、I/Q から統計的依存関係を直接学習し、前提変更に対して再実装なしで適応できる構成が望まれます。
まず、既存チェーンの個別ブロックを学習モデルで置き換えて効果を評価しました(詳細は2章)。その結果、次の技術課題が残ることが分かりました。
長距離依存のモデリング不足:CNNは固定サイズのカーネルで近傍(例:k×kk\times kk×k RE)しか参照できないため、周波数方向に広帯域・時間方向に複数シンボルへまたがる相関(マルチパス群、ドップラー、疎パイロット間の関係)が表現しにくい。
設計コストの増大:タスク(補間、推定、デマッピング等)ごとにアーキテクチャーや前後処理がばらつき、設計・チューニング・保守の工数が累積する。
Transformerを検討する前に、MWC2025で単一タスクの学習ベースラインを提示しました(図1)。
チャネル周波数補間 × CNN:非 AI 推定器に対して 上りスループット約 20% 向上。
SRS 予測 × MLP:80 km/h 条件で 下りスループット約 13% 向上(低速では利得縮小)。
これらは「AIをPHYに適用する価値」を示す一方、長距離依存の表現力やタスク横断の再利用性には課題が残ることを示しました。
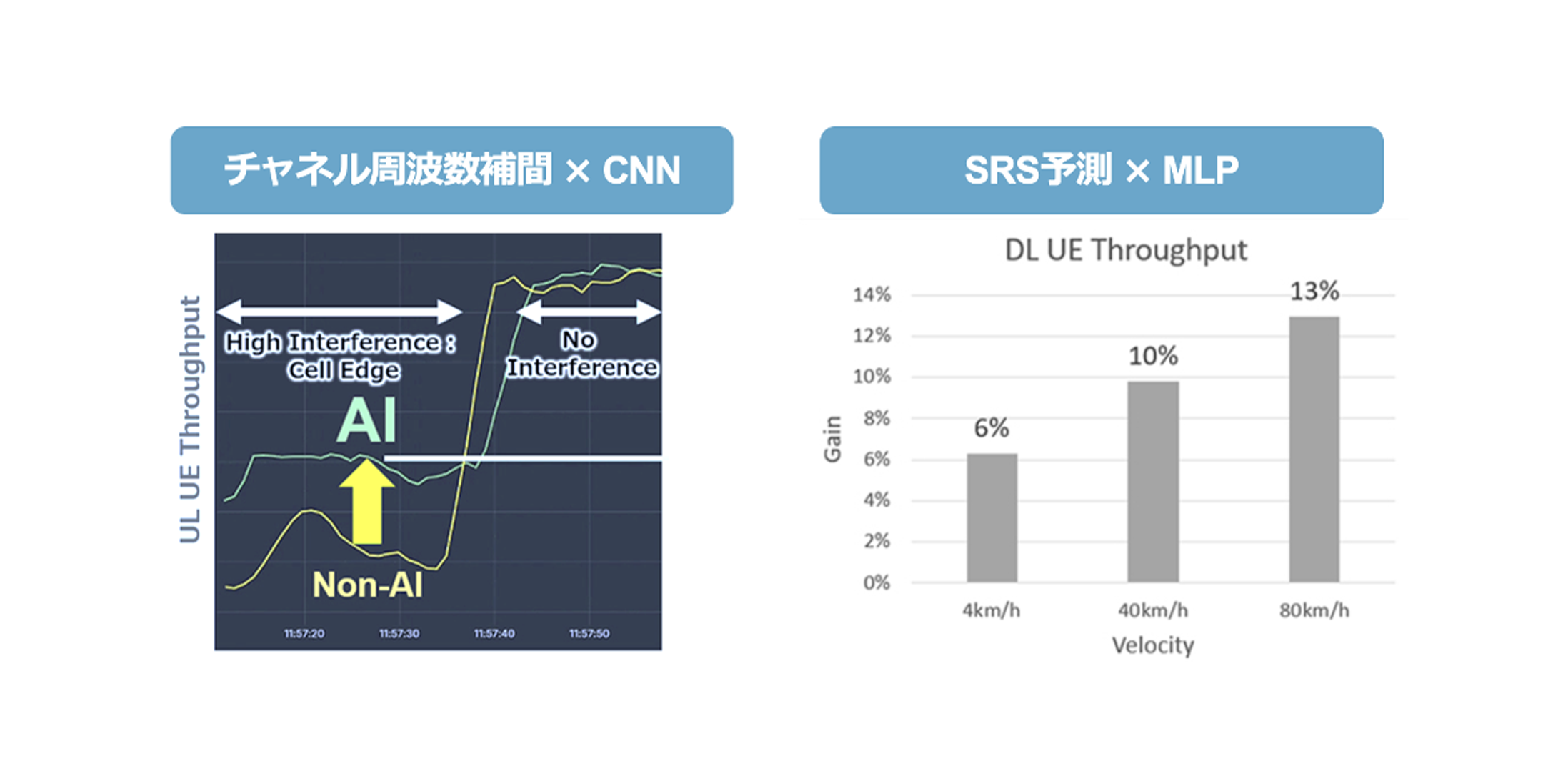
図1. MWC2025で提示した単一タスクのベースライン:CNNによる上りチャネル補間、MLPによるSRS予測。
CNN:受容野はカーネルサイズと段数で決まり、広い依存関係を扱うには層の深さや膨張率を上げる必要があります。これは計算量・レイテンシ・メモリの増加につながり、HARQ 期限(≒ 500µs)を満たすうえで制約となります。さらに、2D カーネルは時間・周波数・アンテナをまたぐ非局所的な相関の取り込みに限界があります。
Self-Attention:各REトークンが系列内の任意の地点を参照でき、遠距離の依存関係を少ない層で表現可能です。広帯域な周波数相関や、複数シンボルにまたがる時間的相関、アンテナ間の相関を同時に扱える点が、補間・予測タスクに適しています。
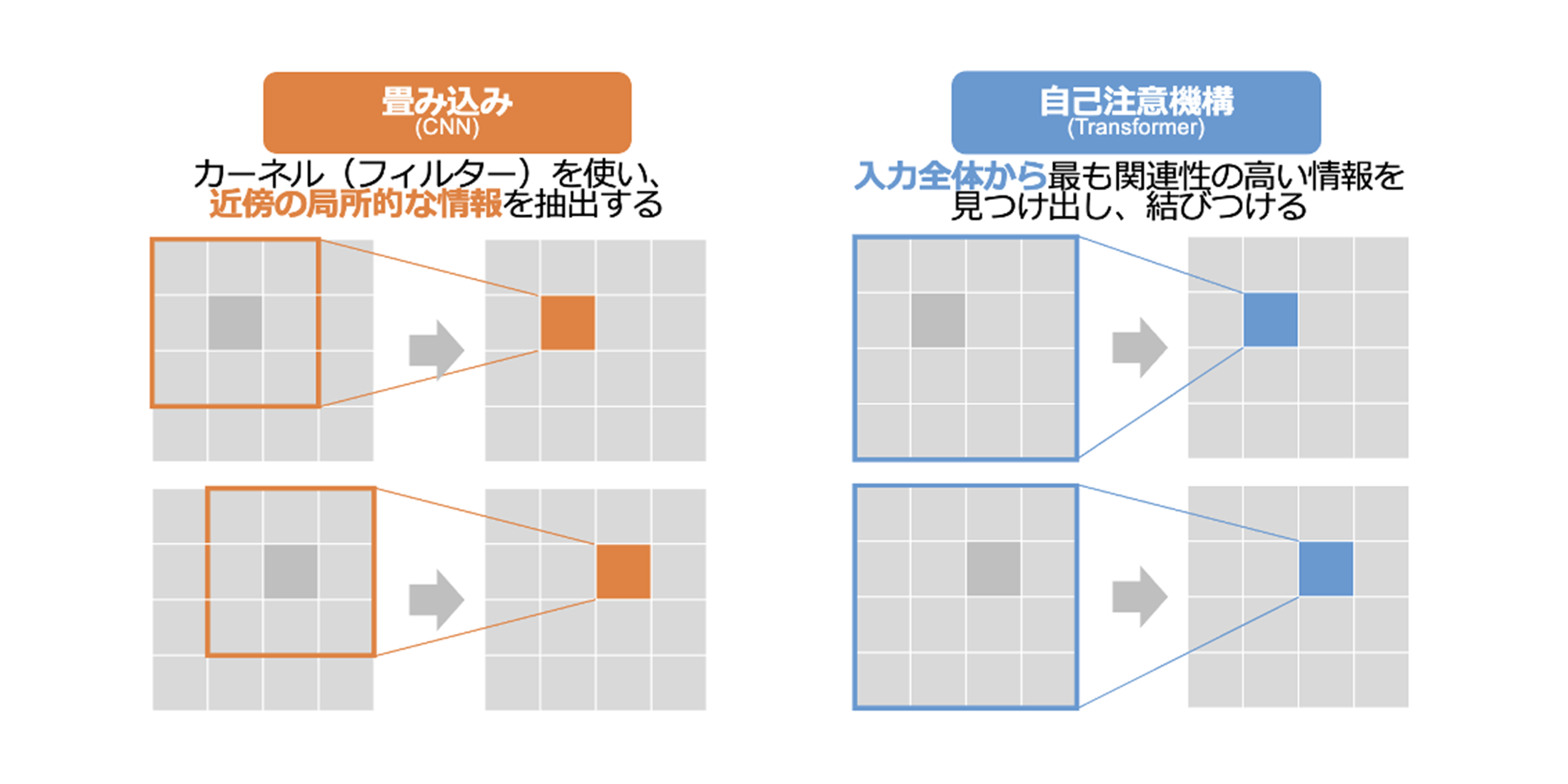
図2. CNN(局所参照)とSelf-Attention(全域参照)の違い。カーネル依存 vs. 任意トークン間のアテンション。
本研究では、タスクごとに学習・配備は独立しつつ、設計の型(Blueprint)を共通化します。原則は次の3点です。
時間×周波数×アンテナの各REを1トークンとして系列化し、必要に応じてアンテナ/UE ID、パイロットマスク等を付与。位置埋め込みで (subcarrier,symbol,antenna) を符号化し、2Dグリッド構造を保持。
効果:手作業の近傍設計に依存せず、非局所相関をモデリング可能。
多頭注意を少数層(例:4層・4ヘッド)で構成し、早い段の正規化は回避して振幅情報(チャネル再構成等で重要)を保持。
効果:深層化せずに長距離依存を表現し、レイテンシ/メモリの増大を抑制。
LayerNorm → 小規模FFN → 射影で、出力をタスクに合わせて整形(複素チャネル:補間/推定、LLR:デマッピング、スカラー:予測/スケジューリング等)。
効果:入出力仕様・埋め込み・実装方針を横断で共通化し、設計・検証コストを削減(※重みはタスクごとに学習・配備)
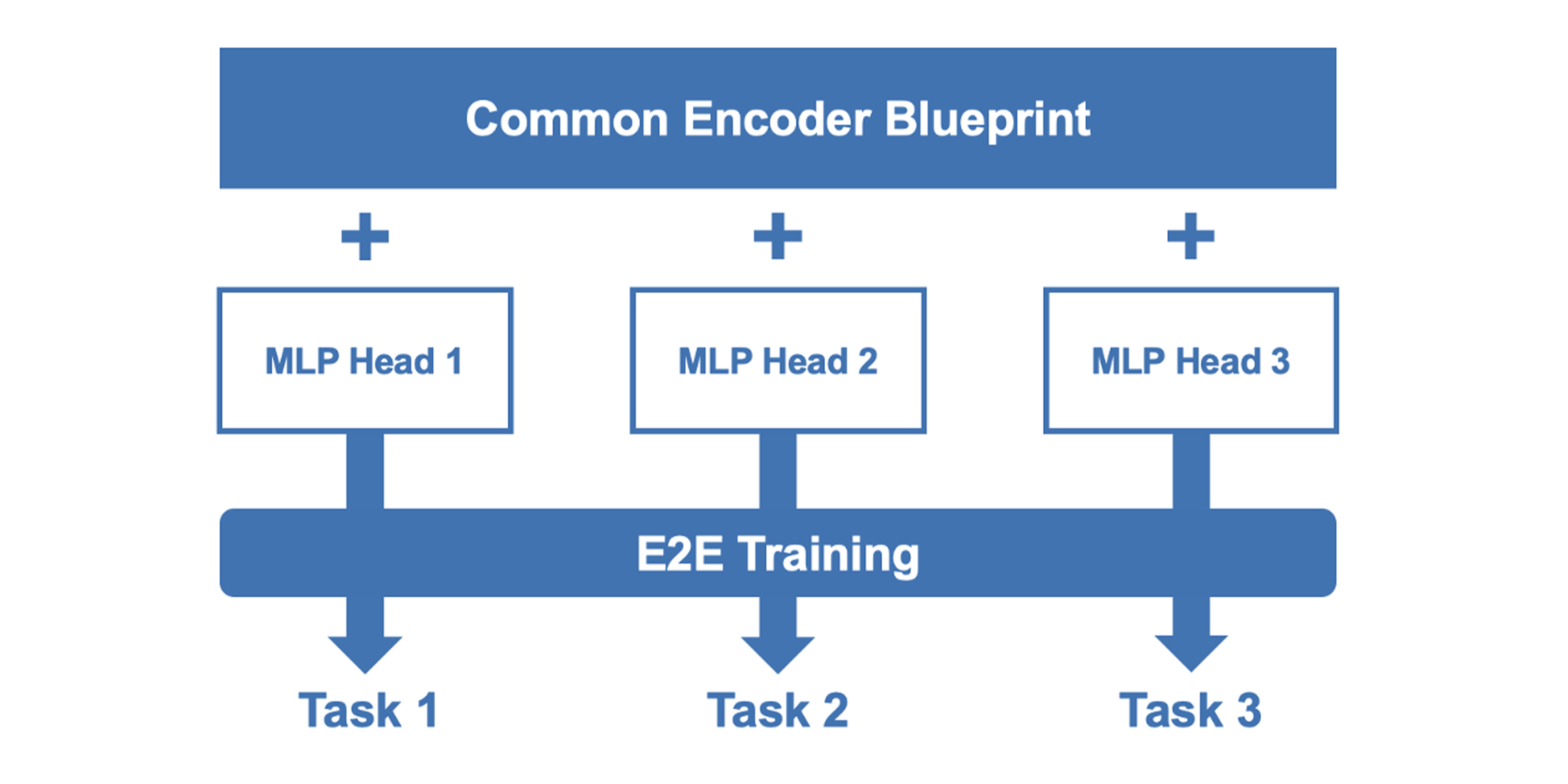
図3. Architecture Core 3:共通設計(エンコーダ+タスク別ヘッド)。重みはタスクごとに独立。
入力:上り PUSCH(データ+パイロット)やSRSなどのリソースグリッド。各REを実部・虚部(必要ならアンテナ/UE ID、パイロットマスク、予測ホライズン等)で表現し、トークン列に変換。
位置埋め込み: (subcarrier, symbol, antenna) をエンコードして、系列内に2D構造を反映。
エンコード:浅い Self-Attentionで系列全体の依存関係を取得。任意のRE間を直接参照できるため、時間・周波数・アンテナをまたぐ相関を少ない層で表現可能。
タスク出力:タスク別ヘッドで元のグリッド形状に復元し、複素チャネルグリッド(補間/推定)、LLR(デマッピング)、将来品質スコア(予測)などを出力。必要な後処理(例:ハード判定)は最小限。
備考:具体的なレイテンシ測定値や実装要件は7章(Latency & Implementation)に集約。
5G NRでは、チャネルはパイロットREにおいてのみ直接推定される。データREのチャネル値は推定結果から周波数方向に補間する必要がある。LMMSE 等の古典的手法や 2D-CNN は局所近傍に基づく推定が中心であり、パイロットが疎な場合や周波数選択性が強い環境では、広帯域の相関利用が不十分になりやすい。
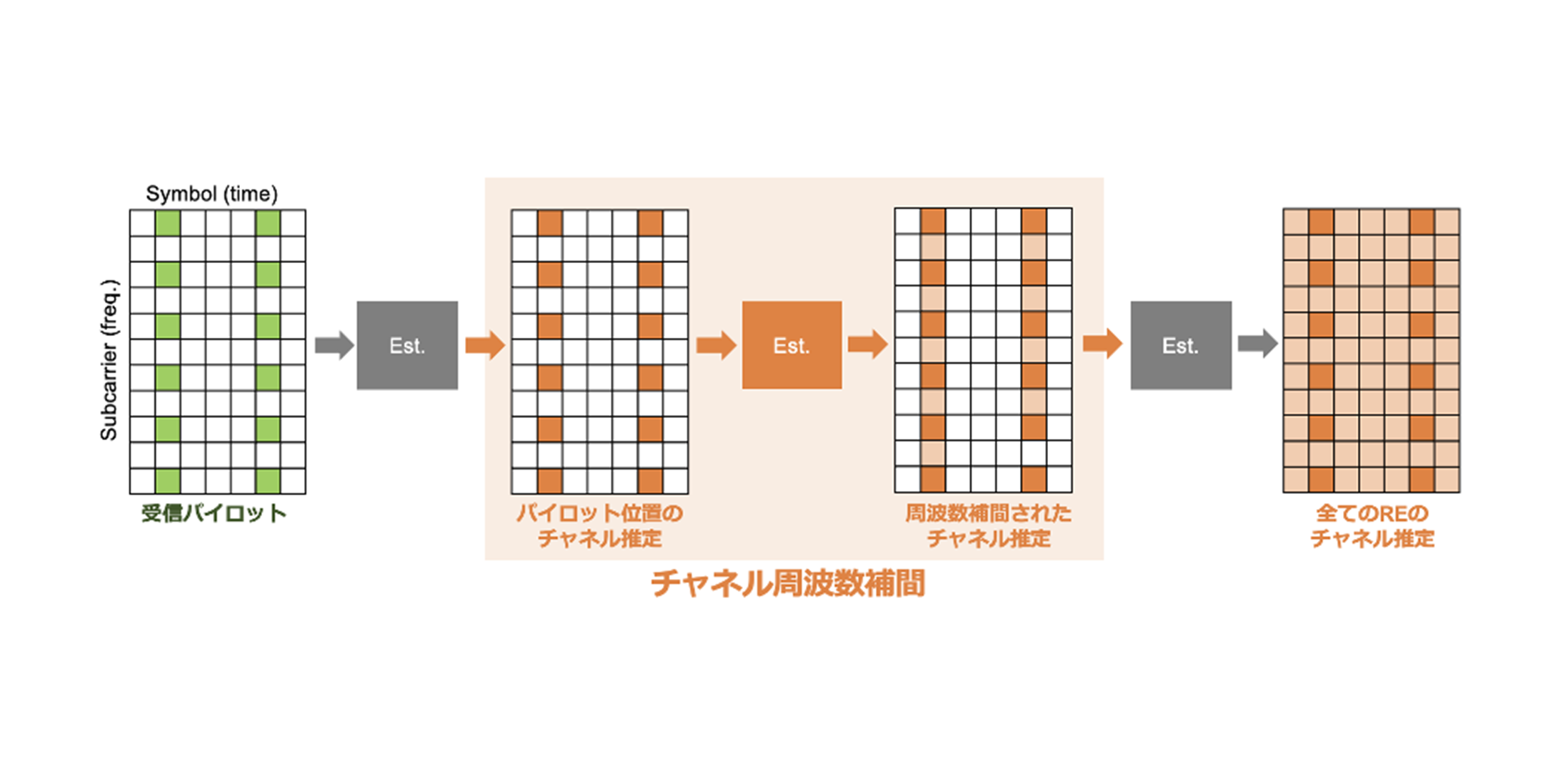
図4. 補間の模式図:パイロット(緑)と、データREに対する補間出力(橙)。
本Blueprintを補間タスクに適用する場合、入力は「パイロット位置のチャネル推定」「パイロットマスク(既知/未知の RE)」。エンコーダの自己注意により遠隔RE間の依存を取り込み、全帯域の複素チャネルグリッドを出力する。
100MHz(n78)構成のOTA計測において、Transformer補間器はLMMSE比 約30%、CNN補間器比 約8%の上りスループット改善を示した。干渉条件が変化しても中央値の上昇が確認できる。
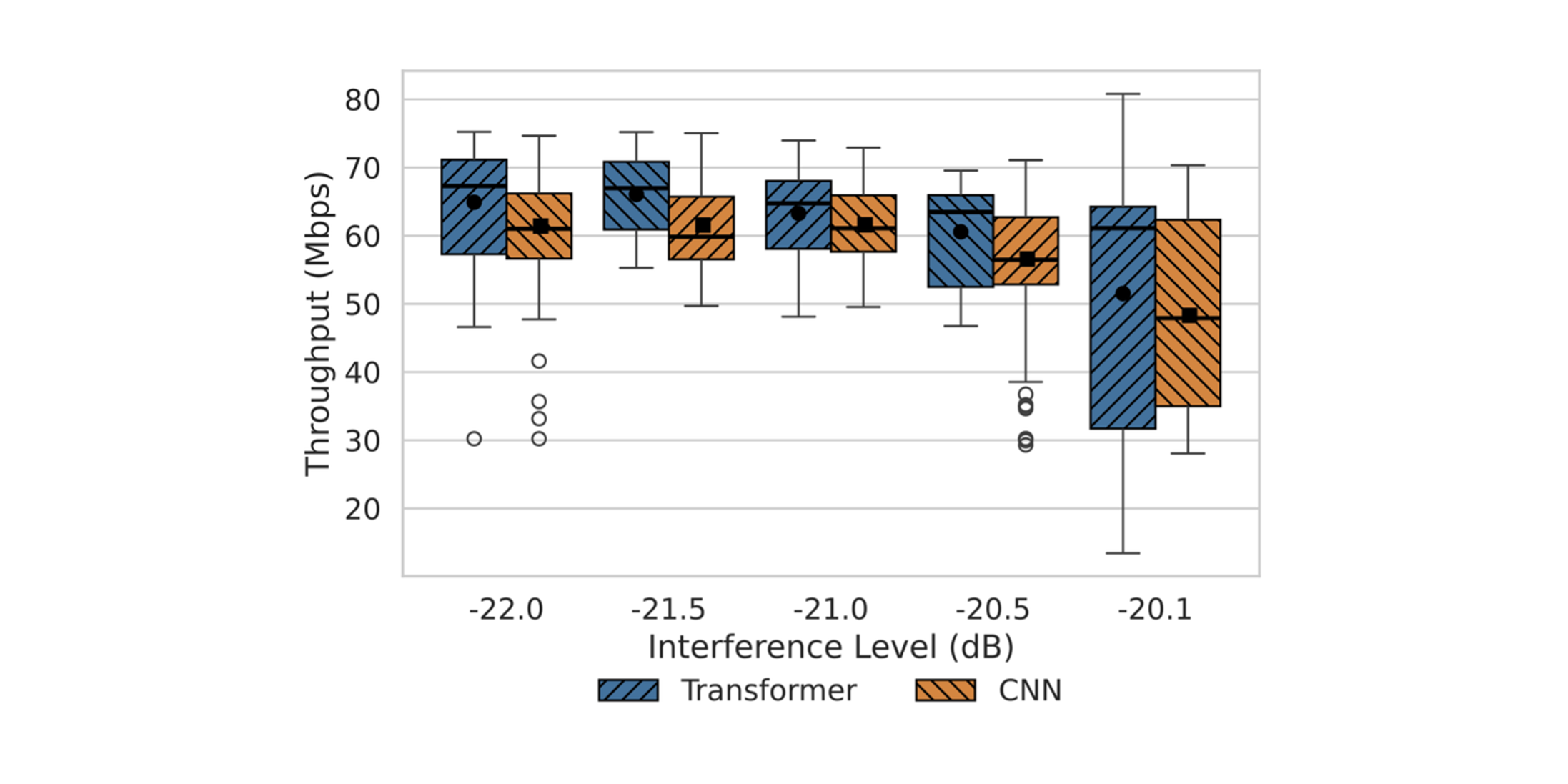
図5. 上りスループット(OTA):Transformer/CNN/LMMSE の比較(箱ひげ)。
UL側のSRS報告が途切れる状況(UL スケジューリングのギャップ、高速移動など)では、gNBは将来のDL側のビーム品質(例:CQI 相当)を推定し、ビームの維持・切替判断を行う必要がある。
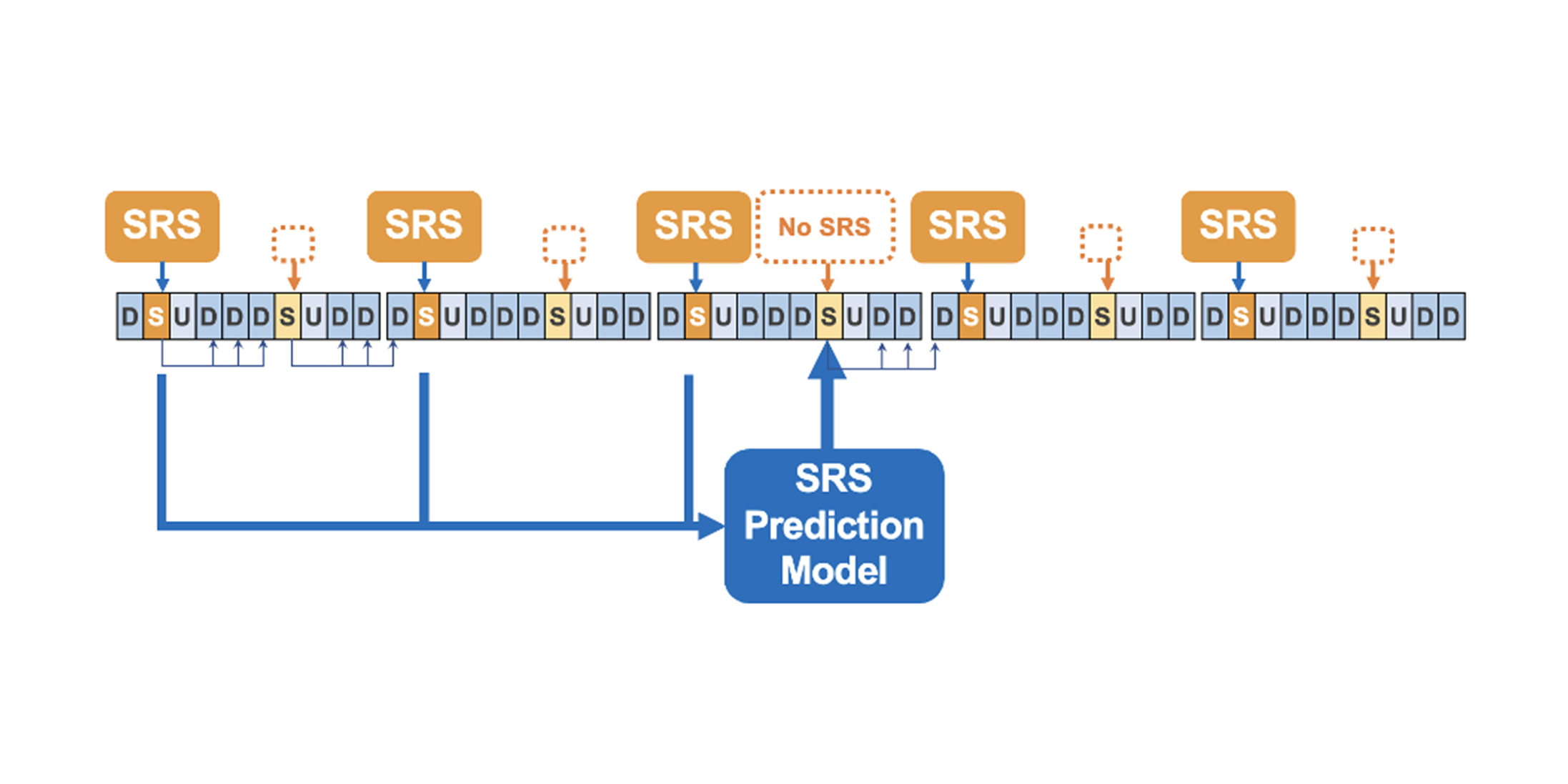
図6. SRS予測の問題設定:ULタイムライン上のSRS欠落区間と、gNBによる将来 チャネル予測。
本Blueprintのタスク別ヘッドを予測用に構成し、直近のULパイロット/SRS系列から所定ホライズンの将来品質スコアを推定する。自己注意により、複数シンボルにまたがる時間的依存を効率よく取り込める。
シミュレーションでは、80km/hで約29%、40km/hで約31%の下りスループット改善を確認。先行MLPの利得に対して約 2.2–3.1倍の改善幅となった。
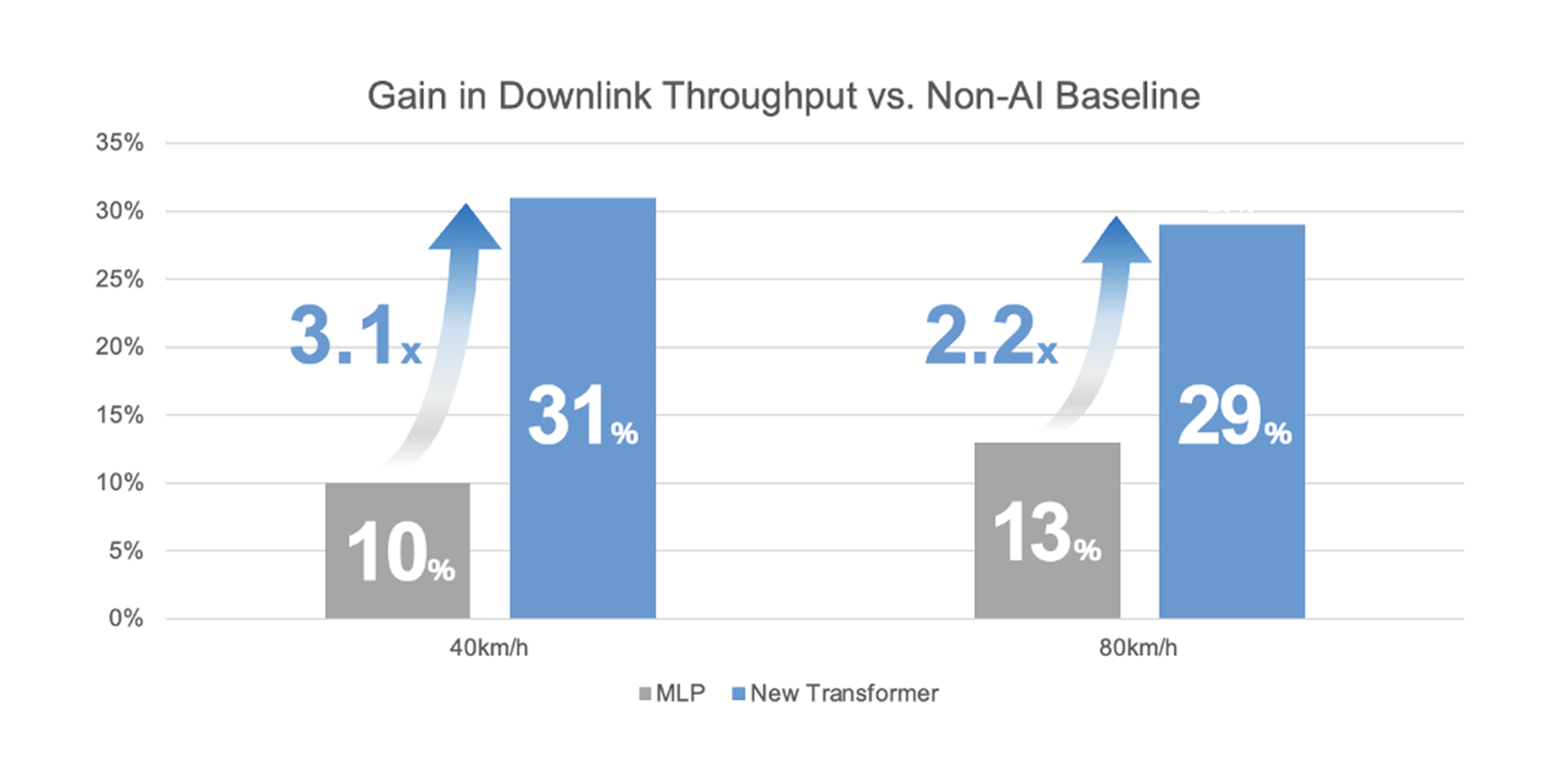
図7. SRS予測の利得(シミュレーション):TransformerとMLPの比較(40/80km/h)。
PHY処理の1スロット当たりの処理時間は約500µs以内であることが望ましい。
100MHz PUSCH(OTA)におけるエンドツーエンド処理時間は、NVIDIA GH200上で約337µs。CNNベース実装に対して約1.36倍高速であり、リアルタイム要件を満たす。
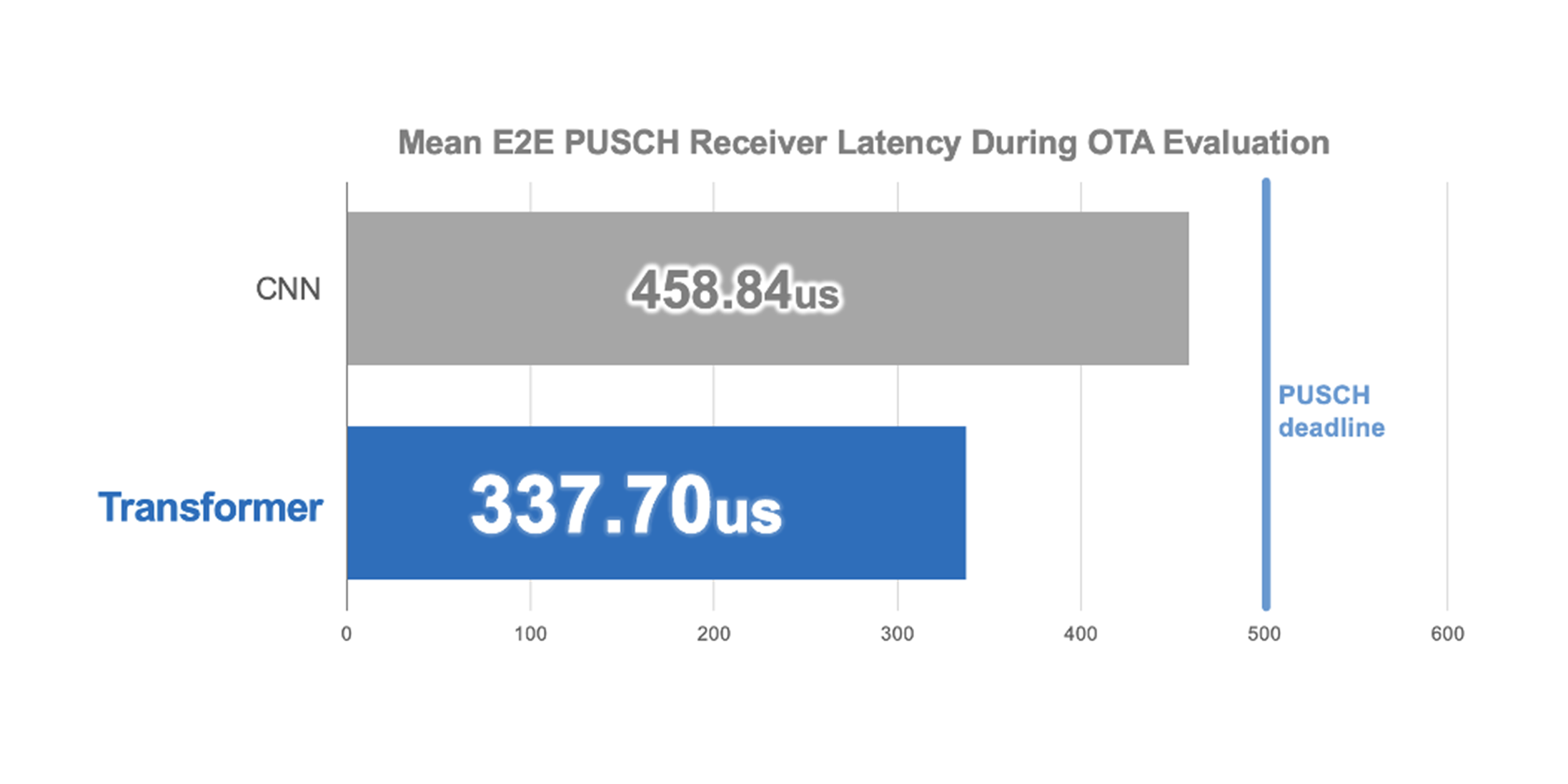
図8. エンドツーエンド遅延(OTA):TransformerとCNNの平均比較。
モデルを軽量化しても、CPU単体では推論時間が500µsに達しやすい。
NVIDIA H100上では、チャネル補間推論が約0.205msで完了。リアルタイム要件を満たすため、GPU(または専用AIアクセラレータ)の活用が実運用上ほぼ必須となる。
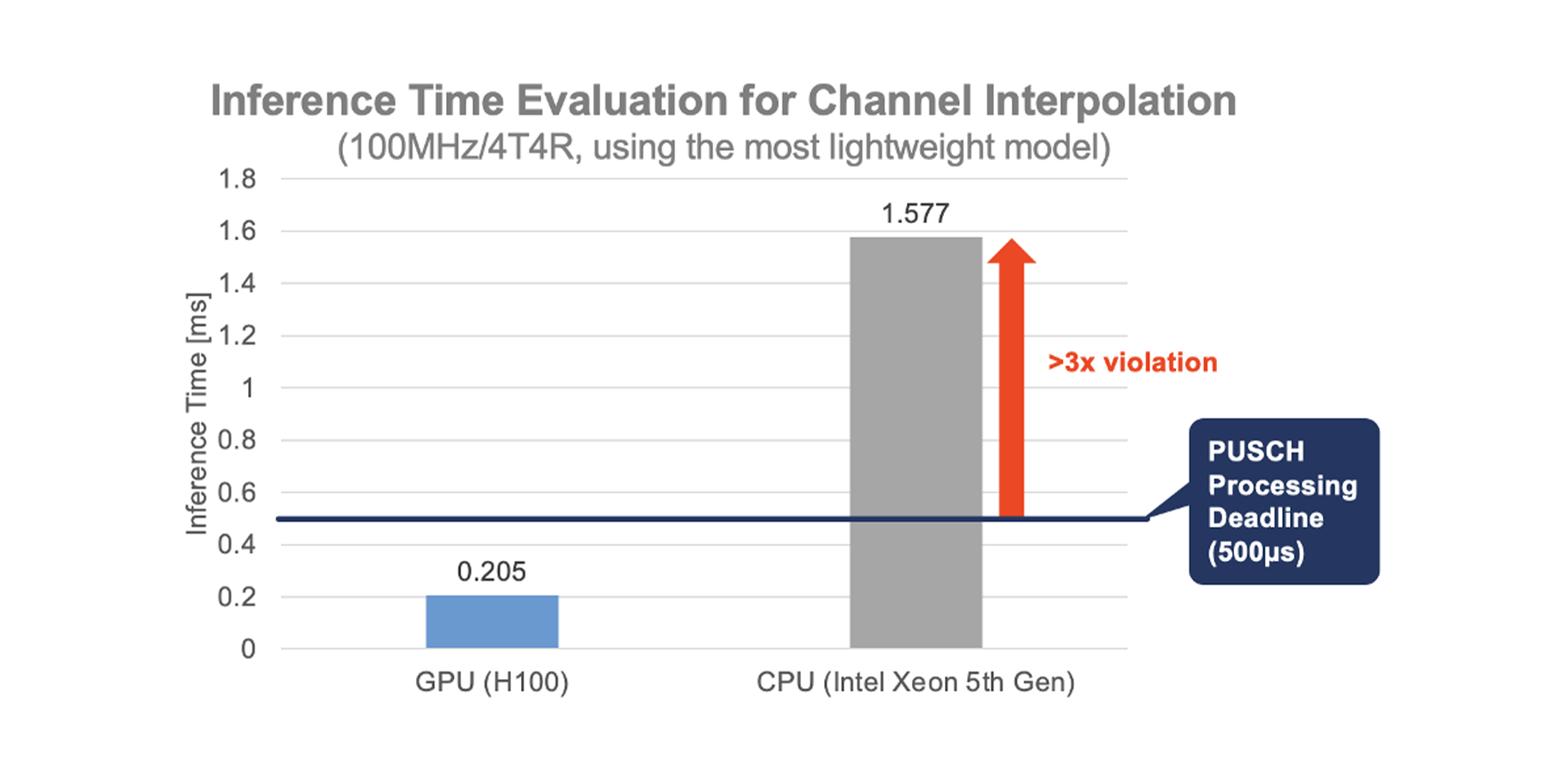
図9. 推論時間比較:GPU(H100)とCPU(Xeon)によるチャネル補間。
End-to-End受信:タスク別ヘッドでLLRを直接出力し、推定→等化→デマッピングの一体最適化を図る。BLERを抑えつつ、レイテンシ制約を満たす構成が可能。
フルバンド推定:疎なパイロット配置から帯域全体のチャネルを再構成。CNNベース推定器と比較して精度面の優位を確認。
クロスレイヤタスク:MU ペアリング等の無線資源管理におけるスコアリングへ展開。
タスク拡張:本稿の2タスク(補間/SRS予測)から、スケジューリングやリソース割当などクロスレイヤ機能への拡大。
効率化とスケール:位置埋め込みの再検討、モデル圧縮・早期終了などにより、精度–遅延–電力のトレードオフを最適化。基地局・エッジでの運用を現実解に。
ロバスト性と検証:高ドップラー・急峻なフェージングへの対応強化、3GPP準拠のシステムレベル評価の前進。
解釈性と標準化:注意重みの可視化をパイロット設計やデバッグに還元しつつ、標準化に向けた議論を継続。
本稿では、attentionを用いた信号処理がOTA(Over-the-Air)でスロット時間内に動作しうること、そしてTransformerの再利用可能な設計テンプレート(RE〈Resource Element〉トークン化、浅い自己注意エンコーダ、タスク別(重み共有なし)のヘッド)が実際の RAN タスクに素直に当てはまることを示しました。例として チャネル周波数補間(OTA)と SRS予測(シミュレーション)を取り上げ、I/Oの約束事や実行予算(runtime envelope)、アクセラレータ級(GPU等)を前提とした推論の必要性といった実装面の論点も整理しています。
今後は3GPP整合の評価を広げつつ、効率化(圧縮、早期終了、ニューメラロジーに頑健な埋め込み)を進め、スケジューリングやRRMへの統合を拡張していきます。論文・講演・ベンダー/アカデミアとの協業を通じて、うまくいった点も課題も継続的に共有し、AIネイティブなRANの実現に向けて着実に前進していきます。