Contents
- Blog
- 無線, ネットワーク, コンピューティング
AMD Instinct™ GPUアーキテクチャーとAIアプリケーションに応じた制御手法
#AI-RAN #AI #AMD #GPU
2026.02.16
ソフトバンク株式会社

Topicsトピック
本記事では、ソフトバンク先端技術研究所(以下先端技術研究所)がAdvanced Micro Devices, Inc.(以下「AMD」)と連携して開始した共同検証の一環として、AMD Instinct™ GPUのGPU Partitioning機能を活用し、当社が開発を進めるオーケストレーターを拡張することで、AIアプリケーションの要件に応じたGPU割り当てを最適化する取り組みを紹介します。
1. 背景:推論サービス運用とGPUリソースの課題
生成AIの活用が進む中、LLMなどのAIモデルを利用するアプリケーション需要は拡大を続けています。先端技術研究所はこの需要に応えるため、AIアプリケーションのモデル規模や実行要件に応じて計算資源を柔軟に制御できる次世代のAIインフラの実現を目指し、計算資源の管理やAIアプリケーションの最適な配分を行うオーケストレーターの開発を進めてきました。
推論サービスはLLMモデルの規模、同時に実行するモデル数といった用途やアクセス数により、必要となるGPUのリソース量が常に変動します。また、GPUは高価な計算資源であり、サービス提供者は限られたGPUを複数の用途、複数のモデルに割り当てながら運用する必要があります。
このとき、需要の変動に対して割り当ての粒度を細かく調整できないと、小さいモデルに対して必要以上に大きなGPUを割り当ててしまうなど、リソースのミスマッチが起こりやすくなります。結果として、GPUの一部が使われない状態(余剰)が生じ、必要なタイミングで大きなモデル、あるいは複数の小さなモデルに対して容量を確保できず、処理待ちや起動遅延の発生につながります。このように、余剰は単に「無駄」になるだけでなく、需要の増減に応じた柔軟なサービス提供を難しくする要因にもなります。
こうした背景から、サービス提供者にとっては、AIアプリケーションのモデル規模や同時実行要件などに応じてGPUリソースを“必要な分だけ”割り当てることが重要です。需要の変動に合わせて割り当てを最適に調整できれば、余剰を抑えながらひっ迫も避けやすくなり、稼働率・提供効率・サービス品質の向上に繋がります。
2. なぜAMD Instinct™ GPUなのか:GPUを“分割して使う”という選択肢
前章で述べた余剰を抑え、設備稼働率と提供効率を高めるためのアプローチの一つが、GPUを用途に応じて分割して利用するという考え方です。
AMD InstinctTM GPUは、大容量のHBM※を持ち、GPUリソースを分割して扱える仕組み(GPU Partitioning)を備えており、必要に応じて1台のGPUを複数の区画(論理デバイス)として利用できます。これにより、推論サービスごとに「必要な分だけ」のGPUリソースを割り当て、1台のGPU上で複数の推論サービスを並行して展開することで、余剰リソースの発生を抑えることができます。結果として、限られたGPUをより細かな単位で利用できるようになり、需要変動の大きい環境でも運用の選択肢が広がります。
※MI300X:HBM3 192GB, MI325X:HBM3e 256GB, MI355X/MI350X:HBM3e 288GB

図1. AMD InstinctTM GPUのCompute Partitioning
AMD InstinctTM GPUは、計算処理を担う”演算リソース”と、”メモリ構成”という、2つの観点で論理的な構成が定義されています。具体的には、GPUの演算リソースを構成するXCD(Accelerator Complex Die)を分割単位とするCompute Partitioning(図1)と、GPU Instanceから見えるメモリ構成を制御するNPS(NUMA Per Socket)を分割単位とするMemory Partitioning(表1)が用意されています。GPU Partitioningでは、これら2つの観点に基づき、Compute側とMemory側のそれぞれで分割設定を行い、それらを組み合わせることで1つの物理GPUを複数の論理GPU(GPU Instances)として利用します。
Compute Partitioningの分割モードは SPX/DPX/QPX/CPX が存在し、1枚のAMD InstinctTM GPUをそれぞれ1/2/4/8個のGPU Instancesとして切り出すことができます。
Memory Partitioning(NPS)は、HBMメモリのメモリ領域を変更し、GPU Instanceがアクセスするメモリを制御する機能です。NPS1/NPS2/NPS4/NPS8 が定義されており、これにより各GPU Instanceが使うメモリ領域を最適に配置し、メモリアクセスを高速にします。
これら2種類のパーティショニングは「Memory側の分割数はCompute側の分割数を超えない」という制約のもとで、あらかじめ定義された互換性に基づいて設定されます。(以下表1参照)
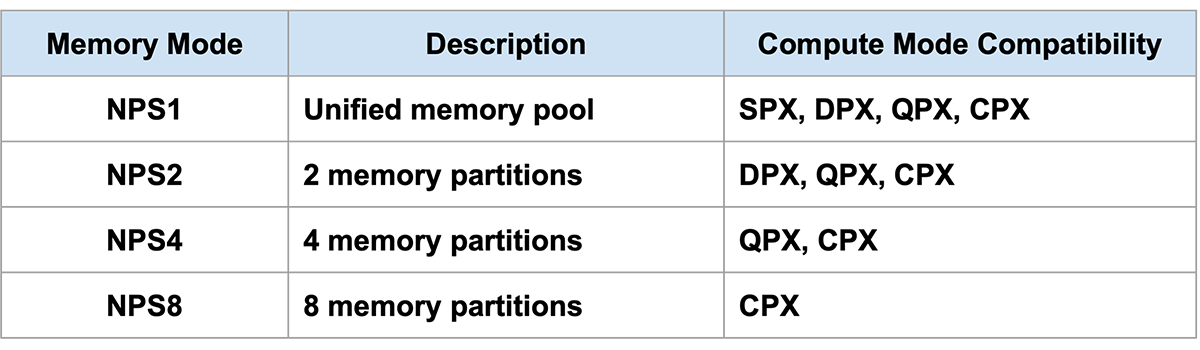
表1. AMD InstinctTM GPUのMemory Partitioning
このように、Compute PartitioningとMemory Partitioningを組み合わせてGPU Instanceを構成することで、モデル規模や用途に合わせてGPUリソースを“必要な分だけ”割り当て、運用効率を高めることが可能になります。
3. 今回の取り組み:オーケストレーターによるGPU制御とアプリケーションのデプロイ
先端技術研究所が開発中のオーケストレーターは、AIアプリケーションのデプロイ要求を受け取り、推論サービスの起動まで自動化する役割を担っています。本取り組みでは、このオーケストレーターにAMD Instinct™ GPUが備えるGPU Partitioning 機能を組み合わせることで、ノード内のGPUリソースをAIモデルの要件に応じて動的に分割・割り当てを行い、推論サービスを起動できる仕組みを実装しました。
本記事では、ノード内におけるGPUリソースの分割および割り当て制御に焦点を当てて説明します。なお、配置先ノードの選定については、従来のスケジューリング機構にゆだねています。
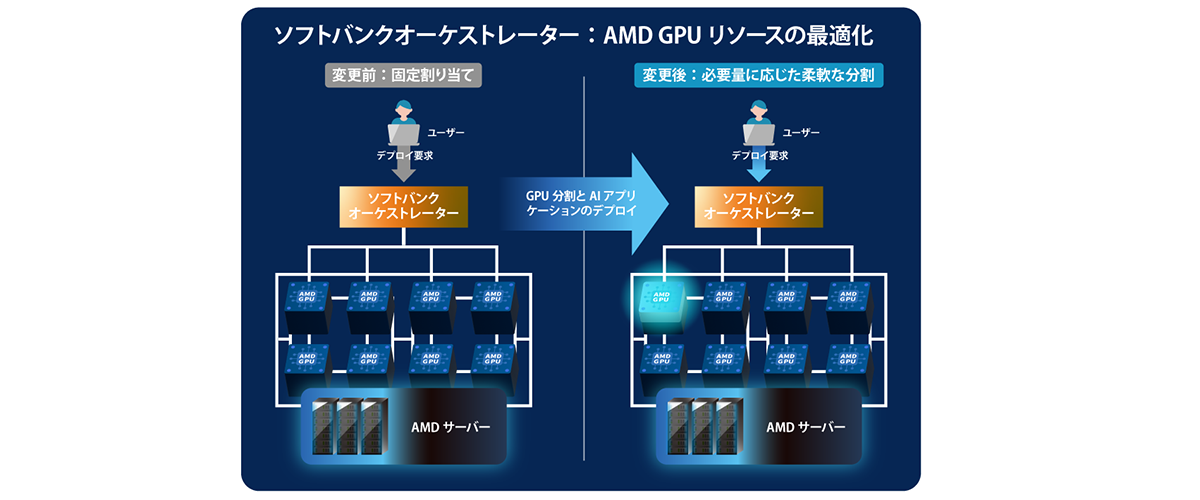
図2. デプロイ要求に対するGPU割り当ての流れ
4. 「分割 → 割当 → 起動」の制御シーケンス
以下は、オーケストレーターがAIアプリケーションのデプロイ要求を受けてから、推論サービスを起動するまでの一連の流れです。
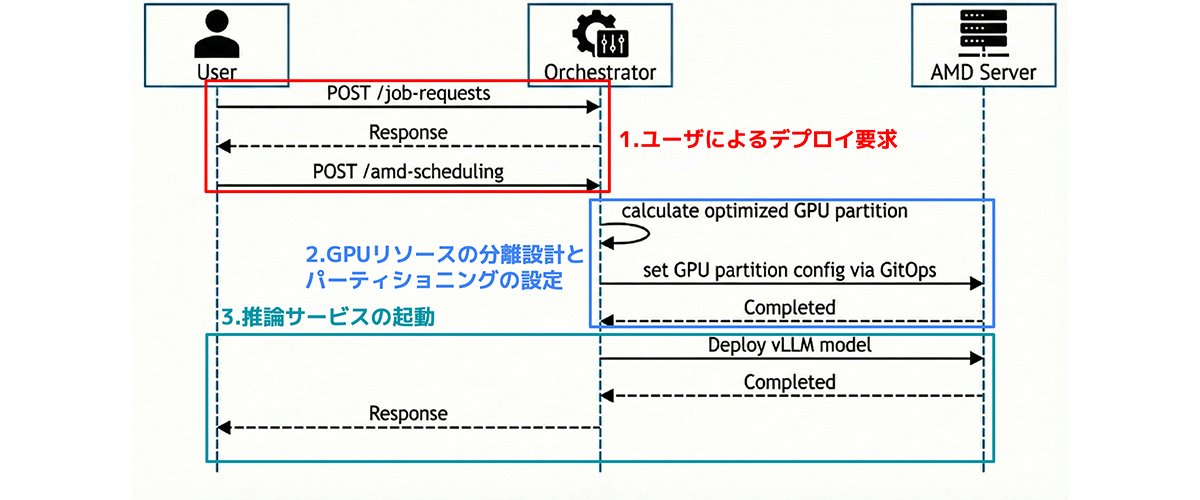
図3. オーケストレーターによる制御のシーケンス図
1. ユーザーによるデプロイ要求
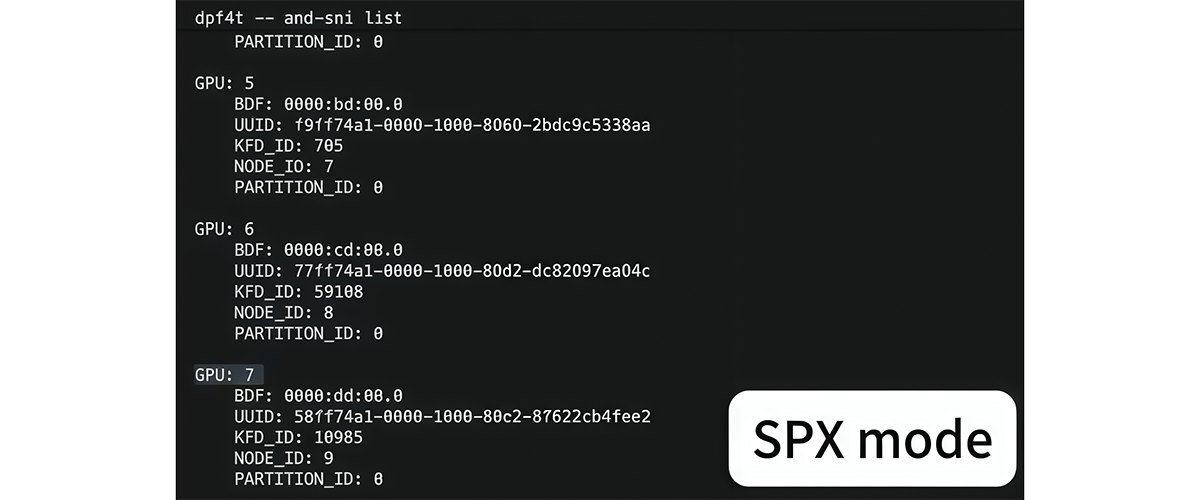
AIアプリケーションから、特定のAIモデル(本検証でLlama-3.1-8B-Instruct)を用いた推論サービスのデプロイ要求がオーケストレーターに送信されます。
この時点では、サーバー(ノード)上のAMD InstinctTM GPUはすべてSPXモードで動作しており、’amd-smi list’ではGPU ID 0〜7の8個がインスタンスとして認識されています。
2. ノード内GPUリソースの分割設計とパーティショニング実行
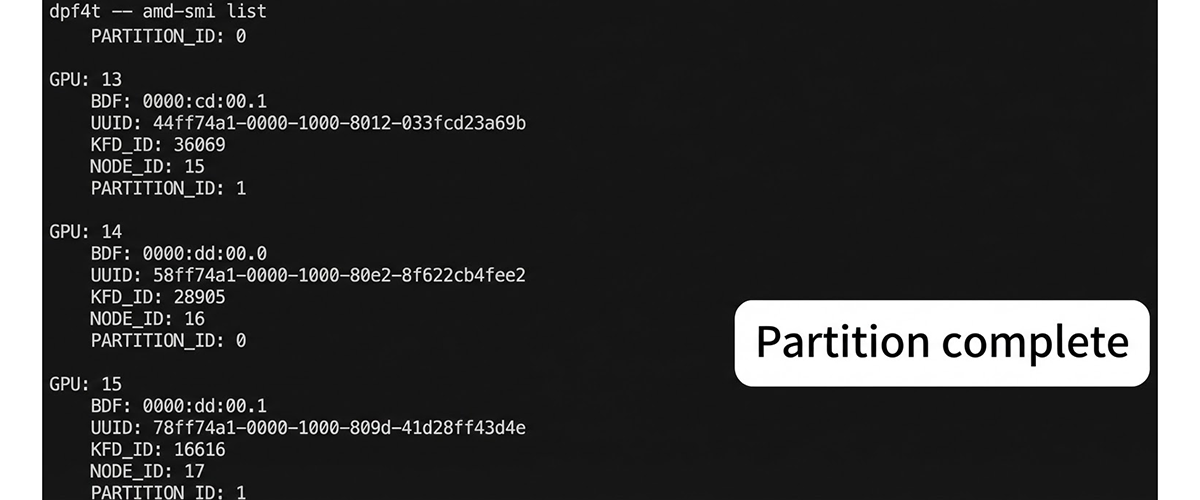
オーケストレーターは、モデル要件に基づき、ノード内で必要となるGPUリソースのサイズを決定します。今回は、より小さなGPU単位での割り当てを行うため、GPU Partitioningを適用します。
この制御により、ノード内のすべてのAMD InstinctTM GPUはDPXモードに論理分割され、’amd-smi list’ではGPU ID 0〜15の16個がインスタンスとして認識される状態へと遷移します。
3. 推論サービスの起動
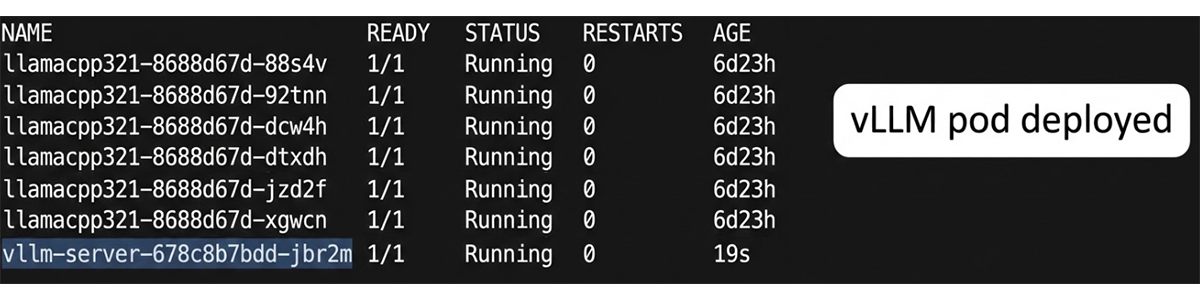

GPUリソースの分割が完了した後、オーケストレーターは必要なGPU Instanceを推論サービスに割り当て、推論コンテナを起動します。
この結果、vLLMのPodが起動し、Compute(XCD)およびMemory(NPS)がそれぞれ適切にパーティショニングされた状態で、推論サービスが稼働していることを確認できます。
このようなリソースによる最適なパーティショニングを行うことによって、合理的かつ効率的に使用できるようになっています。
5. 今後の活用に向けたGPU資源配分の高度化
先端技術研究所は生成AIの利用が広がり、推論をはじめとするAIアプリケーションの要求が多様化する状況を踏まえ、次世代のAIインフラの実現に向けた技術検証を進めています。
推論サービスではモデル規模や同時実行数に加え、コンテキスト長や負荷変動などによって必要な計算・メモリ資源が異なるため、GPUを固定的に割り当てる運用では余剰やひっ迫が発生しやすいことが課題になります。そこで先端技術研究所はAMDと連携し、AMD Instinct™ GPUが備えるGPU Partitioning機能を活用して、オーケストレーターから要件に応じたGPU分割と最適割り当てを行い、「分割→割当→起動」までを一連でつなぐ制御機構の開発・検証を行いました。
今後は中・小規模モデルの活用拡大も見据えながら、GPU Partitioning等の特徴を活かした最適な資源配分をさらに高度化し、将来的にはさまざまなAIアクセラレーターに対しても同様の考え方でオーケストレーターによって最適化できるよう、柔軟なリソース制御を模索していきます。