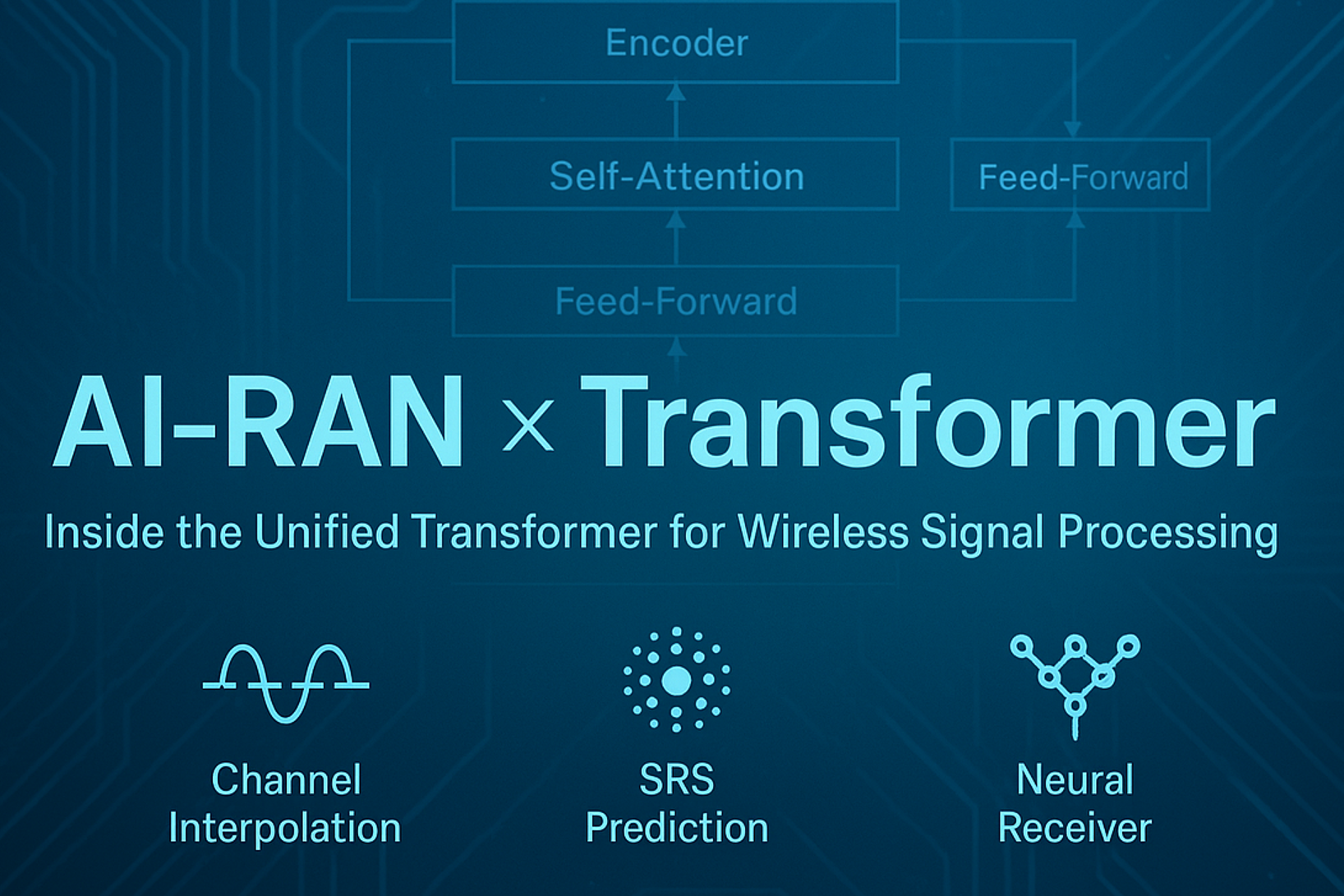
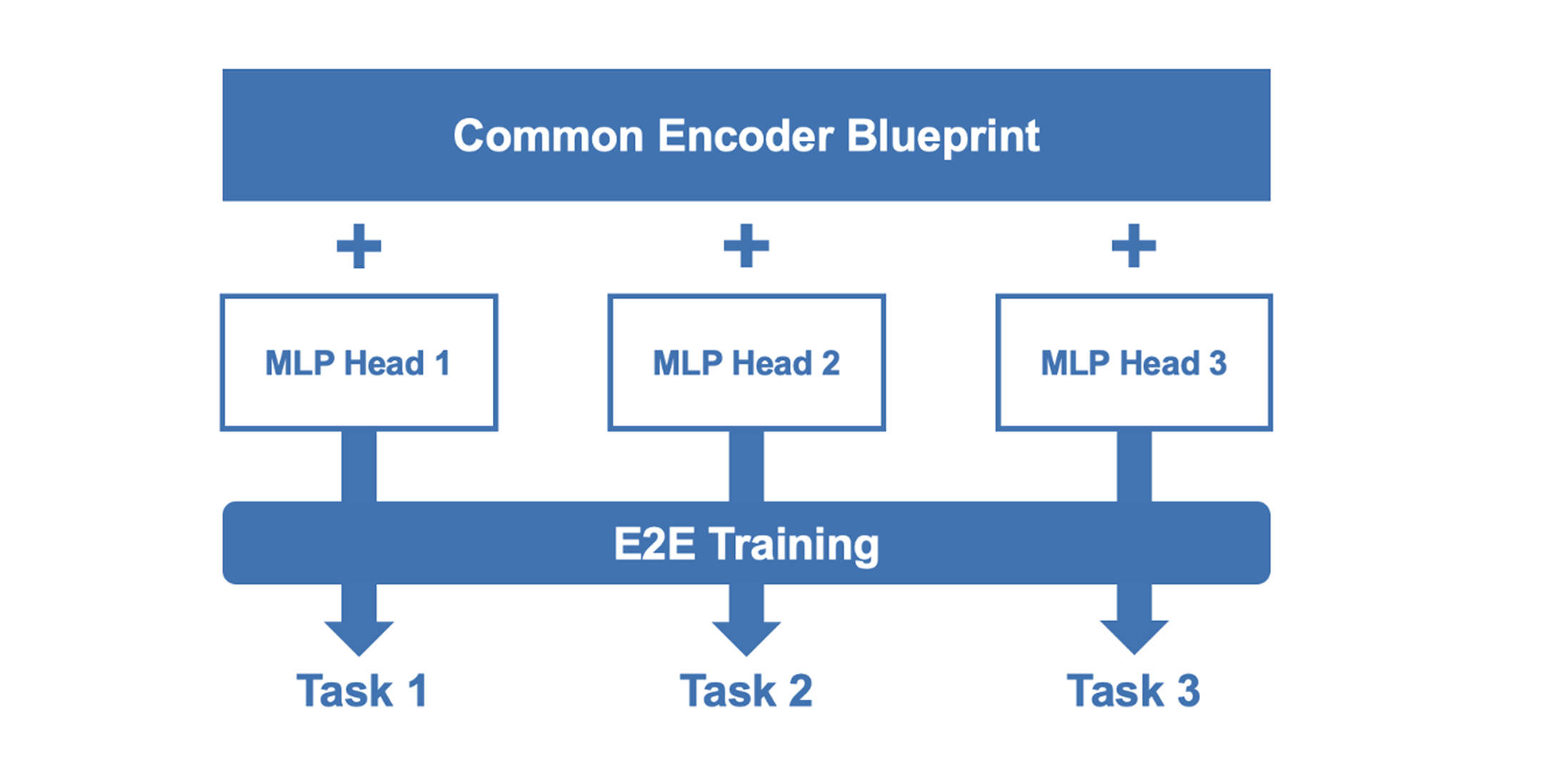
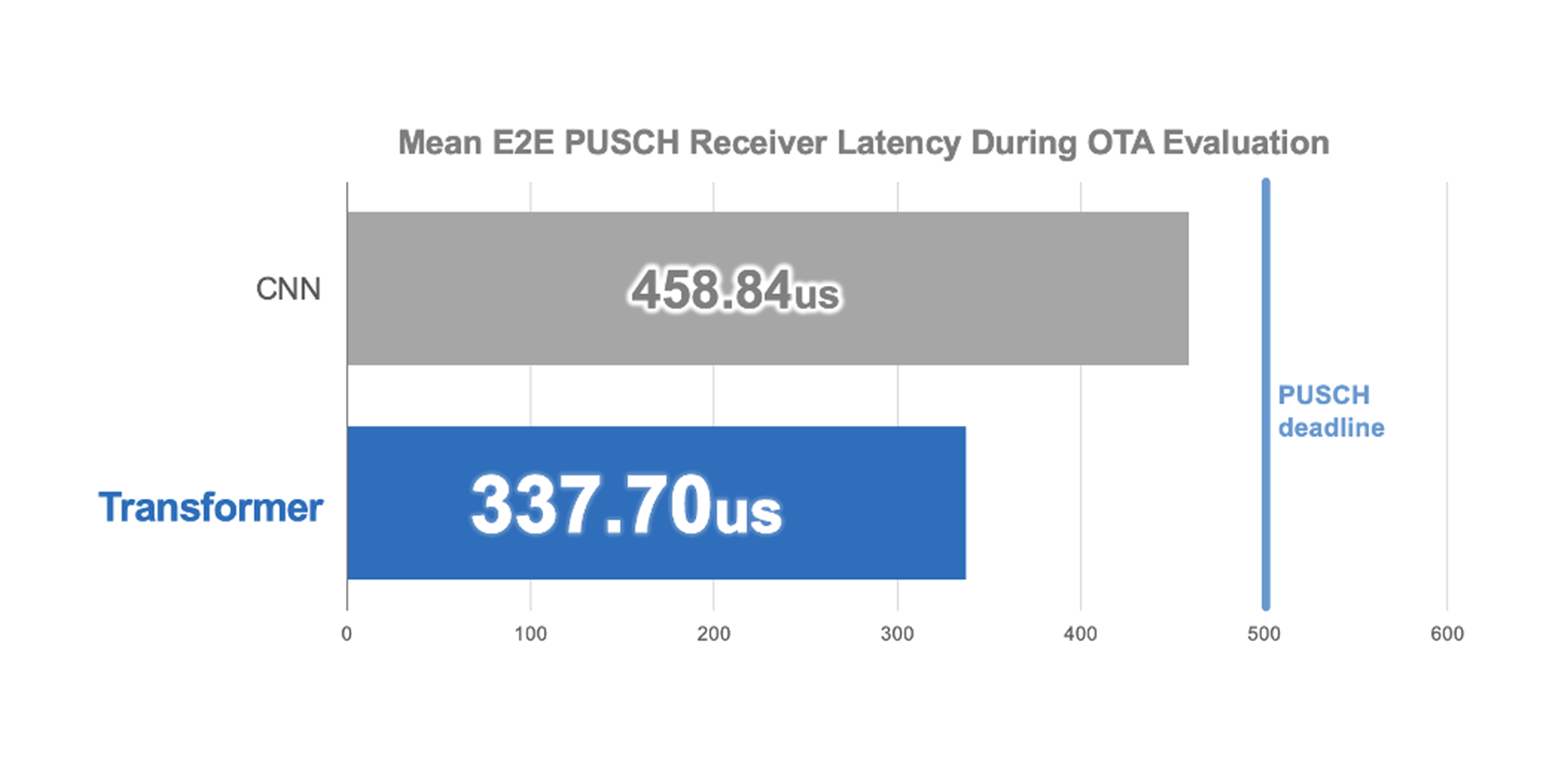
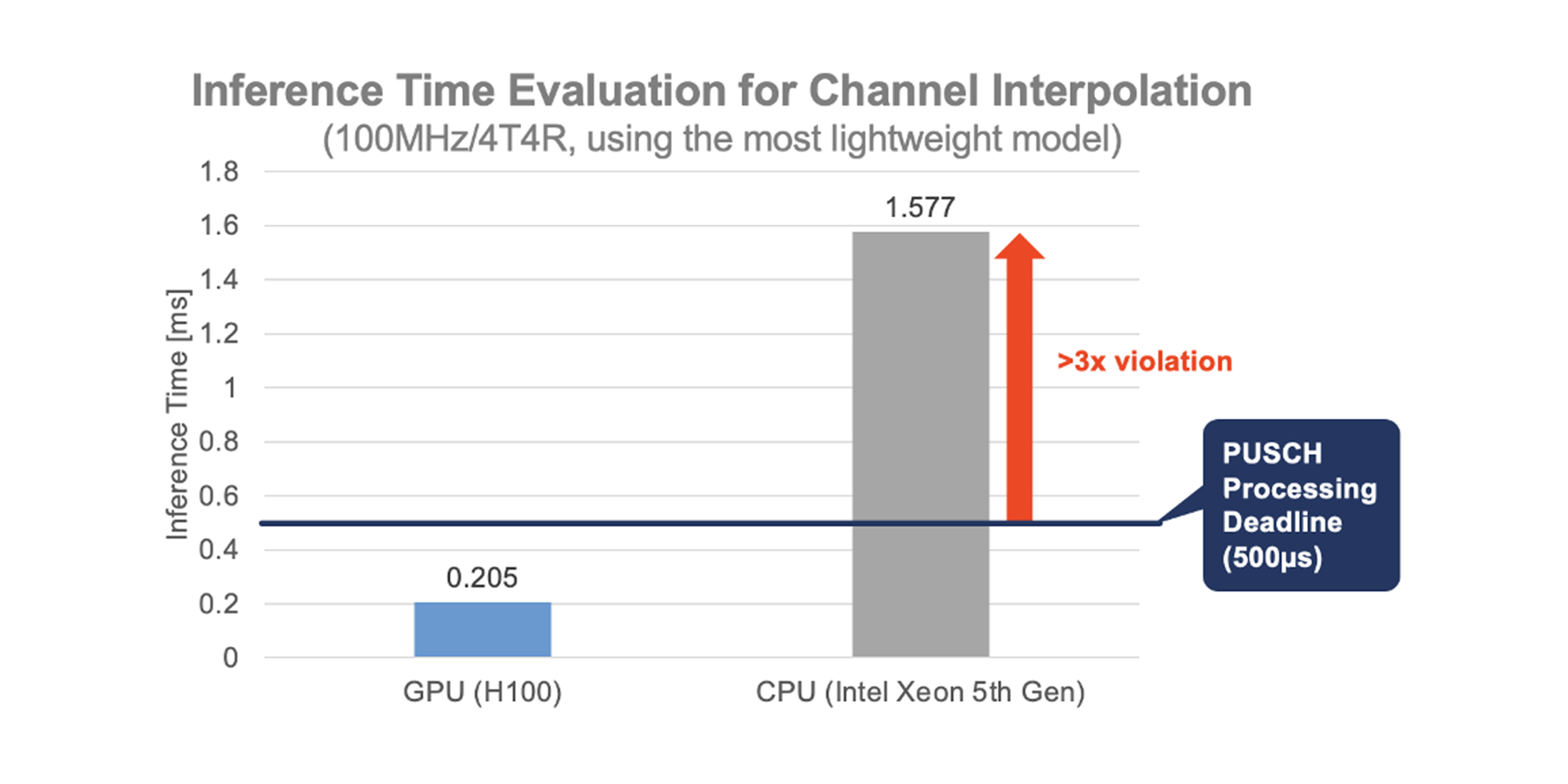
6. Featured Use Cases
6.1 Channel Frequency Interpolation
Problem
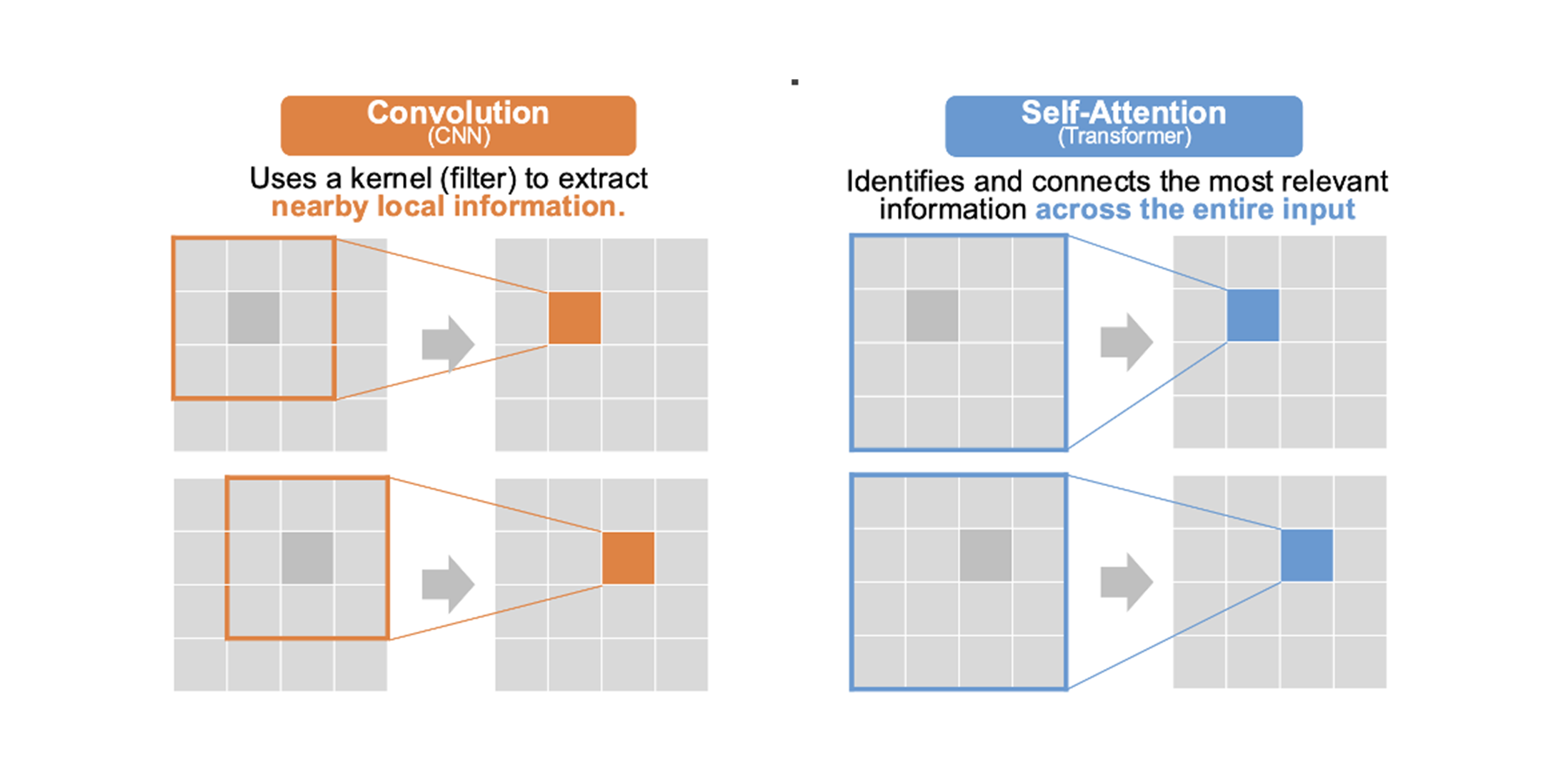
In 5G, channels are directly observed only at pilot REs; values at data REs must be inferred. Classical interpolators (e.g., LMMSE) or 2D CNNs rely on local neighborhoods and may underuse far-apart pilot information.
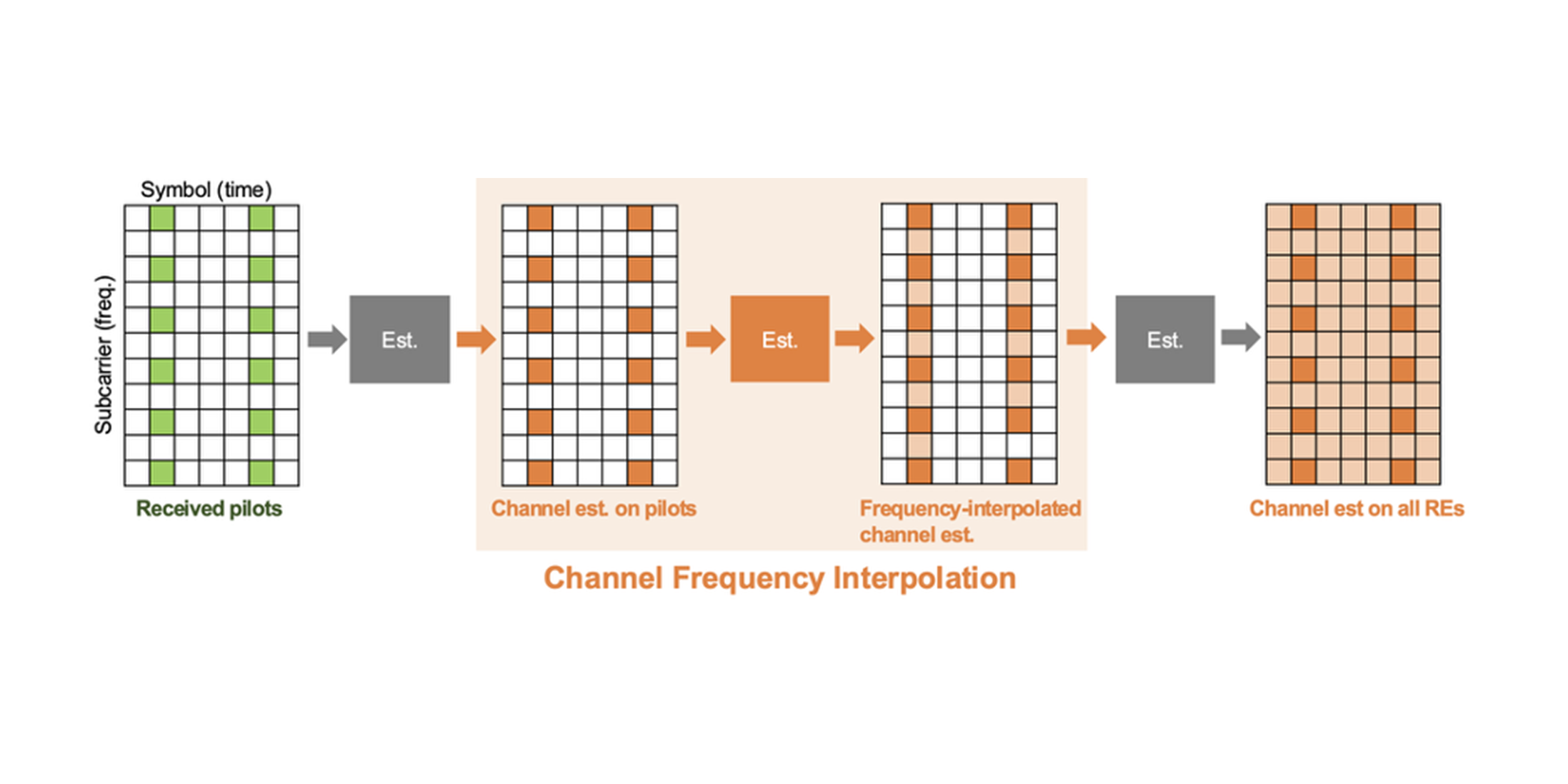
Fig. 4 — Channel-interpolation sketch: pilots (green) and predicted values at data REs (orange).
Approach
Instantiate the blueprint for interpolation: feed pilot estimates and a pilot mask; output a complex channel grid across the full band. Self-attention exploits long-range correlations across subcarriers and symbols that local kernels miss.
Results
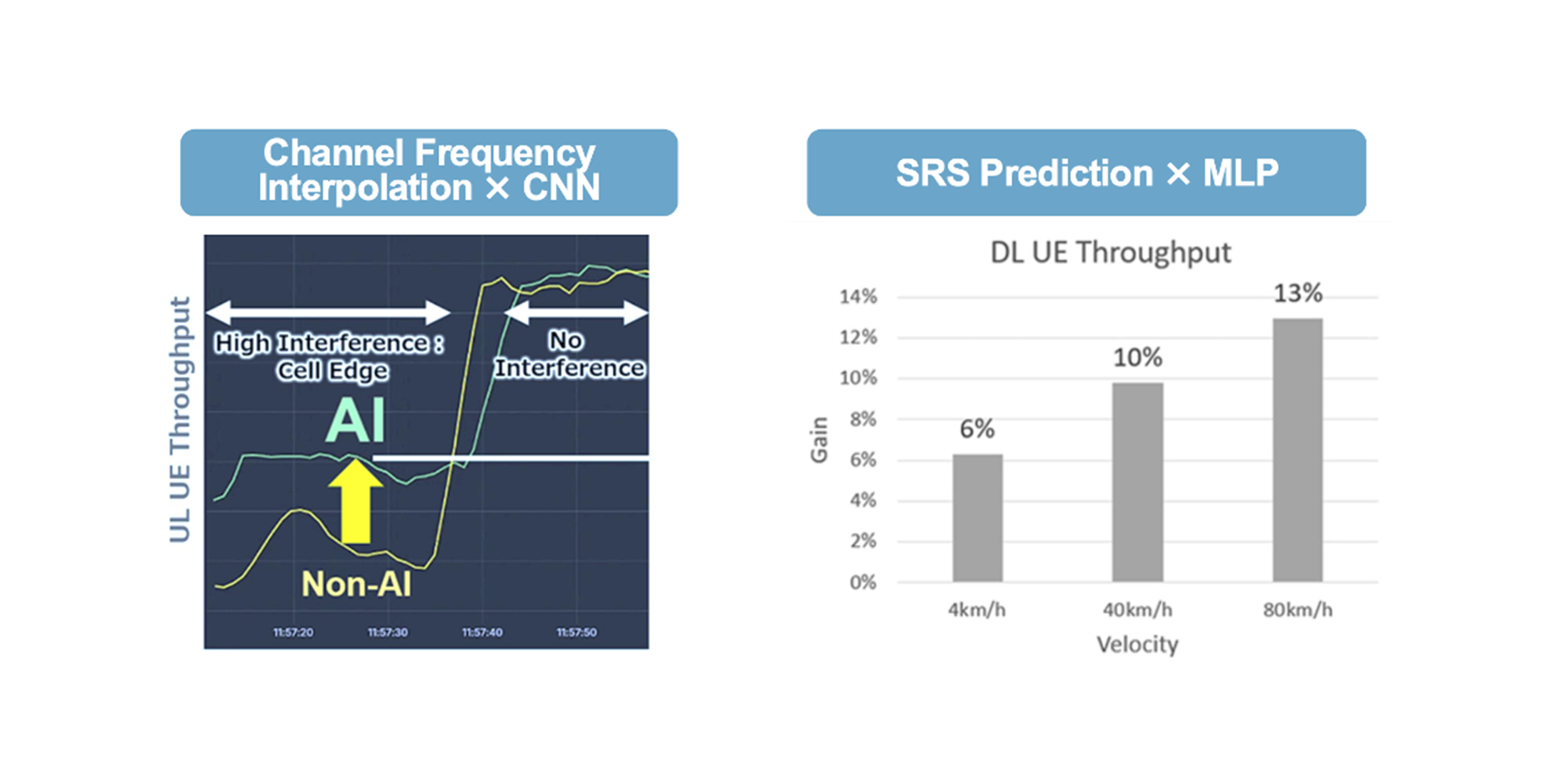
In 100 MHz n78 OTA evaluations, the Transformer interpolator achieved ≈ 30% uplink throughput gain vs LMMSE and ≈ 8% vs a CNN interpolator, with higher medians.
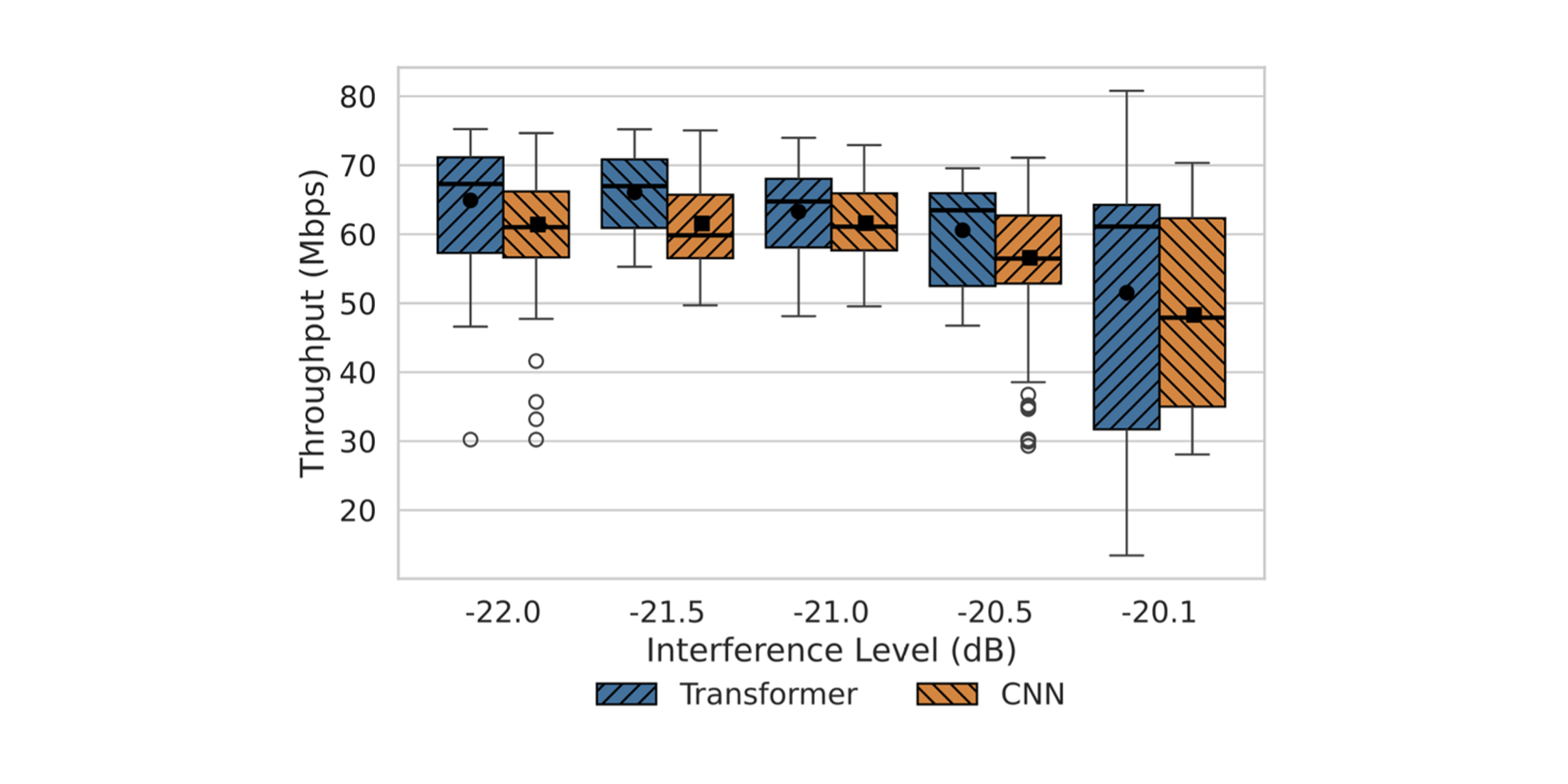
Fig. 5 — Uplink throughput (OTA): Transformer vs CNN vs LMMSE (box plots).
6.2 Sounding Reference Signal (SRS) Prediction
Problem
When uplink SRS reports are missing (UL gaps, mobility), the gNB must forecast near-future downlink beam quality to maintain alignment.
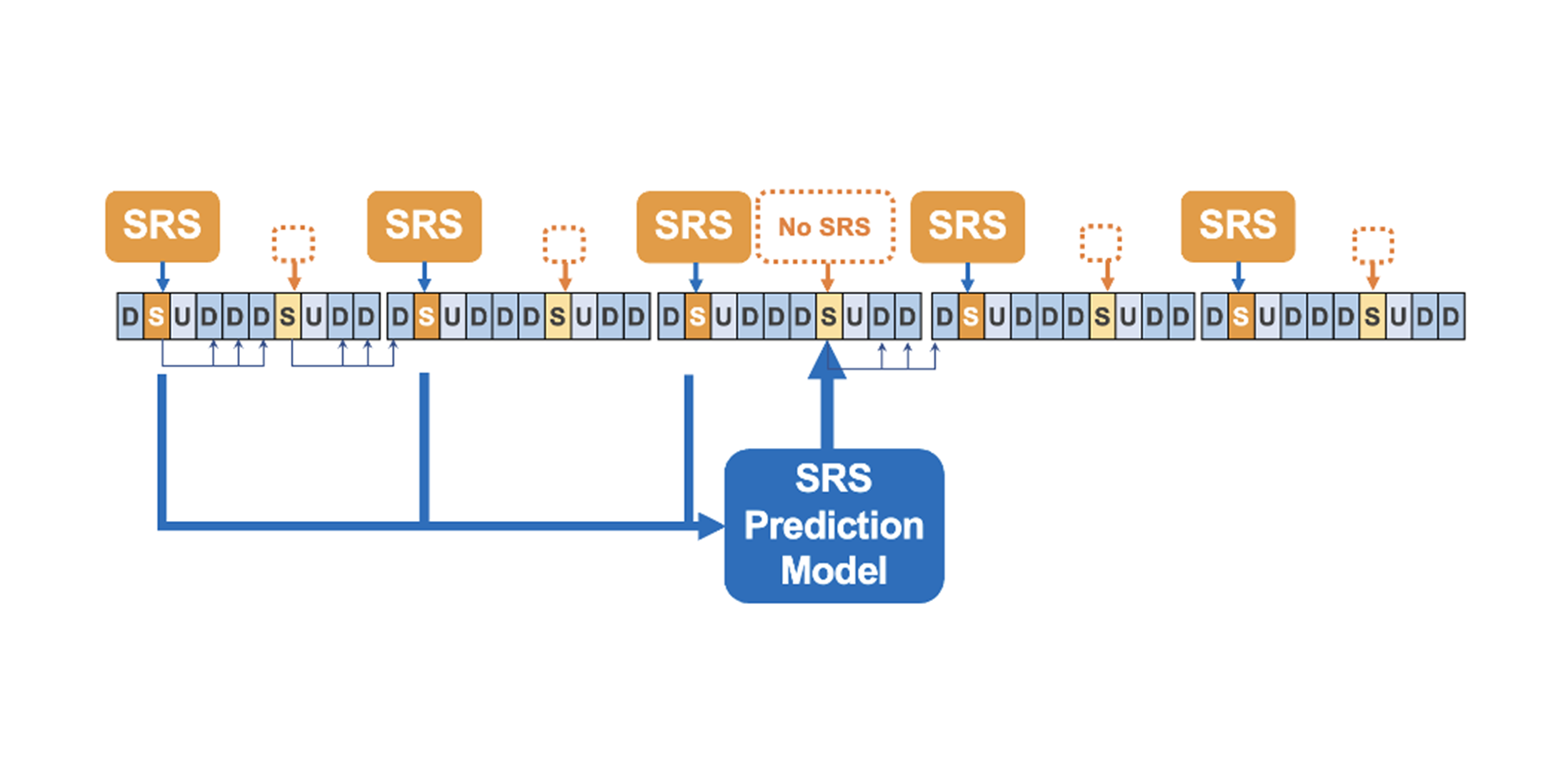
Fig. 6 — SRS prediction problem: missing SRS intervals on the UL timeline and the gNB’s forecast of the near-future channel.
Approach
Instantiate the blueprint for SRS prediction: ingest recent UL pilots/SRS and predict a future beam/quality for the target horizon. The global receptive field helps capture longer temporal dependencies.
Results
New simulations show ≈ 29% downlink gain at 80 km/h and ≈ 31% at 40 km/h, roughly 2.2–3.1× the gains of a prior MLP baseline.
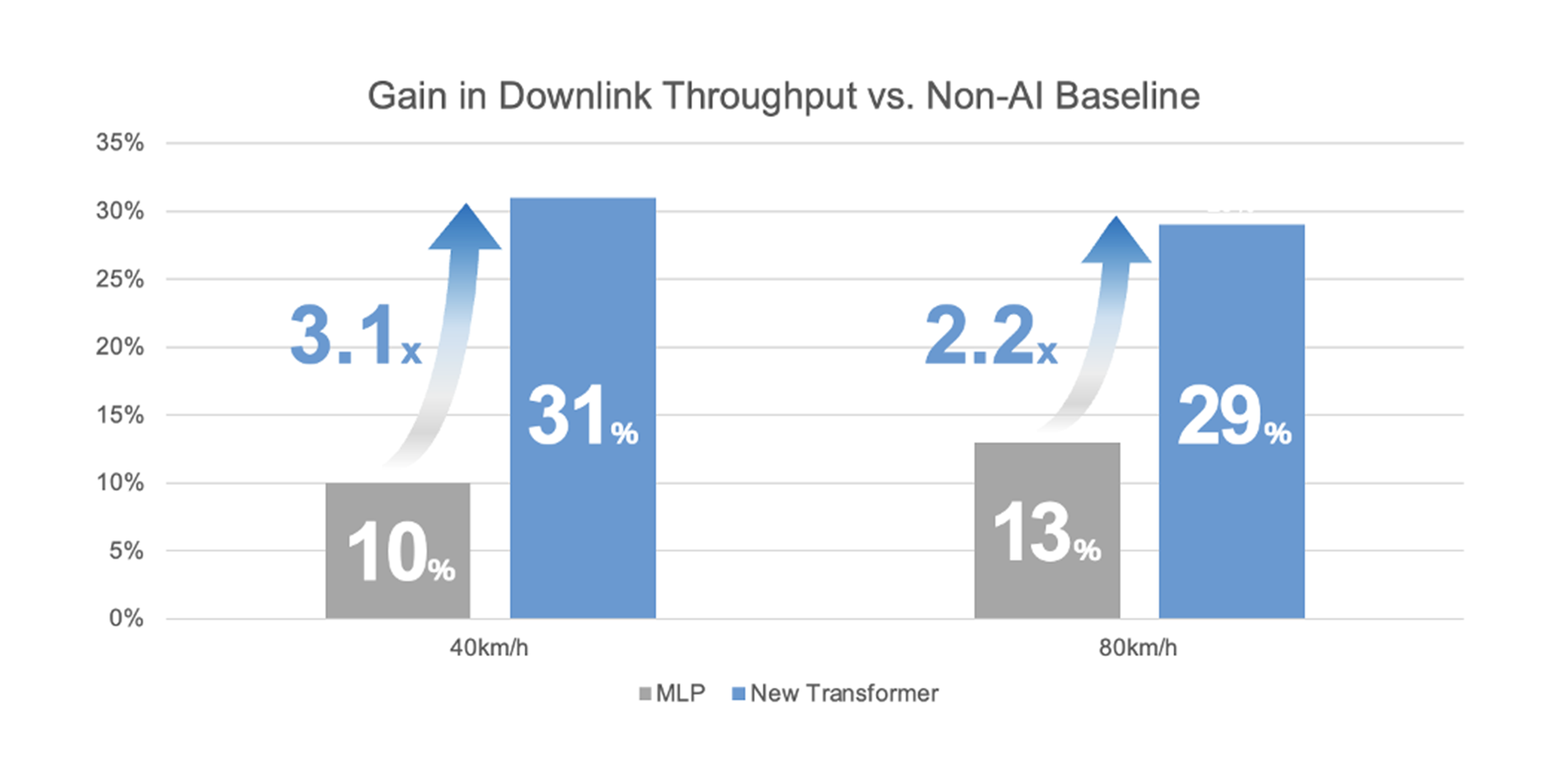
Fig. 7 — SRS prediction (simulation): Transformer vs MLP gains at 40/80 km/h.