2. Why AMD InstinctTM GPUs: The Option of “Splitting” a GPU for Use
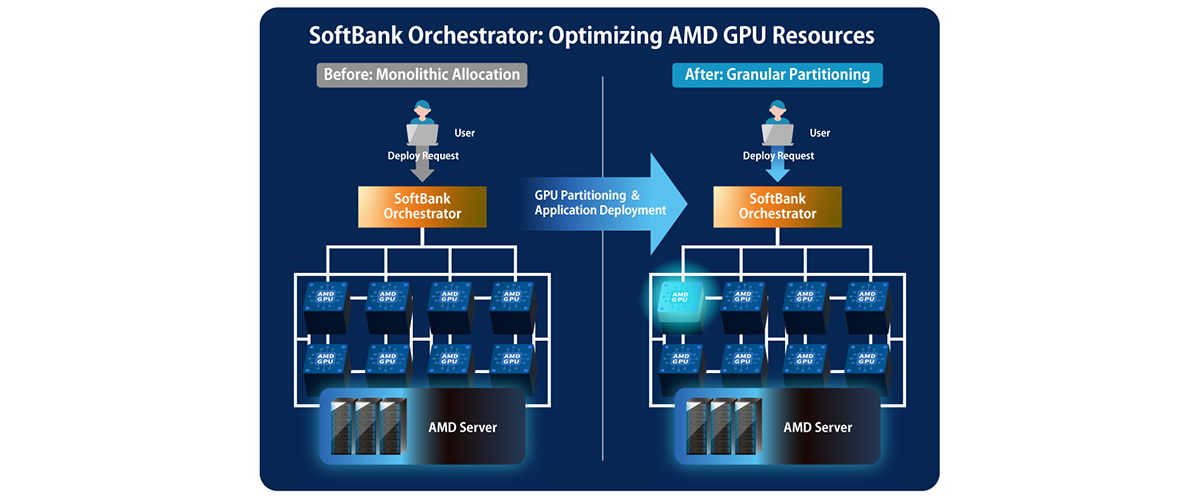
One approach to reducing slack and improving utilization and delivery efficiency, as discussed above, is to partition a GPU according to the workload’s needs.
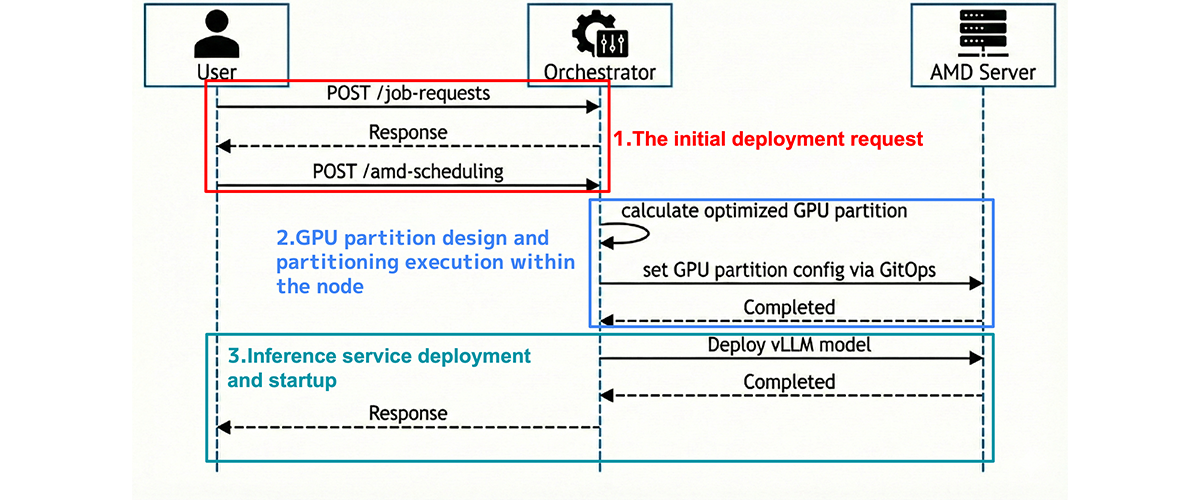
AMD InstinctTM GPUs feature high-capacity HBM* memory and provide a mechanism to divide GPU resources (GPU partitioning), allowing a single physical GPU to be partitioned into multiple logical devices as needed. This makes it possible to allocate “only what is required” to each inference service and to run multiple inference services in parallel on the same physical GPU, thereby reducing slack. As a result, limited GPU capacity can be utilized with finer granularity, expanding operational options even in environments with high demand variability.
*MI300X:HBM3 192GB, MI325X:HBM3e 256GB, MI355X/MI350X:HBM3e 288GB

Figure 1. Compute Partitioning on AMD InstinctTM GPUs (created by the author based on multiple documents)
AMD InstinctTM GPUs define their logical configuration from two perspectives: compute resources and memory configuration. Concretely, they provide:
・Compute Partitioning (Figure 1), which uses the XCD (Accelerator Complex Die)—a unit of the GPU’s compute resources—as the partitioning unit.
・Memory Partitioning (Table 1), which uses NPS (NUMA Per Socket)—a unit for controlling the memory configuration visible from a GPU Instance—as the partitioning unit.
In GPU partitioning, you configure partitions on both the compute side and the memory side, and by combining these settings you can use one physical GPU as multiple logical GPUs (GPU Instances).
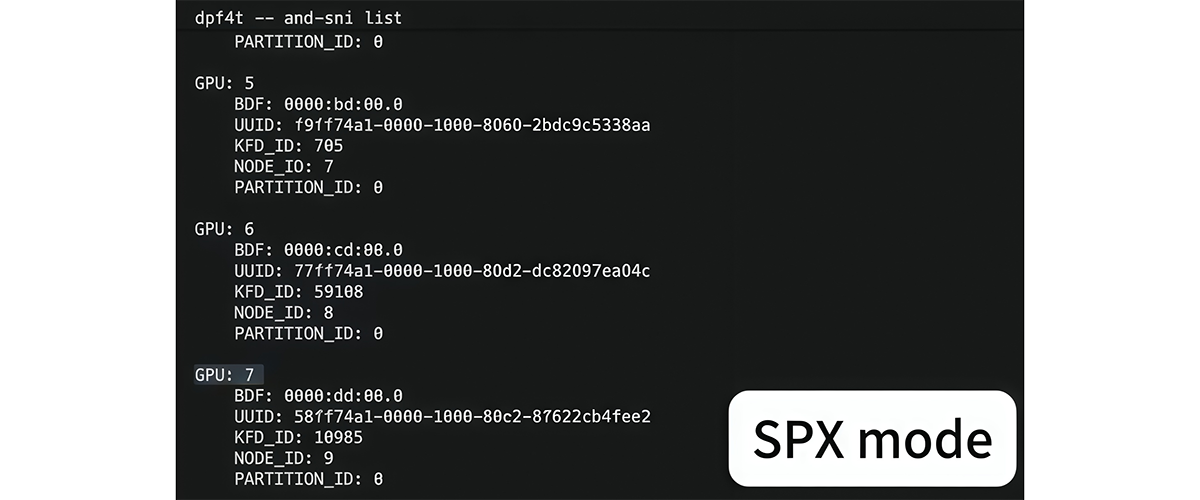
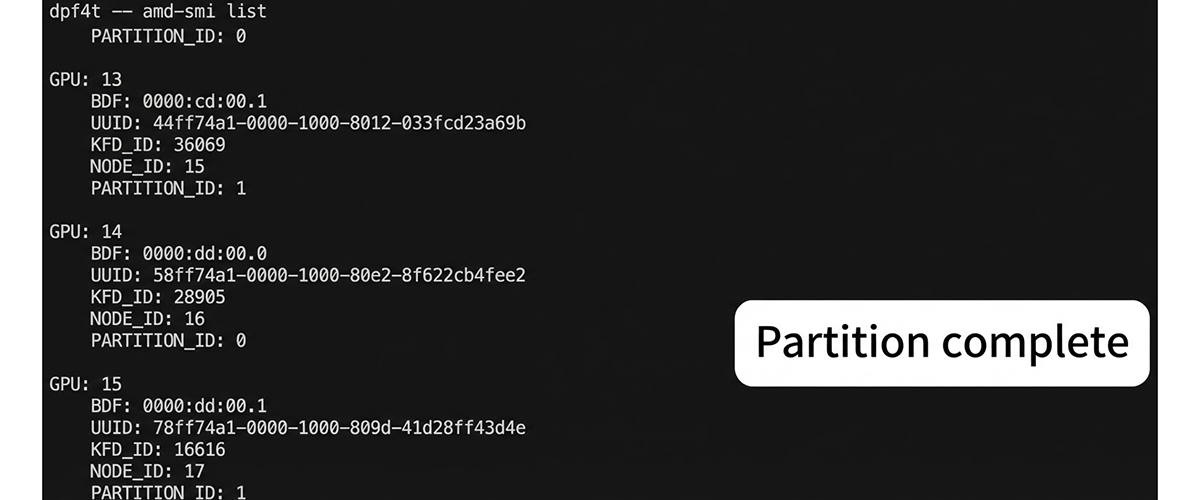
Compute Partitioning supports SPX / DPX / QPX / CPX modes, which allow a single AMD InstinctTM GPU to be split into 1, 2, 4 or 8 GPU Instances, respectively.
Memory Partitioning (NPS) configures addressable HBM regions to manage the memory access of each GPU Instance. With supported modes including NPS1, NPS2, NPS4, and NPS8, these settings optimize memory placement and accelerate overall access speeds.
These two types of partitioning are configured based on predefined compatibility rules under the constraint that the number of memory partitions cannot exceed the number of compute partitions (see Table 1 below).
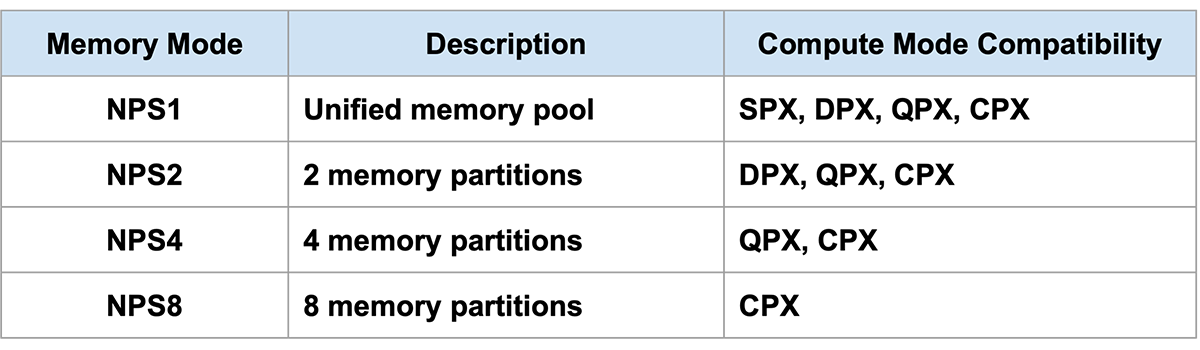
Table 1. Memory Partitioning on AMD InstinctTM GPUs (created by the author based on multiple documents)
By constructing GPU Instances through a combination of Compute Partitioning and Memory Partitioning, service providers can allocate the precise amount of GPU resources needed for specific model sizes and use cases, thereby improving operational efficiency.
Reference: AMD Partition overview