4. Proof-of-Concept Experiment
We conducted experiments assuming use cases such as: “A robot that follows users inside an airport and assists with luggage transportation”, “A security robot that follows suspicious individuals”.
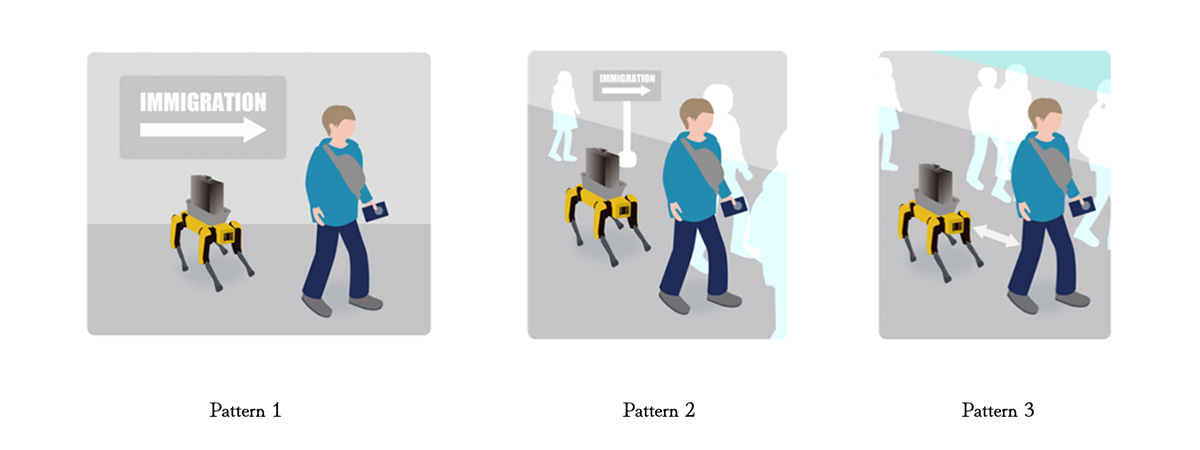
Figure 2. Overall image of the PoC
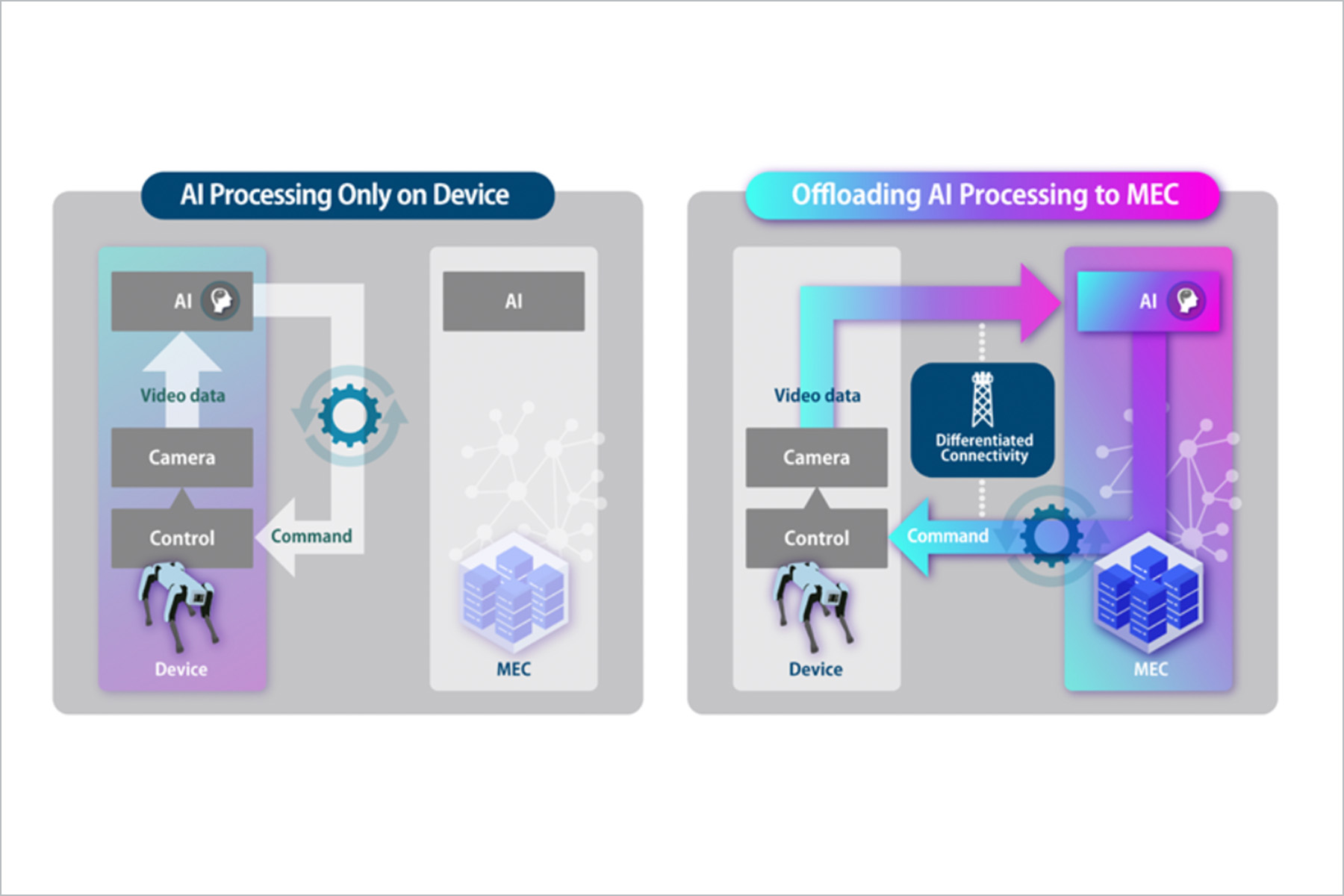
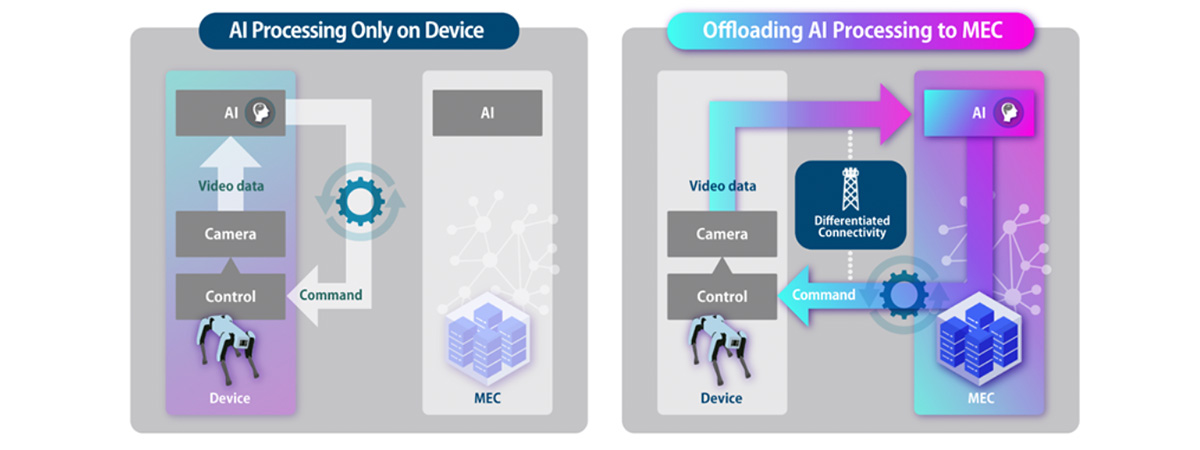
Pattern 1: AI processing is completed on the robot alone
In situations with few people and a simple environment, AI processing can be executed using only the robot’s onboard computing resources (CPU/GPU), and end-to-end latency can be minimized. On the other hand, the robot’s CPU/GPU usage becomes high, leading to increased power consumption.
Figure 3. Processing performed solely on the robot
Pattern 2: AI processing is offloaded to the MEC platform
As the density of people increases and the environment becomes more complex, more flexible decision-making and actions are required from the robot. In such situations, more advanced AI is needed, and AI processing is offloaded to the MEC platform. As a result, the robot can operate more flexibly than in standalone mode, and the usage of its onboard computing resources is reduced.
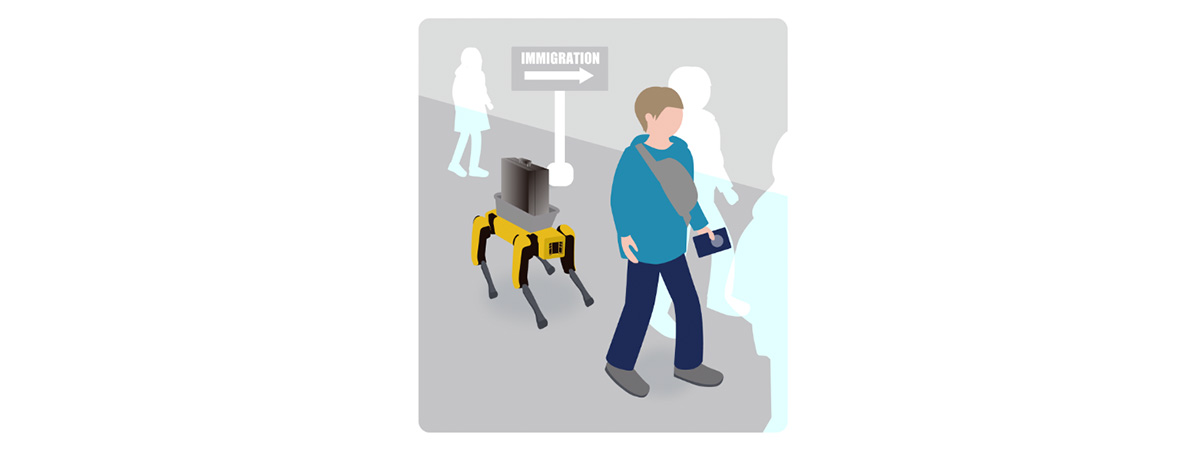
Figure 4. Processing in offload mode
Pattern 3: Intervention with Differentiated Connectivity
As shown in the figure below, while operating in offload mode, network congestion may increase—for example, due to an increase in the number of users—resulting in higher network latency. In such cases, Differentiated Connectivity, including network slicing, is applied to prioritize and control the robot’s traffic. As a result, we can observe a decrease in the end-to-end latency and an improvement in the application performance.
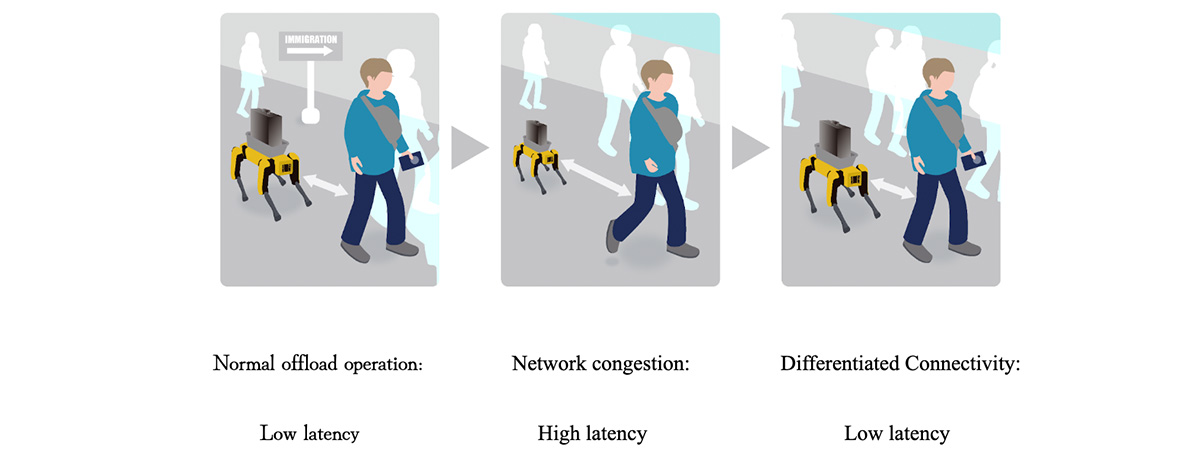
Figure 5. Intervention with Differentiated Connectivity
The system consists of a Unitree Go2 robot equipped with Jetson, a GPU-equipped MEC platform (external computing resource), a 5G network supporting Differentiated Connectivity, various AI models such as CNN (YOLO) and LLM, and multiple communication methods including ROS2, MQTT, and HTTP. The decisions for offloading and for intervention with Differentiated Connectivity are made through a mechanism that monitors multiple metrics—such as CPU/GPU usage, communication throughput, and end-to-end processing latency—and comprehensively evaluates them to make decisions.
As a result of the experiments, we confirmed the following two points:
1. In the experiments for Pattern 1 and Pattern 2, as shown in the graph of the robot-side GPU usage below, the GPU usage on the robot side significantly decreased before (Pattern 1) and after (Pattern 2) offloading.
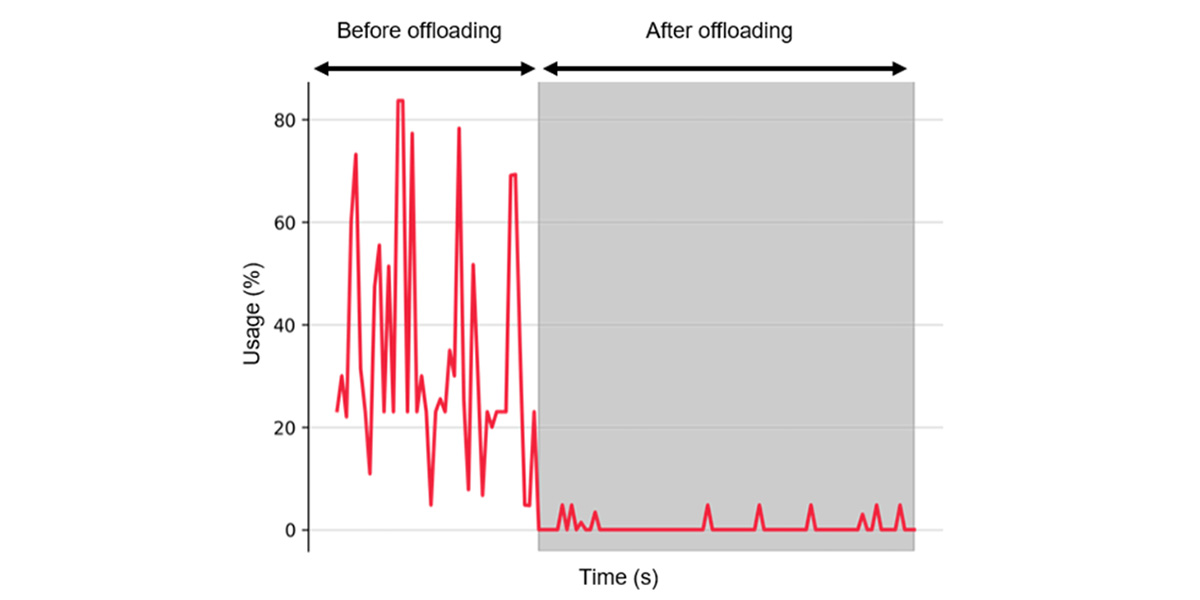
Figure 6. Robot-side GPU usage
2. In the experiment for Pattern 3, when the uplink throughput decreased (in the last part of the throughput graph below: from approximately 20 Mbps to below 10 Mbps), the robot’s end-to-end latency (as shown in the corresponding latency graph below) increased significantly. After the intervention with Differentiated Connectivity, the latency decreased significantly (shortened from approximately 400 ms to 100 ms).
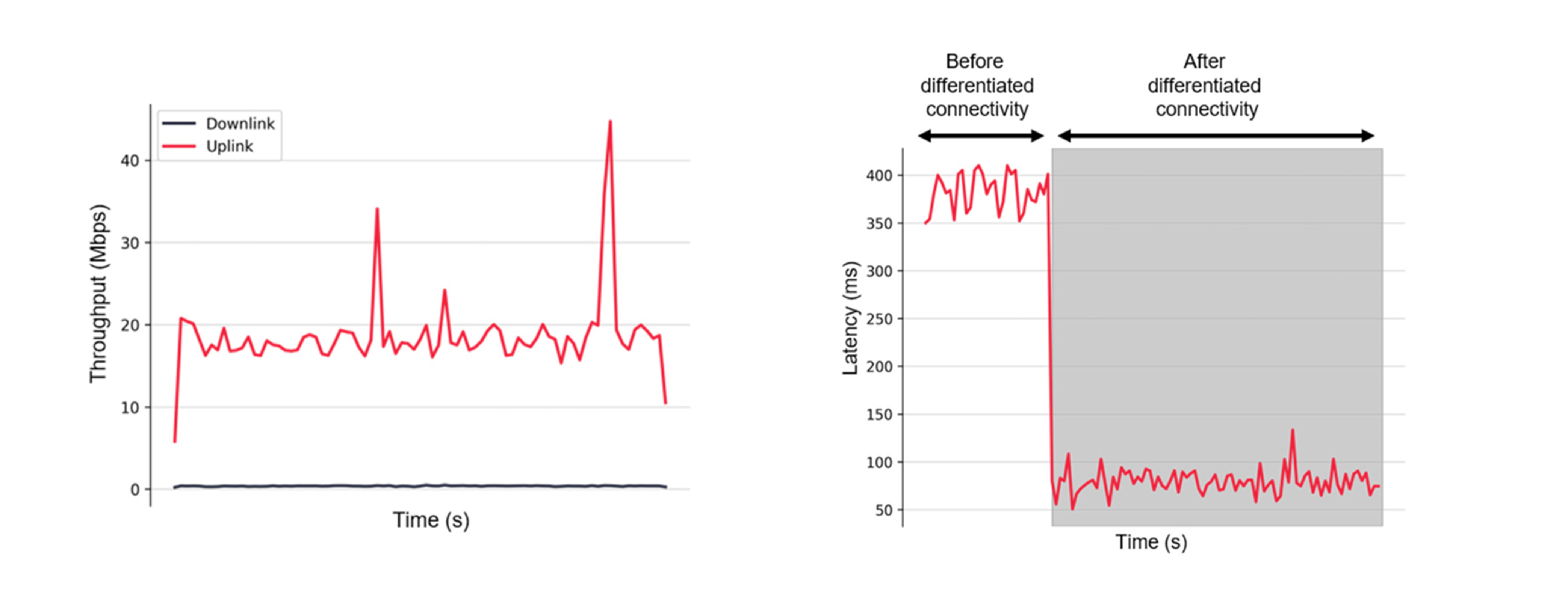
Figure 7. (Left) Robot communication throughput (before offloading), (Right) Robot end-to-end latency
In real-world environments, these three patterns are not independent but switch continuously according to environmental and communication conditions. In addition to the quantitative experiments described above, we also conducted similar qualitative experiments. For example, although the computational resource graph shown above is an example using GPU, similar trends were observed in inference experiments using CPU. Furthermore, when conducting experiments using isolated Wi-Fi in a non-interference environment instead of 5G, similar trends were observed in changes in computational resource usage and differences in latency depending on the time of day.
Based on the above experimental results, we demonstrated that an offloading architecture that integrally controls computing resources and communication resources—particularly communication networks capable of Differentiated Connectivity—is important and effective for achieving stable Physical AI.