フォーム読み込み中


皆様こんにちは!IT-OTイノベーション本部の横井です。
今回は私、横井が「次元モデリング」について解説してみることにしました!
【One Tech】とは、さまざまな部署・職種のエンジニアが世の中にあるさまざまなIT関連のキーワードや流行の1つに着目し、独自あるいはその職種ならではの視点からIT関連の技術用語やトレンドについて執筆していく連載企画です。
なぜ「次元モデリング」をテーマにしたかというと、以前あるデータサイエンスミートアップに参加した際に、登壇者の方が「日本の企業は次元モデリングがまだまだ実装できていないし、日本語の記事も少ない、、」という事を話していたので、「じゃあ私が書いてみるか!」と思い立ちこのテーマで執筆して見ることにしました
- データに基づいて意思決定を行うビジネス層やアナリティストが効率的かつ的確にデータ分析をする為の次元モデリング(Dimensional Modeling)というデータウェアハウス上のデータモデリング手法を紹介します
- RDB(リレーショナルデータベース)の基礎知識がある方、ビジネスデータの分析に興味のある方、SQLの基礎知識がある方向けに書いています
- この記事を読むことで、スタースキーマの基礎知識、スタースキーマ構造のデータベースの処理例を得ることが出来ます。
次元モデリングとは?
次元モデリング(Dimensional Modeling)とはデータウェアハウス上でのデータモデリング手法で、データに基づいて意思決定を行うビジネス層やアナリティストが効率的かつ的確にデータ分析をする為のデータウェアハウスの構築法です。
ビジネスで重要視されるKIPを様々な観点から紐解くためのデータモデリング法なので、DB(データベース)が複雑になりにくく、クエリパフォーマンスを向上し、より効率的にデータ分析ができる事が特徴です。
なぜ一般的なDBではダメなのか?
通常のシステムの正規化されたDBはOLTP(オンライントランザクション処理 )の下、システムを利用する上で最適なパフォーマンスができる様、少ないデータストレージで素早く反応できる構成をしています。これは、システムを利用する上では最適化されているのですが、そのシステムのデータを分析するといった面では効率的ではありません。
そこでOLAP(オンライン分析処理)に基づいた次元モデリングというデータ分析に特化したDBを用意し、分析の効率をあげる必要があるのです。
ファクトとディメンション
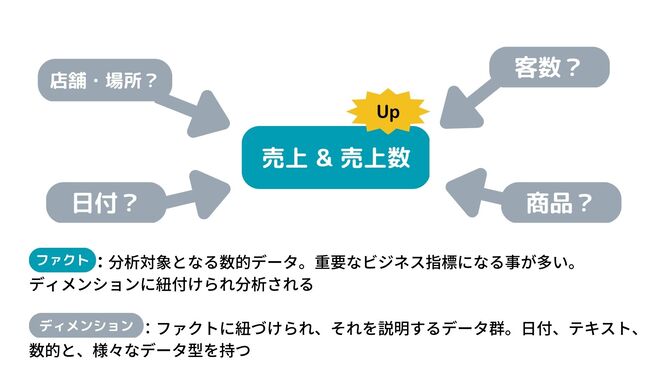
次元モデリングはデータをファクト(事項)とディメンション(次元)という2つのクラスに分類します。ファクトとは分析対象となる数的データで、売り上げや会員数といった、企業活動における重要な数的ビジネス指標(KPI)になります。ディメンションとはそのビジネス指標を様々な次元/角度で説明するデータ群です。
- ファクト:分析対象となる数的データ。重要なビジネス指標になる事が多い。ディメンションに紐付けられ分析される
- ディメンション:ファクトを説明するデータ群。日付、テキスト、数的と、様々なデータ型を持つ
例えば、日本全国に展開する携帯電話ショップの意思決定者は日毎の売上(円)と売上数(個)を重要なKPIだとし、それについて分析をしたいと考えたとします。この時、ショップの日毎の売上と売上数をファクトとし、それに付随する様々な情報(日付、店舗、商品名、顧客情報)をディメンションとします。
売上が上がった要因を分析する時、その要因が日付なのか、店舗なのか、はたまた客数なのか、様々な次元/角度から分析します。
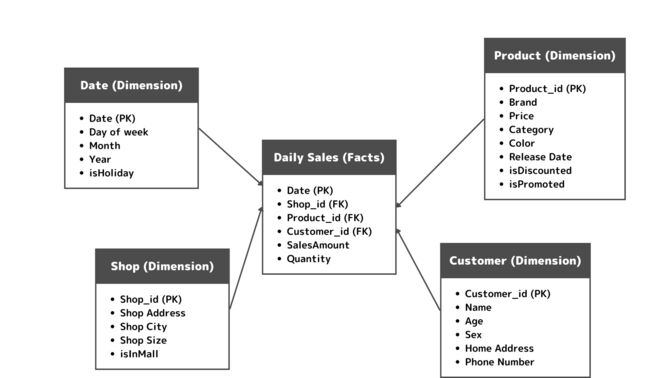
スタースキーマ(ER図)
実際に次元モデリングの構成図を見てみましょう。
次元モデリングでは、スタースキーマと呼ばれる手法でDBが構成されます。ファクトとなるファクトテーブルを軸にしてディメンションテーブルをそれに紐づける様に構成されます。一見普通の正規化されたER図の様にも見えるのですが、ファクトテーブルを中心にディメンションテープが置かれ、ディメンションが独立している事がわかります。さらに、ファクトテーブルは全てのディメンションの外部キー(FK)と分析対象の指標(売上と売上数)を保持しています。ファクトテーブを中心としディメンションテーブが周りにある様子が星を連想させる事からスータースキーマと呼ばれます。
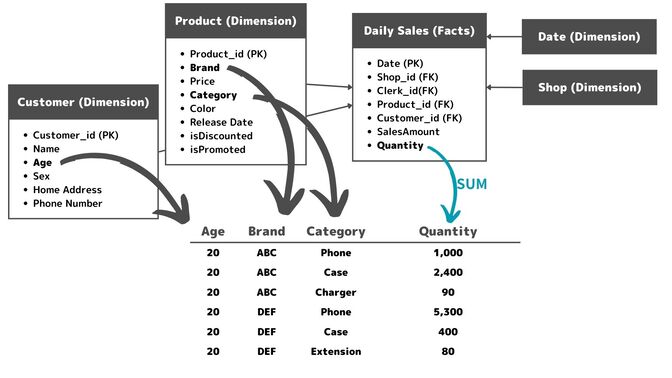
クエリのサンプルを見てみましょう。まずは年代別のブランド売上数を見てみます。スタースキーマはこのようなレポートが簡単なクエリだけで実現ができます。
SELECT
customer.age, product.brand, SUM(daily_sales.quantity)
FROM
customer, product
WHERE
customer.id = daily_sales.customer AND customer.id = daily_sales.product
GROUP BY
customer.age, product.brand

そこにカテゴリー情報を追加し、年代別のブランド毎の商品カテゴリー別の売上数を見てみます。
SELECT
customer.age, product.brand, product.category, SUM(daily_sales.quantity)
FROM
customer, product
WHERE
customer.id = daily_sales.customer AND customer.id = daily_sales.product
GROUP BY
customer.age, product.brand, product.category
この様に、DBの構成がシンプルなため、ディメンションをかえる際にクエリ文の変化が少なく、素早く必要なデータを抽出する事ができます。
メリット
次元モデリングにおけるスタースキーマには大きなメリットが4つあります。
1つ目は簡易化したデータベース構成にする事によって分析スペシャリストではなくても理解する事ができる事です。情報社会においてデータを根拠に意思決定するシーンが増えてきています。データを根拠に重要な意思決定を下す時、分析者は分析結果を意思決定者に明確に説明する必要があります。その際、スタースキーマの様なデータ保管方法は直感的で理解しやすいです。また、訓練次第で意思決定者自らクエリを叩き分析する事も容易です。
2つ目は確実性です。ディメンションというデータ群をテーブルに儲ける事で、分析範囲を常に意識した分析ができます。例えば、拠点ごとの売上を年代別に見る時に使用するテーブルはShopとCustomerのみになります。この時、第3正規化されたDBだと拠点に紐付いた連想テーブルなどがあればそこまでクエリに挿入する手間がかかり、ミスが多くなります。クエリ文でも、無駄なJOINを減らすことでミスを少なくし、データ分析をより確実なものにします。
3つ目はクエリパフォーマンスです。JOINを減らす設計には処理を早くするというメリットがあります。SQLにおけるJOIN句はクエリパフォーマンスを大きく低下させます。上記で記したように連想テーブルも前提としないので、クエリを叩きながらディスカッションするといった事も可能です。また、分析対象となるデータが一貫しているので、同じクエリ文を使い回し、素早く、様々な次元/角度から分析ができます。(ちなみに、スタースキーマの各テーブルのFKは連番の様に整数型で振られさらに処理を早くする事が推奨されています)
4つ目は変化に強い事です。例えば、売上に対するショップ定員の影響を計測するために店員ディメンション(Crerk)を追加したいとします。他のテーブルに依存しないシンプルなスタースキーマは新しいファクトやディメンションを追加する事が簡単です。企業活動をしていると、必要なデータはどんどん変化するので、その変化に柔軟に素早く対応できるスタースキーマはとても重宝されます。
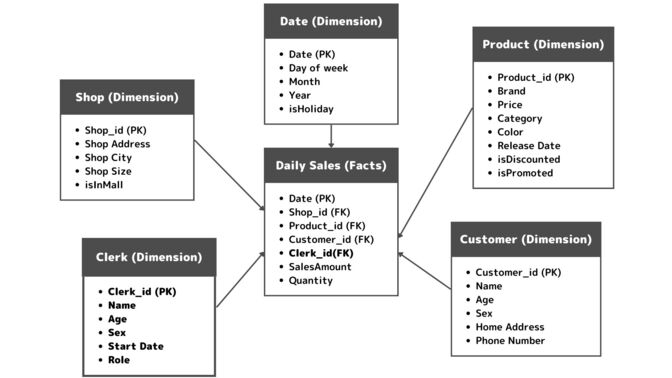
スタースキーマの様にテーブルのリレーションを簡易化し、不必要なJOINを省きクエリを単純にする事で日々変化する企業活動を柔軟かつ迅速に対応する事ができます。
まとめ
今回は次元モデリングについて解説していきましたが、いかがだったでしょうか?
次元モデリング(Dimensional Modeling)はファクトにフォーカスしたデータ保持体制を組む事でデータベースを簡易化する事で分析にかかる計算コストや時間を減らし、より確実な分析を可能にしてくれます。さらに、変化に強いスタースキーマは日々変化する現代社会でデータを元に仮説検証を繰り替えす上ではなくてはならない存在でしょう。
みなさんも機会があったら実装してみてはいかがでしょうか!
これからもデータサイエンスに関する記事をじゃんじゃん書いていくのでお楽しみに!
次回の【One Tech】もお楽しみに〜!
参考記事リンク
- Data warehouse schema design - dimensional modeling and star schema by Snir David - dev
- Dimensional Modeling by Bryan Cafferky
- [Power BI Tips] スタースキーマへの道 ~ モデリングってたぶんこれが基本 ~ by @yugoes1021
- スター スキーマと Power BI での重要性を理解する
- ディメンション・モデリング by ぺい(pei0804)
- Kimball, Ralph, and Ross, Margy. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. ドイツ, Wiley, 2013.
おすすめの記事
条件に該当するページがございません



