フォーム読み込み中
イベントレポート用の文字起こしにWhisperを使ってみたら最高だった

ソリューションアーキテクト
寺尾 英作
Alibaba Cloudに関わりたくて2018年にSBクラウドにジョイン。Alibaba Cloud ユーザコミュニティ Alieatersや、ソフトバンクのテック勉強会 SB Tech Night などの運営に関わっています。
2023年12月2日掲載

ソフトバンクで技術広報などを担当している寺尾です。
ソフトバンク アドベントカレンダー2023 の 2日目の記事です
先日、SoftBank Tech Nightを開催して、イベントレポートを書きました。その時に、ざーっとどんな話が合ったのかを振り返るのに動画だけだと見直すのに時間がかかります。2時間のイベントだったので、倍速で見ても1時間、話を聞いているともっとかかります。
ですが、テキストで残っていればすぐにざーっと確認出来てとても楽です。場所さえ分かればそこの場面だけ聞き直すことも出来るので、精度もある程度有れば構いません。
そこで、OpenAI Whisperを使って文字起こしをしてみました。
この記事ではWhisperを使ってみていくつかつまづいた点もあるので、使い方を解説していきます。
- OpenAI Whisperを手早く使いたいと思っている人向けに書きます
- 環境はMacを想定して書きますが、他の環境でも近いことは出来るはずです
- 環境構築コストを減らすためにcURLコマンドで実行します
はじめに
OpenAI Whisperは、OpenAIが提供している自動音声認識 (ASR) システムです。Web から収集された 680,000 時間の多言語およびマルチタスク監視データに基づいてトレーニングされています。
この記事では、できる限り難しいことをせず、以下の手順で進めていきます。
- 動画を25分以下に分割
- 動画をオーディオファイルに変換する
- APIキーを作成する
- APIを実行する
- テキストをチェックする
動画を25分以下に分割
イベントは配信をしていたので、動画でアーカイブがあります。しかし、現状のWhisperは25分以下、ファイル容量は25MB以下でないと処理出来ません。2時間のイベントでしたので、25分以下に分割をする事にします。
処理出来るファイル形式はm4a、mp3、mp4、mpeg、mpga、wav、webmとなります。
実務上の利便性も考慮します。音声データ化をしたあと、動画を見返すことも考えられます。テキストの10分の所の動画を見たいとなったときに、動画を見返しやすいように、2時間の動画を25分の動画に変換し、25分の動画をオーディオファイルに変換するという2段階を踏むと後工程が楽です。
動画を分割するときに気にすべき点は以下の4点です
動画は25分以下
現在の使用は25分、25MB以下の音声ファイルにのみ対応しています
文章の途中で切らない
文章の途中で切るとその部分の精度が悪くなります。話の切れ目を選んで分割しましょう。
動画を30秒〜1分程度被らせておく
動画のかぶり部分が無いと、繋がりがどのようになっているかを確認が難しくなります。単純に分割すると、0:00〜25:00のファイルと25:00〜50:00のファイルに分割してしまいますが、0:00〜25:00のファイルと24:00〜49:00のように、被る時間を作っておきましょう。
1ファイルずつ音声ファイルに変換
音声ファイルにした時に25MBを超えたら動画を短く切り直す必要があります。1ファイルずつ音声ファイルに変換しておくと、手戻りが少なくなります。
今回は、できる限りMacに有るもので編集をしたいとおもいますので、動画を「プレビュー」で分割をします。
分割は、動画をプレビューで開き、[編集]-[トリム]で実施が出来ます。動画を見ながら話の切れ目を見ながらトリムします。ファイルを保存します。
動画をオーディオファイルに変換する
次に、トリムした動画をプレビューで開き、[ファイル]-[書き出し]-[オーディオのみ]を選択して、ファイル名を付けて保存します。プレビューで書き出すとm4a形式となります。私の環境では別のツールでMp3にした時よりも倍くらいのファイルサイズになってしまいました。ここで、オーディオファイルが25MBを超えていたら動画の分割をやりなおしましょう。
ffmpegが入っていれば以下のコマンドでMP3に変換できます。
ffmpeg -i event1.mp4 -f mp3 -vn event1.mp3
| 変換方法 | 容量 |
| 動画ファイル(10:45) | 446.3MB |
| オーディオファイル(m4v by プレビュー) | 20.3MB |
| オーディオファイル(mp3 by ffmpeg) | 10.5MB |
m4vのファイルサイズが大きいのはビットレートが246.29kbps有るためのようです。MP3は128kbpsでエンコードされています。プレビューでオーディオファイルを書き出す際のビットレートを下げられれば良いのですが、調べた限り無いようです。
オーディオファイルのサイズが分割する単位を変えるので長いイベントであればあるほどffmpeg等で変換をした方が良いと思います。
APIキーを作成する
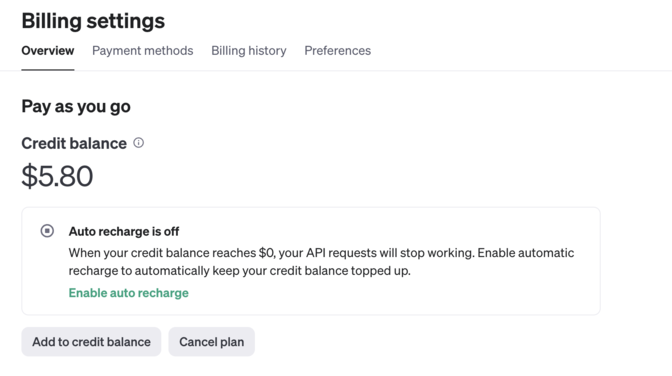
その後、API Keyを作成します。
[+ Create new secret key] を選択して、名前を付けます。

次にシークレットキーが作成されます。このシークレットキーはここでしか表示されませんので確実に保存をしておきます。
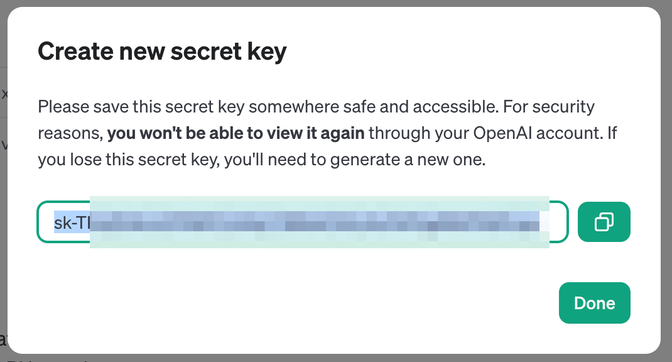
APIを実行する
まず、環境変数にAPIのシークレットキーを設定します。
% OPENAI_API_KEY=sk-RF7Raaaaaaaaaaaaaaaaaaaaaaaaaa設定出来ているかを確認します。
% echo $OPENAI_API_KEY
sk-RF7Raaaaaaaaaaaaaaaaaaaaaaaaaa設定が出来ていればcurlでAPIを実行します。curlが入っていなければ brewでインストールしましょう。
% brew install curlAPIを実行します。
% curl https://api.openai.com/v1/audio/transcriptions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F model="whisper-1" \
-F response_format="vtt" \
-F file="@event1.mp3"
実行すると1分程度で回答が返ってきます。
オプション解説
-H "Authorization: Bearer $OPENAI_API_KEY"
APIキーを設定します。
-H "Content-Type: multipart/form-data"
ファイルをアップロードするのでマルチパートを指定します。
-F model="whisper-1"
モデルを指定します。現在指定出来るのは"whisper-1"だけです。
-F response_format="vtt"
アウトプットのフォーマットを指定します。
text, vtt, srt, json, verbose_json が指定出来ます。
textが普通のテキストですが、
-F file="@event1.mp3"
アップロードするファイル名を指定します。先頭の@(アットマーク)は必ず指定してください。
この他に、以下のようなオプションがある様です。
language
言語をISO-639-1形式で指定します。日本語の場合はja、英語の場合はenを指定します。
prompt
プロンプトを指定して出力を制御することが出来るようです。
temperature
0〜1の間で指定します。0.8の場合は出力のランダム性を高くし、0.2の場合は厳密な出力を行います。
テキストをチェックする
オプション指定によって、出力結果が変わりますので、違いをレポートしてみます。
text
出力結果:text
それではお時間になりましたので 本セッションを開始いたします 皆さんこんばんは それではただいまよりソフトバンク テックナイト13inソフトバンクワールド を開催いたします 拍手をお願いいたします ありがとうございます 本日司会を務めますソフトバンク の森本と 野田ですよろしくお願いいたします 会場の皆様これまでソフトバンク テックナイトにご参加されたこと のある方挙手をお願いいたしますか すごくたくさんいらっしゃって 嬉しいですね
出力は、句読点・改行のない形で、空白で区切られています。
欠点としては、読みやすさのためには適宜改行を入れないといけません。また、動画の中で何分くらいのセリフかを知る方法がありません。
VTT , SRT
出力結果:vtt
WEBVTT 00:00:00.000 --> 00:00:18.500 それではお時間になりましたので 本セッションを開始いたします 00:00:18.500 --> 00:00:33.840 皆さんこんばんは それではただいまよりソフトバンク 00:00:33.840 --> 00:00:37.940 テックナイト13 in ソフトバンクワールドを開催いたします 00:00:37.940 --> 00:00:39.060 拍手をお願いいたします 00:00:39.060 --> 00:00:48.660 ありがとうございます 00:00:48.660 --> 00:00:52.120 本日司会を務めますソフトバンク の森本と 00:00:52.120 --> 00:00:58.700 野田ですよろしくお願いいたします 00:00:58.700 --> 00:01:03.540 会場の皆様これまでソフトバンク テックナイトにご参加されたこと 00:01:03.540 --> 00:01:07.860 のある方挙手をお願いいたしますか 00:01:07.860 --> 00:01:11.700 すごくたくさんいらっしゃって 嬉しいですね
何分頃のセリフかを知るためには、vtt形式が便利です。これは、元々字幕用のテキスト出力ですが、何時何分何秒から何秒までのセリフかを表示してくれますので、話を振り返りたいときには便利です。適度に無音時間で改行もされているので読みやすさもあります。
srtも同じように字幕用のファイルになります。出力されるファイル形式はそれぞれのセリフに番号がつく以外は、似たようなものですので好きな方を使えば大丈夫です。
json , verbose_json
jsonは、textを1つの値としてくくったものになります。
verbose_jsonは、各センテンスごとの状況を事細かく出力してくれます。選択出来るファイル形式の中では一番情報量の多い形式です。
費用
Whisperの費用は0.006ドル/分です。制限ギリギリの長さ25分を処理しても0.150ドルとなります。1ドルが148円だとして22.2円の費用で実現が出来ます。
OpenAIのデポジットが最低5ドルなので、デポジットにかかる金額としては740円となります。
※ 1ドル148円換算
まとめ
Whisperの日本語の書き出しは、驚くほど高品質でした。専門用語や固有名詞は間違うケースがありますが、1から書き起こすことに比べれば雲泥の差です。
しかも2時間のイベントでも100円ちょっとで書き起こしが可能で、驚きのコストパフォーマンスです。
イベントの書き起こしに革命的な進歩だと感じました。
25分の長さ制限が無くなればさらに快適になるなと感じました。文字起こしをして見たい方は是非試してみてください。
それでは、ソフトバンク アドベントカレンダー2023 、3日目にバトンを渡します。楽しみにしてください。
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



