フォーム読み込み中
AI Challenge Day 参加記!!画像データのRAG実装に挑戦!

DevOpsエンジニア
日吉 啓
2019年にSBへ新卒入社。
閉域ネットワークの運用エンジニアとして従事したのちにDevOps部門へ転身。
新たな発見、新たな学びの日々です。
2024年6月7日掲載

皆さん、こんにちは。共通プラットフォーム開発本部の日吉です。
昨今のAIの発展・普及は目覚ましく、まさにAI革命の時代が到来していると言えます。特に最近はLLMというAIの一種が注目を集めており、その代表格はOpenAIが開発したGPTと、それを対話式でWebUIから利用可能にしたChatGPTです。非エンジニア、非テック企業の人ですら名前を知っていて触ったことはあるのではないのでしょうか。
AIの起源は1950年にイギリスの数学者アラン・チューリングが発表したチューリングテストにあると言われますが、その成果から約70年という時間で、広く一般に普及する技術となったことは驚きの一言です。
先日私は、LLMの回答精度を最適化するための手法であるRetrieval-Argumented Generation(以下、RAG)という技術に関連するコンテストに参加しました。
今回は、RAGに関するコンテストの感想と、実装しようとした画像データのRAG実装の解説をしたいと思います。
この記事に含まれる内容
- AI Challenge Day のイベント概要
- AI Challenge Day に参加した感想
- RAGの概念と精度向上のための工夫
- 画像データのRAG実装に関する解説とサンプルコード
この記事に含まれない内容
- Azure OpenAIサービスのデプロイや使い方の解説
- LLM技術全般の解説
- テキストデータのRAG実装に関する解説
AI Challenge Day とは
私が、今回参加してきたのは角川アスキー総合研究所(以下、ASCII)と日本マイクロソフトが共催した AI Challenge Dayというイベントです。
日時: 2024年4月18日〜19日
場所: Microsoft AI Co-Innovation Lab (兵庫県 神戸市)
コンテストのお題
本コンテストでは、AI (本記事ではAI ≒ LLM の意味で使います)の学習データに無い情報を検索データベースから取得し、AIが回答を生成するためのプロンプトとして渡してやることで、本来「未学習」のはずのデータに関しても回答可能にするための手法であるRAGを実装し、その回答の精度を競い合いました。
「世界遺産トラベルアシスタント」というテーマに沿って、以下の機能を有するアシスタントを作ることがお題目でした。
- 日本の世界遺産に関する質問に答える
- 画像データをもとに画像に関する質問に答える

なぜGPT-4-Turboでは駄目なのか
最近ではGPT-4-Turboだけでなく、GPT-4-Omniモデルもリリースされ、その性能は驚異的です。これらのモデルは、非常に高い精度で人間の質問に回答することができ、専門家の応答と見間違うほどです。
しかし、優れた性能を誇るLLMであっても、学習データに含まれない情報については答えることはできません。例えば以下に示すコンテストのお題、「花ケ咲神社」という架空の寺社について、生のLLM(Azure AI Studio上のプレイグラウンドで実行)に投げても、寺社の名称を含む回答は得られません。
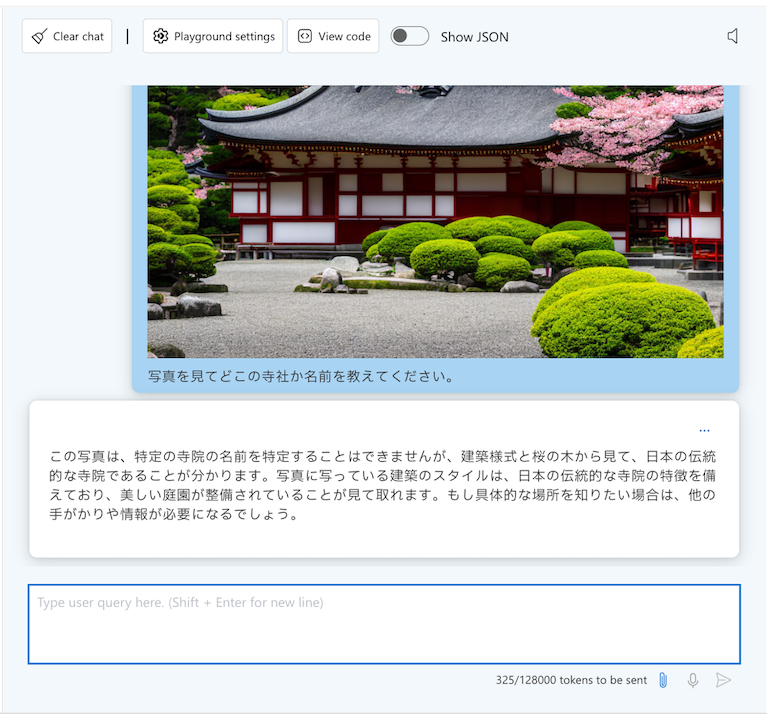
実在する史跡に関する情報はLLMの学習データに含まれているため、RAGを組み込んでいないLLMでもある程度の精度で回答が可能です。しかし、コンテストのお題は実在しない史跡についての情報も含まれています。それらの情報については、RAGの仕組みを取り入れなければ、回答は曖昧になります。
ビジネスケースに当てはめると、読者のみなさんが所属する企業はそれぞれが社外秘、部外秘の情報を持っていると思います。この社外秘、部外秘の情報が架空の史跡に当たり、それらに関する回答は素のGPTでは生成できません。これではプレゼン資料作成アシスタントとしても、営業同行アシスタントとしても、社内OAヘルプデスクとしても十分なパフォーマンスを発揮できません。
RAGの仕組みを導入することで、事前に登録した検索データベースを参照し、回答を生成することが可能になります。これにより、社外秘の情報についても適切な回答が可能となります。
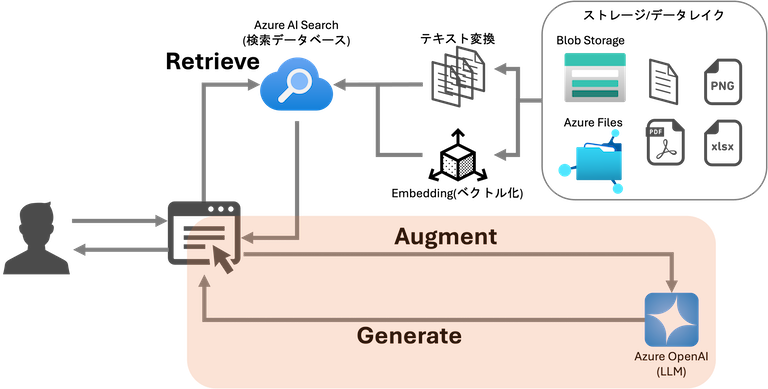
今回、私たちのチームがコンテストで採用したRAGアーキテクチャの詳細な説明は、文量の都合上省略しますが、以下では重要なポイントを取り上げ、どのような工夫でRAGの精度を向上させようと試みたのかについて具体的に説明します。
RAG実装の勘所
使用者の疑問に精確に答えるRAGを構築するための重要な視点として、主に以下の2つが考えられます。
- 質問内容に対して関連性の高い情報を検索データベースからどう取り出すか
- 検索データベースから選び出したデータを基に、どうAIに効果的な回答を生成させるか
関連度の高いデータの取得
関連性の高いデータを取り出すためのカギは、検索データベースへのデータ登録段階での前処理です。通常、ストレージに保管されている生データをそのまま、つまり未加工で検索データベースに保存しても、期待通りの検索精度は期待できません。
検索クエリに関連する情報を適確に引き当てるためには、その情報が検索で引っかかりやすいように、データベースへの登録時に生データを適切に処理する必要があります。
以下に、私たちのチームで用いた工夫の一部を示します。
- テキストファイルを章や節ごとに区切り、1ファイル内の情報粒度を揃える
- テーブル形式のデータは、json配列に変換し、ヘッダ行とデータ行が1対1で対応するようにする
- テキストの類似性だけでなく、ベクトルの類似性も比較できるように、embeddingした値も登録する

検索結果を参照した回答の生成
関連度の高いデータを取得できたとしても、それらのデータをもとにユーザの質問に的確に答えられるのかは別の話です。せっかくヒットさせたデータに正確な情報が含まれていても、AIがそのデータに基づいた回答をしてくれなければ、生成される内容はでたらめなものになってしまいます。
そこで、AIに回答生成を要求するときのプロンプトでは、渡されたデータに基づいてユーザの質問に答えるような指示をします。加えて、今回のお題である「世界遺産トラベルアシスタント」という文脈に基づいて、ユーザの興味を引くような説明も付け加えるようにプロンプトを構成しました。
さて、ここからは上述のような工夫を取り入れつつ、画像データのRAGを実装していきたいと思います。
なお、本記事に書いている内容はコンテストの期間中の実装は間に合わず、アイデア止まりの状態だったので、そのリベンジを兼ねてコンテスト後に実装したものになります。
画像データのRAGにおける前処理
RAGを画像データに応用するにあたり重要となるのが、画像データをどのように表現するかという問題です。我々人間は視覚情報を自己の認識・理解に直結させて言語化することができますが、コンピュータにとっては画像は画素(ドット)の集合体に過ぎません。そのため、画像情報をもとにAIに回答を生成させるには、その画像を自然言語で説明し、そのテキストを提供する必要があります。
さらに、求めている画像データをどのように検索でヒットさせるかという問題も考慮する必要があります。自然言語での説明文だけでは検索精度に難があるため、数値的な表現(以下、embedding)を生成することも重要だと考えました。
contextの取得
画像が「どの場所で」「何を」「どのように」描写しているかを自然言語で表したテキストを「context」(文脈・背景情報)と呼びます。
例えば、清水寺の画像に対して、「こちらの画像は、京都に位置する清水寺の夜景を描き出しています。寺院はライトアップされていて、周りの樹木は秋の紅葉により色とりどりに染まっています。背景には京都市街地の夜景が広がり、遠望では山脈のシルエットが見えます。」のような説明文を生成することがcontextの抽出と言えます。
これらの情報を検索インデックスに登録しておけば、回答生成時の情報源として活用できると考えました。
embedding(ベクトル)の生成
「embedding」とは、テキストや画像などのデータから特徴量を抽出し、それを数値表現に変換することを指します。embeddingは数値的に表現されるため、自然言語の表現と比較してブレが少なく、より正確な検索パラメータとして働くと期待されます。今回はこのembeddingを検索インデックスに登録することにしました。
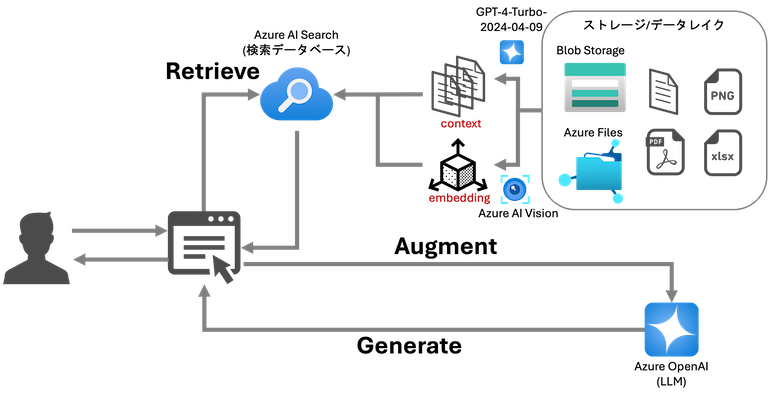
画像データのRAG実装
今回は以下のコンポーネントを利用して画像のRAGを実装していきます。
- 使用言語: Python
- 検索データベース: Azure AI Search
- Embedding(ベクトル化): Azure AI Vision Multimodal Embeddings API ※1
- Context抽出: Azure OpenAI GPT-4-Turbo (turbo-2024-04-09)
- 回答生成: Azure OpenAI GPT-4-Turbo (turbo-2024-04-09)
※1 Japan EastリージョンはMultimodal enbedding の利用不可(2024/5/1 時点)
また、検索インデックスに変換する画像のファイル名は、その画像が描画するものの名前を含むように整形されたファイルであることを前提とします。
例) 仁和寺_001.jpg
インデックスの事前定義
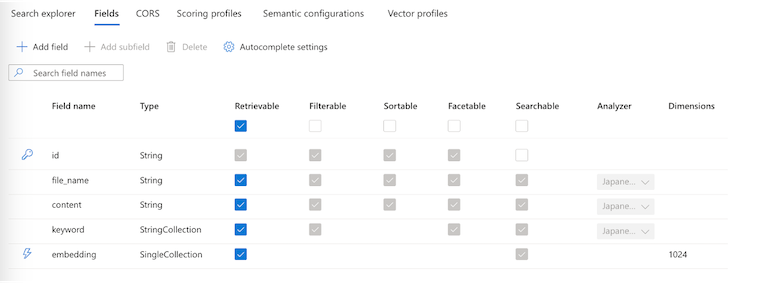
インデックスの登録をする前に、Azure AI Search にインデックスの定義を設定しておく必要があります。インデックスの定義とは、Azure AI Searchにインデックスを登録する際のルールのようなもので例として以下のような値を設定できます。
- どのようなフィールドを持つデータを格納するのか
- それぞれのフィールドは検索クエリの検索対象に含めるのか
- そのフィールドのデータ型は何なのか
- テキストは何語なのか
今回の画像検索の仕組みでは id、file_name、content、keyword、embedding の5つのフィールドを定義します。
画像ファイルのインデックス作成
次に、作成したインデックス定義にあわせる形で、画像ファイルをインデックスに変換します。インデックスへの変換処理を順を追って説明していきます。
1. file_nameの取得
ファイルのパスをテキスト処理するだけですので、比較的単純な操作で抽出可能です。
インデックスに変換したい画像ファイルの拡張子が複数ある場合には、その拡張子をリストアップしてそれぞれを検索してやる必要がある点は注意してください。以下にサンプルコードを示します。
# Parameters
target_image_extensions = ["jpg", "jpeg", "png", "webp", "gif"]
current_dir = os.getcwd()
target_dir = os.path.join(current_dir, "dataset/images/")
# Get File Names
for extension in target_image_extensions:
for full_path in glob.glob(os.path.join(target_dir, f"*/*.{extension}")):
file_name = os.path.basename(full_path)
# ターゲットファイルのパスとファイル名は後で使うので保存
image_info_list.append({"file_name": file_name, "full_path": full_path})
2. content, keyword の取得
次にcontextを抽出していきます。今回はcontextとして、content (文章での説明) と keyword (キーワードの羅列) の2つの要素に分解して取得してみようと思います。
全体の流れは以下の様になっており、ローカルの画像ファイルのパスを各処理を担う関数に渡してcontextとembeddingを取得するようにしています。
なお、local_image_to_base64 関数のコードは省略します。画像ファイルのパスを受け取ってbase64にエンコードした値を返す関数であればOKです。
# Transform target_files to indeices
for target in image_info_list:
# base64に変換した画像をgpt-4-turbo-visionで分析
base64str = local_image_to_base64(target["full_path"])
contexts = get_contexts_of_image(base64str)
# computer visionで画像をembedding
image_vector = get_vectorized_image(target["full_path"])
get_contexts_of_image 関数は以下のような実装になっており、base64エンコードされた画像をAzure OpenAI GPT-4-Turbo (turbo-2024-04-09) モデルで分析しています。
この処理の工夫ポイントは、keyword、contentのデータ型をプロンプトで指定し、それらをjson形式で返すことを徹底するようシステムプロンプトで指示していることです。これによって後続のデータ加工を容易にできます。
def get_contexts_of_image(base64str: str):
api_base = os.getenv("AZURE_OPENAI_ENDPOINT")
aoai_key = os.getenv("AZURE_OPENAI_KEY")
deployment_name = os.getenv("AZURE_OPENAI_VISION_DEPLOYMENT_NAME")
api_version = "2024-02-01"
base_url = f"{api_base}openai/deployments/{deployment_name}"
aoai_client = AzureOpenAI(
api_key=aoai_key,
api_version=api_version,
base_url=base_url,
)
try:
response = aoai_client.chat.completions.create(
model=deployment_name,
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": 'You, as the AI assistant, will output a sentence containing a detailed and detailed description of the image you have been given, as well as keywords. It must be strictly in Japanese and follow the following format.\n\n {"keywords":String[],"description":String}',
},
{"type": "image_url", "image_url": {"url": base64str}},
],
},
{
"role": "user",
"content": [
{"type": "text", "text": "この画像を説明して下さい"},
{"type": "image_url", "image_url": {"url": base64str}},
],
},
],
temperature=0.7,
top_p=0.95,
max_tokens=1000,
)
except Exception as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
str_result = response.json()
json_result = json.loads(str_result)
metadata_str = json_result["choices"][0]["message"]["content"]
metadata = json.loads(metadata_str)
return {
"keywords": metadata["keywords"],
"content": metadata["description"],
}
3. embedding の取得
最後にembeddingの取得です。Azure AI Visionから提供されているVectorize Image APIを使うことで容易に画像をベクトル値に変換することができます。
contextの取得と異なり、AI Visionは画像データをバイナリ値のまま受け付けます。したがって以下の二点を考慮する必要があります。
- 指定された画像ファイルをバイナリ読み込みモード ("rb") で開く
- HTTP リクエストヘッダの Content-Type には `application/octet-stream` を指定する
def get_vectorized_image(image_path: str):
url = os.getenv("VISION_ENDPOINT")
vision_key = os.getenv("VISION_KEY")
with open(image_path, "rb") as img:
data = img.read()
headers = {
"Ocp-Apim-Subscription-Key": vision_key,
"Content-Type": "application/octet-stream",
}
try:
response = requests.post(url, data=data, headers=headers)
if response.status_code == 200:
image_vector = response.json()["vector"]
return image_vector
else:
print(
f"An error occurred while processing {image_path}. Error code: {response.status_code}."
)
except Exception as e:
print(f"An error occurred while processing {image_path}: {e}")
return None
4. インデックスの登録
作成したインデックスはAI Searchに登録する必要があります。Azure AI Search の Python SDK でサンプルが公開されているため、それを参考にしてインデックスを登録します。
類似画像検索&回答生成
事前準備が完了したので、ここからがデータ探索とそのデータを利用した回答生成、すなわちRAGを処理するフェーズです。
Retrieve
まずは検索データベースからユーザが要求した画像に類似する画像を探索します。
インデックスの作成をするために行った処理をユーザが投げた画像に対しても行い、contextとembeddingを取得し、この値を利用してハイブリッド検索※を実行します。
※ Azure AI Search で利用可能な検索手法の一つ。テキストの一致度や登場頻度をもとに検索するフルテキスト検索と、数値表現をもとに検索するベクトル検索の掛け合わせで双方のいいとこ取りができる手法。詳細はMS Learnをご確認ください。
def search_images(text_queries: object, vector_query: object):
ai_search_service_name = os.getenv("AI_SEARCH_SERVICE_NAME")
ai_search_endpoint = "https://{}.search.windows.net/".format(ai_search_service_name)
ai_search_key = os.getenv("AI_SEARCH_SERVIVE_ADMIN_KEY")
index_name = "image-processed"
credential = AzureKeyCredential(ai_search_key)
filter_values = ""
high_score_result = []
for query in text_queries:
print(f"Search for '${query}'")
try:
search_client = SearchClient(ai_search_endpoint, index_name, credential)
results = search_client.search(
search_text=query,
filter=filter_values,
query_type=QueryType.SEMANTIC,
query_caption=QueryCaptionType.EXTRACTIVE,
query_answer=QueryAnswerType.EXTRACTIVE,
query_answer_threshold=0.9,
query_language="ja-JP",
query_speller="none",
vector_queries=[vector_query],
semantic_configuration_name="semantic-config",
search_fields=["file_name", "content", "keyword"],
select=["file_name", "content", "keyword"],
top=5,
)
if results:
# 最も高い@search.scoreと@search.reranker_scoreを持つresultを特定する
max_search_score_result = None
max_reranker_score_result = None
max_search_score = float("-inf")
max_reranker_score = float("-inf")
for result in results:
if result is not None:
if result["@search.score"] > max_search_score:
max_search_score = result["@search.score"]
max_search_score_result = result
if result["@search.reranker_score"] > max_reranker_score:
max_reranker_score = result["@search.reranker_score"]
max_reranker_score_result = result
if max_search_score_result:
high_score_result.append(max_search_score_result)
if (
max_reranker_score_result
and max_reranker_score_result != max_search_score_result
):
high_score_result.append(max_reranker_score_result)
except Exception as e:
print(f"An exception was occurred!!!: {e}")
return high_score_result
ここでの工夫として、Azure AI search に対して別々のクエリ(text_queries)で複数回検索をかけたあと、その検索結果の中からランキングスコアが高い結果のみを、精度高い検索結果(high_score_result)として返すようにした点が挙げられます。これによって、検索結果に類似度の低い画像の情報が含まれる割合を低くしようとしています。
Argument & Generate
LLMの振る舞いや役割を事前定義するためのシステムプロンプトには、今回の「世界遺産トラベルアシスタント」というテーマに沿った振る舞いをしつつ、ソースに基づいた回答をするために、以下の内容を含めました。
- 旅行アドバイザーとしての振る舞いをすること
- 建物の名前や地名が特定できるときは回答に含めること
- ユーザの興味を掻き立てるような説明を回答に含めること
- ユーザの質問に対する回答は与えられた情報源に基づいて回答すること
- 情報源に複数回登場するファイル名は信頼度の高い(類似性のある)データなので優先的に回答に採用すること
- 日本語で回答すること
i = 0
for result in search_results:
i = i + 1
content = f"{result['file_name']}: {result['content']}"
content_query += f"{i}. {content}\\n"
content_query = content_query[:-2]
input_prompt = (
f"# Question\n{target['user_prompt']}\n# Source Informations\n{content_query}"
)
print("input_prompt is\n", input_prompt)
generate_answer(base64str, input_prompt)
generate_answer関数の実装は以下の通りです。
この関数では、検索結果で何度も登場する情報を信頼度が高いと判断し、利用します。つまり、複数の検索クエリから得られた結果を多数決式で組み合わせ、回答を生成します。これにより、一部の検索結果が不要な情報を含んでいても、全体としての回答を正確に導くことが可能となります
def generate_answer(base64str: str, input_prompt):
api_base = os.getenv("AZURE_OPENAI_ENDPOINT")
aoai_key = os.getenv("AZURE_OPENAI_KEY")
deployment_name = os.getenv("AZURE_OPENAI_VISION_DEPLOYMENT_NAME")
api_version = "2024-02-01"
base_url = f"{api_base}openai/deployments/{deployment_name}"
aoai_client = AzureOpenAI(
api_key=aoai_key,
api_version=api_version,
base_url=base_url,
)
try:
response = aoai_client.chat.completions.create(
model=deployment_name,
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "As a Professional Trip Advisor, you will produce a sentence that accurately responds to questions about World Heritage sites based on the provided source information and images. When you can identify place names or building names, include that information in your description. Additionally, provide enticing descriptions of the location's characteristics, highlights and historical backgrounds to spark the user's interest. Files that appear multiple times in Source Information are considered reliable, so prioritize them in your descriptions. The response must be strictly in Japanese.",
},
],
},
{
"role": "user",
"content": [
{"type": "text", "text": input_prompt},
],
},
],
temperature=0.3,
top_p=0.95,
max_tokens=1000,
)
except Exception as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
str_response = response.json()
json_response = json.loads(str_response)
answer = json_response["choices"][0]["message"]["content"]
print(f"Generated answer is\n{answer}")
次のようなリクエストがユーザから要求されたと仮定して、実際の挙動を確認してみます。
質問:
写真を見てどこの寺社か名前を教えて下さい
画像:

このとき、LLMへ投げられるユーザプロンプト(input_prompt) は以下のように構成されます。
# Question
写真を見てどこの寺社か名前を教えてください。
# Source Informations
1. 花ケ咲神社_001.png: この画像は、美しい日本の庭園を映しています。前景には整然と剪定された緑豊かな丸い形の樹木があり、背景には桜の木がピンクの花を咲かせています。画像の中央には、赤と白の色が特徴的な伝統的な日本の寺院の屋根が見えます。この風景は日本の伝統的な美しさと自然の調和を表しています。\n2. 仁和寺_011.jpg: 画像には、満開の桜の木々が並ぶ小道があり、背景には日本の伝統的な五重塔が見えます。春の季節を象徴する美しい桜が青空の下で華やかに咲いており、地面には落ちた桜の花びらが散らばっています。五重塔は黒と灰色の屋根が特徴的で、日本の伝統的な建築美を示しています。\n3. 花ケ咲神社_001.png: この画像は、静寂と自然の美しさが感じられる日本の伝統的な庭園を捉えています。画像の前景には、整形された緑豊かな木々があり、その背後には赤と白の色が映える伝統的な日本建築の一部が見えます。さらに背景には、満開の桜の枝が庭園の上に広がり、鮮やかなピンク色が周囲の緑と調和しています。この場所は、日本の美を象徴する風景として、静けさと和の精神を感じさせる場です。\n4. 仁和寺_011.jpg: 画像には、満開の桜の木々が並ぶ小道があり、背景には日本の伝統的な五重塔が見えます。春の季節を象徴する美しい桜が青空の下で華やかに咲いており、地面には落ちた桜の花びらが散らばっています。五重塔は黒と灰色の屋根が特徴的で、日本の伝統的な建築美を示しています。
LLMがシステムプロンプトとユーザプロンプトを解釈し、最終的に生成した回答が以下のようになります。
この写真は「花ケ咲神社」のものです。美しい日本の庭園が映されており、整然と剪定された緑豊かな丸い形の樹木と、満開の桜の木が背景にあります。中央に見えるのは、赤と白の色が特徴的な伝統的な日本の寺院の屋根です。この場所は、日本の伝統的な美しさと自然の調和を感じさせる静寂な空間です。
検索結果には一部、花ケ咲神社以外の情報も含まれていますが、システムプロンプトの指示が効いたのか、正確な名前を回答することができています。
実は…
今回実装したRAGの仕組みですが、場所の名前を特定するためにファイル名を頼りにしています。
したがって、インデックスに変換する前のファイル名がでたらめなものだと正確な回答が得られません。この点はもう少し改良の余地があります。
まとめ
今回、AI Challenge Dayに参加し、RAGアーキテクチャに関する様々な知識を得ることができました。一緒に参加したエンジニアの皆さんの知識と情熱に感銘を受けるとともに、私にとって大きな学びの場となりました。
コンテストに参加した他チームの成果は、ASCII.jpにて公開されている記事や、Youtubeに公開されているアーカイブに残っていますので、ぜひそちらもご覧になってください。
日本マイクロソフトのAIパートナー10社が神戸に集合 RAGとマルチモーダルに挑む
私個人の振り返りとして、コンテスト中に挑戦した画像のRAGの実装が時間的制約により完成することができなかったことで悔しい思いをしましたが、後日再挑戦して構想していた動作に近づけられた点は非常に嬉しかったです。
AIに関する技術はまさに日進月歩ですが、そのスピード感においていかれないように今後も様々なチャレンジをしていきたいと思います。
最後まで読んでいただきありがとうございました。
関連サービス
生成AIパッケージ
セキュアなAzure OpenAI Service環境をパッケージとして提供するサービスです。よりスムーズに生成AIの導入を実現することができます。
MSPサービス
MSP(Managed Service Provider)サービスは、お客さまのパブリッククラウドの導入から運用までをトータルでご提供するマネージドサービスです。
Microsoft Azure
Microsoft Azureは、Microsoftが提供するパブリッククラウドプラットフォームです。コンピューティングからデータ保存、アプリケーションなどのリソースを、必要な時に必要な量だけ従量課金で利用することができます。
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



