フォーム読み込み中
Azure Speech Serviceで日本語の音声を認識したり読み上げてみた

クラウドエンジニア
小柳 雅史
オンプレ経験10年超、クラウド経験複数年のエンジニアです。
得意分野:各種OS、仮想化技術、セキュリティ、ネットワーク、ストレージ、IoT
2024年10月18日掲載

ご覧いただきありがとうございます。ソフトバンクの小柳です。
本記事では、業務上でも利活用が広がってきた日本語の音声認識、テキスト読み上げをAzure Speech Serviceを利用して試してみます。
Azure Speech Serviceとは
AzureのSpeech Serviceは、Microsoftが提供する音声認識・音声合成のクラウドサービスです。このサービスを利用すると、会議やインタビュー、通話などの音声データをリアルタイムでテキスト化(文字起こし)したり、逆にテキストを音声に変換して読み上げたりすることができます。
Azure Speech Serviceは、大きく以下の機能を提供しています。
Speech-to-Text(音声認識):音声をリアルタイムでテキストに変換します。複数の言語をサポートしており、日本語にも対応しています。ノイズリダクションや話者分離機能も備えています。
Text-to-Speech(音声合成):テキストを自然な音声で読み上げます。複数の音声スタイルや感情を選択でき、日本語の音声もサポートしています。
Speech Translation(音声翻訳):リアルタイムで音声を別の言語に翻訳します。
Speaker Recognition(話者認識):話者の声を識別し、誰が話しているのかを判別できます。
Intent recognition(意図認識) ユーザーの音声からその意図を理解し、特定の操作やアクションをトリガーするための機能です。
Keyword recognition(キーワード認識) 音声の中から特定のキーワードやフレーズを検出する機能です。
今回は、この中からSpeech to TextとText to Speechを利用して日本語音声の文字起こしと、読み上げを行う手順を紹介します。
手順
1. アカウントの作成とSpeech Serviceの有効化
Azure Speech Serviceを使用するためには、まずMicrosoft Azureアカウントを作成する必要があります。アカウントを作成後、Azureポータルにログインして、Speech Serviceを有効化します。
2. Speech Serviceのリソース作成
1.Azureポータルにログインし、「作成」ボタンをクリックします。
2.「リソースの作成」ページで「Speech」を検索し、「Speechサービス」を選択します。
3.「リソースグループ」「リージョン」などの情報を入力し、リソースを作成します。
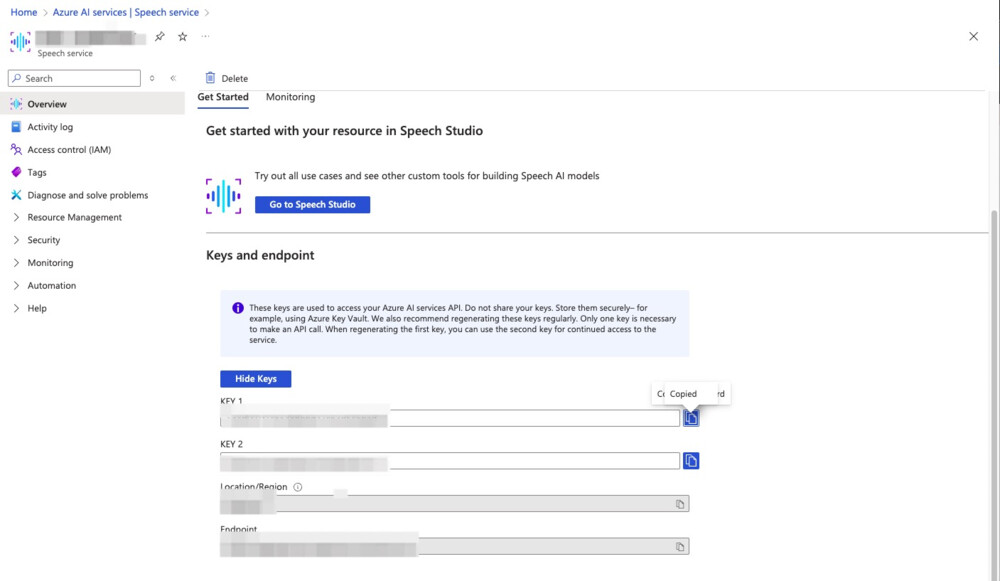
4.作成したSpeechリソースの「キー」と「エンドポイント」を取得します。これらは後でAPIを利用する際に必要になります。
3. 日本語音声の文字起こし(Speech-to-Text)
次に、日本語の音声データをテキスト化(文字起こし)する手順を説明します。
1.Speech SDKのインストール
まず、Azure Speech SDKをインストールします。複数のプログラミング言語向けのSDK利用可能ですが、今回はPythonを使用した例を示します。Python環境に以下のコマンドでSDKをインストールします。
pip install azure-cognitiveservices-speech
2. 文字起こしのサンプルコード
以下は、Azure Speech Serviceを使って音声ファイル(日本語)を文字起こしするPythonのコード例です。
import azure.cognitiveservices.speech as speechsdk
# サブスクリプションキーとリージョンを設定
speech_key = "YOUR_SPEECH_KEY"
service_region = "YOUR_SERVICE_REGION"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
speech_config.speech_recognition_language = "ja-JP"
# 音声ファイルの設定
audio_input = speechsdk.AudioConfig(filename="audio_file.wav")
# Speech recognizerの作成
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
# 認識結果の出力
def recognized(evt):
print(f"認識結果: {evt.result.text}")
# 認識イベントの設定
speech_recognizer.recognized.connect(recognized)
# 文字起こしの実行
print("文字起こしを開始...")
speech_recognizer.start_continuous_recognition()
input("終了するにはEnterキーを押してください...")
上記のコードでは、audio_file.wavという日本語の音声ファイルを指定し、リアルタイムでその内容がテキストとして出力されます。
Azure Speech Service SDKで認識可能な音声ファイルの形式は、デフォルトではwav形式のみです。上記のサンプルコードも扱えるファイル形式はwav形式のみとなっています。それ以外のファイル形式を扱えるようにする場合は、GStreamerを使用する必要があります。
圧縮されたオーディオ入力を使用する方法
文字起こし製品の正確性を測る指標として、単語誤り率(Word Error Rate: WER)や文字誤り率(Character Error Rate: CER)というものがあります。
テストで使用した音声ファイルは、ナレーターの方が読み上げた音声で、「えーと」「あの」などのフィラーが無かったためAIとしても判別しやすいものだったこともありますが、単語誤り率や文字誤り率はかなり低いものでした。
・サンプル1(53単語 96文字):単語誤り率、文字誤り率共に0%
・サンプル2(93単語 162文字):単語誤り率、文字誤り率共に2%
・サンプル3(58単語 88文字):単語誤り率3%、文字誤り率5%
4.テキストを日本語で読み上げる(Text-to-Speech)
次に、文字起こしされたテキストや、事前に用意した原稿を日本語で音声合成し、読み上げさせる方法をご説明します。
以下は、Azure Speech ServiceのText-to-Speech機能を使ってテキストを日本語で読み上げるコード例と、サンプルコードで生成したmp3形式の音声ファイルです。
コード内ではSSMLを利用して定義していますが、音声のスタイルやトーンは、カスタマイズ可能です。日本語の声質も選択でき、ビジネス向け、ニューススタイル、感情表現など多様な音声表現に対応しています。
Speech Synthesis Markup Language (SSML) overview
こういった機械音声の日本語読み上げは、以前はイントネーションや声質の面でどうしても違和感がありました。
しかし、今回試した範囲では、機械音声モデルによって差はあるものの、以前よりも違和感は少なく聞くことができました。
import azure.cognitiveservices.speech as speechsdk
# 1. SpeechConfigの設定
speech_key = "YOUR_SPEECH_KEY"
service_region = "YOUR_SERVICE_REGION"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
# 日本語の音声合成を指定
speech_config.speech_synthesis_voice_name = "ja-JP-NanamiNeural" # 日本語のNeural音声
# 2. 音声スタイルの定義
# Emotionを指定する場合
ssml_text = """
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="ja-JP"><voice name="ja-JP-NanamiNeural"><s /><mstts:express-as style="customerservice">本日はお集まりいただき、誠にありがとうございます。ただいまより、会議を始めます。</mstts:express-as><s /></voice></speak>
"""
# 3. 音声の出力先(スピーカー)
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
# 4. Speech Synthesizerの作成
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
# 5. SSMLを使って合成音声を生成し、再生する
result = speech_synthesizer.speak_ssml_async(ssml_text).get()
# 6. エラーチェック
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("音声合成が完了しました。")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"音声合成がキャンセルされました。理由: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"エラー詳細: {cancellation_details.error_details}")
5. Web/CLIツール
ここまででSDKを利用したコードを実行して文字起こしやテキストを読み上げる方法をご紹介しましたが、AzureではSpeech StudioやSpeech CLIを利用することで、コードを書かなくてもテキストの文字起こしやテキストの読み上げを体験することができます。
個人的にはWebから操作可能なSpeech Studioが便利でしたが、一部Web上のボタンを押しても反応がなかったりしたので、今後の改善が期待されます。
Speech Studio
Speech CLI
まとめ
Azure Speech Serviceを利用すれば、会議の音声を簡単に文字起こししたり、事前に原稿を用意してその内容を機会音声として読み上げさせることができます。
Speech-to-TextとText-to-Speechの両機能を組み合わせることで、リアルタイムでの音声処理や会議の記録、視覚障害者へのサポートなど、多方面で業務効率化や課題解決に役立てることができるでしょう。
私もこれらの音声サービスについて学習する中で、業務効率化のアイデアが浮かんできたので今後実践していきたいと思います。
関連サービス
Microsoft Azure
Microsoft Azureは、Microsoftが提供するパブリッククラウドプラットフォームです。コンピューティングからデータ保存、アプリケーションなどのリソースを、必要な時に必要な量だけ従量課金で利用することができます。
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



