フォーム読み込み中


こんにちは、ソフトバンク株式会社 BeyondAI推進室 R&D推進部の松永です。
今回は音声処理AIの研究動向を把握するために、2025年4月開催の「ICASSP2025」について調査を行いました。
- ICASSP2025の論文の傾向などを分析してレポートしています
- 音声AIの最新研究動向が気になる方向けの記事です
- 最新技術キャッチアップのきっかけになると嬉しいです
1. ICASSPとは
ICASSP(IEEE International Conference on Acoustics, Speech, and Signal Processing)は信号処理における世界最大規模の国際会議です。今回で50回目の開催となります。ICASSP2025の投稿数は6,947本、採択率は45.3%であり、3,145本が採択されました。ICASSPやInterspeechの採択率は毎年50%前後となっており、CVPRやAAAIなどの他AI系の国際会議に比べて採択率が高い傾向にあります。
※Interspeech: 音声言語処理の分野で世界最大規模の国際会議
2. 研究トレンド
この章では、採択された論文を調査し、ICASSP2025の研究トレンドを分析していきます。
採択論文に含まれる単語の出現頻度
採択論文のタイトルから研究トレンドを分析します。以下はICASSP2024とICASSP2025のワードクラウドの図です。文字が大きいほど出現頻度が高いことを示しています。
※ “speech”など、傾向が読み取りづらく上位の出現数の単語は一部除外しています。
ワードクラウド (ICASSP2024)

ワードクラウド (ICASSP2025)
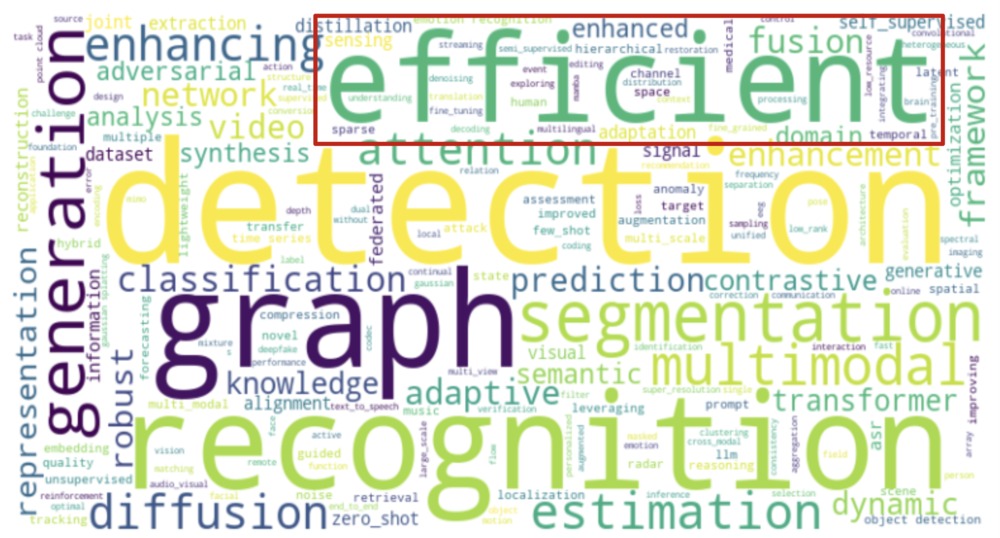
出現頻度の上昇が顕著なefficientについて動向を整理します。
efficient
昨年と比べて「efficient」の出現数が113→175と増加しました。この増加は、LLMで注目されたMixture of Expertsを用いた研究[*1]や少ないステップで拡散モデルの推論を行う研究 [*2]、新しいネットワークアーキテクチャの登場 [*3]など、効率的なモデルを目指した多様な研究の増加が要因だと考えられます。
急上昇ワード
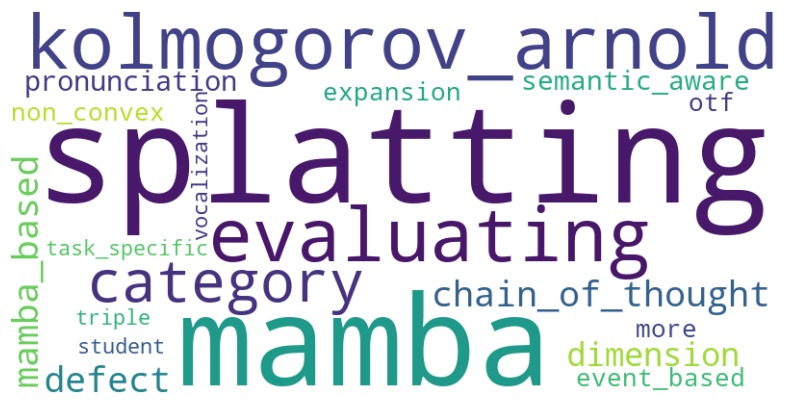
続いてICASSP2024では出現しておらず、ICASSP2025から新たに出現した単語から作成したワードクラウドを以下に示します。
次にタイトル出現件数の対昨年増加率の高いワードをグラフで示します。値はICASSP2024とICASSP2025の出現数の変化を表しています。
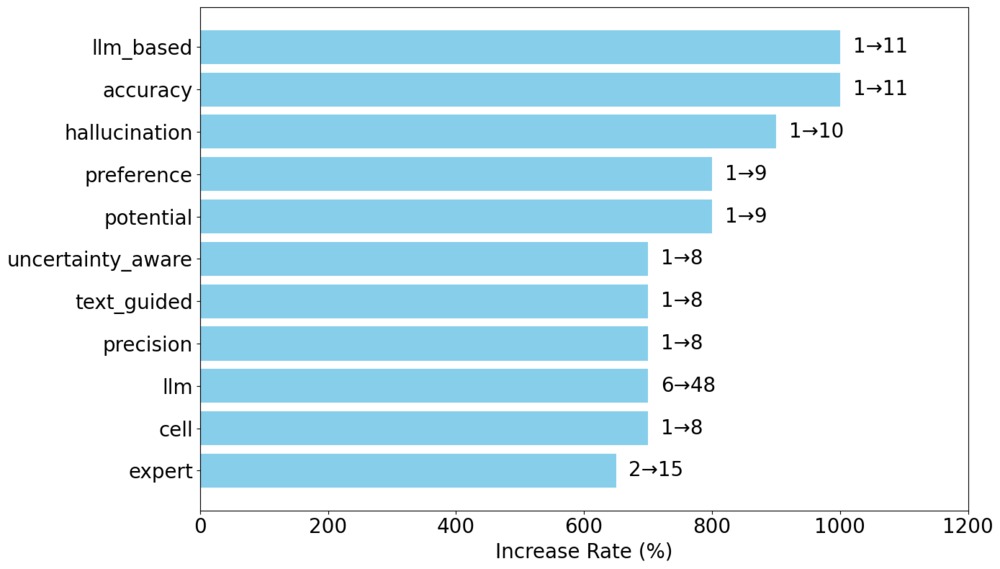
これらの結果から研究動向を整理します。
Mamba・Mamba based
Mambaは2023年に発表されたネットワークアーキテクチャです。状態空間モデル (SSM) をベースとしており、学習時はTransformerのように並列に演算が可能です。推論時はO(n)の計算オーダーで動作します。計算コストを抑えつつ、長期の情報を保持できるという点から、近年注目を集めています。
時系列データとの相性が良く、音源分離[1]・音声強調[2]・音声認識[3]など様々な音声処理分野に応用されています。
Kolmogorov Arnold Network
Kolmogorov Arnold Network (KAN) は機械学習分野のトップカンファレンスであるICLR2025で採択されたネットワークアーキテクチャです。
従来のMLPでは線形変換の重みを最適化し、活性化関数等の非線形変換は固定されていました。これに対し、KANではB-スプライン曲線のパラメータを可変にすることで、非線形変換を学習によって最適化することができます。これにより、少ないパラメータ数で高い表現力を持つモデルが構築できる可能性があります。
ICASSP2025では音声強調[*1]・音声合成[*2]などの分野で論文が採択されています。
LLM・LLM based
大規模言語モデルの「LLM」・「LLM-based」をタイトルに含む研究が増加しています。音声処理分野では音声認識[*1]・感情認識[*2]のような特定のタスクに応用した研究に加え、様々なタスクを解くための汎用的なモデルを目指した研究[*3]も行われています。
3. 注目論文
この章では、ICASSP2025に採択された研究の中から、上で分析した研究動向に即した研究や、今後の音声処理AIの発展に影響を与える可能性がある研究を紹介します。
こちらの研究はLLMを用いた音声認識モデルで、長い音声を処理した際に精度が下がる問題に対してアプローチした研究であり、ICASSP2025のBest Industry Paperに選出されました。
コアアイデア
LLMを用いた音声認識モデルは、長い音声を処理することに適していません。具体的には以下の点で課題があります。
学習データよりも長い音声が入力された時に、認識の精度が低下する。
入力音声の長さによって、Transformer層の計算量が増加する。
Attention機構の計算時に全てのフレームを参照するため、リアルタイム処理の際に遅延が増加する。
この論文では、音声を短く区切り、Attention機構の計算を限られた受容野で行うことで、長い音声に対して頑健なモデルを構築し、計算量・遅延も改善しています。
提案モデル
モデルの概要を以下に示します。
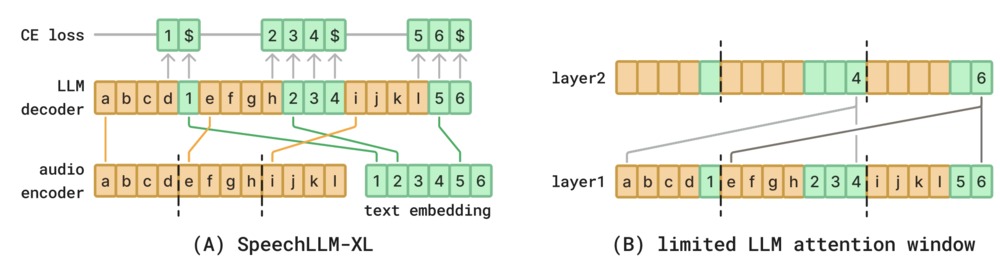
(A)モデルの全体図です。入力音声を短く区切って処理することにより、学習データに含まれていないような長い音声に対しても認識精度を保つことができます。(B)はattention機構の受容野についての図です。限られた範囲の情報のみを参照することで、長い音声を処理する際の課題を緩和しています。
結果
既存研究との比較を以下に示します。
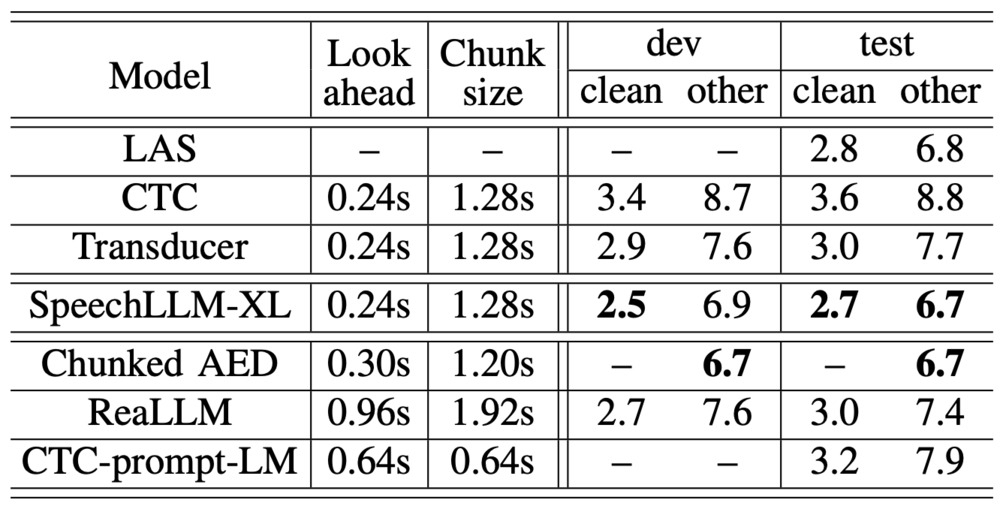
多くの指標で提案手法のSpeechLLM-XLが最も良いスコアとなっています。Chunked AEDは提案手法と同様に入力音声を短く区切って処理する手法で、提案手法と同程度の性能を示しています。主な違いは、Chunked AEDがEncoder-Decoderアーキテクチャを採用しているのに対し、提案手法では、Decoderのみのアーキテクチャを採用している点です。これにより、事前学習されたLLMとの統合が容易となります。
こちらの研究はノンネイティブの発音をネイティブの発音に変換する研究です。学習データを工夫することで、聞き取りやすい声に変換するタスクや感情を変換するタスクなど様々な変換タスクに応用できる可能性があります。
コアアイデア
発音・アクセント変換の学習では、時間関係がアライメントされたノンネイティブ音声とネイティブ音声のペアデータを使用することが望ましいですが、そのような音声データの収集は非常に困難です。こちらの研究では、テキストから音声を合成するTTS技術を用いて時間関係がアライメントされた正解データを生成することによって、収集が困難なペアデータを作成しています。
提案モデル
モデルの学習は2段階で行われます。
1段階目の学習方法を以下に示します。
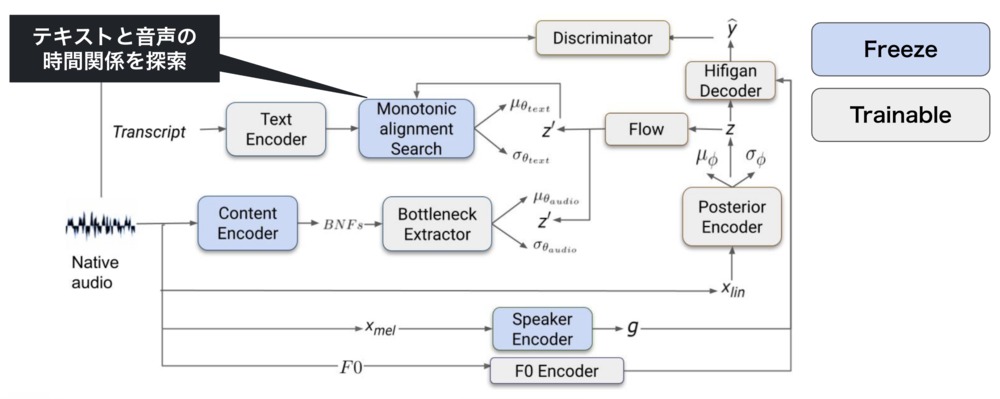
1段階目では、ネイティブ音声を用いてTTSモデルの学習および音声変換モデルの事前学習を行います。
続いて2段階目の学習方法を以下に示します。
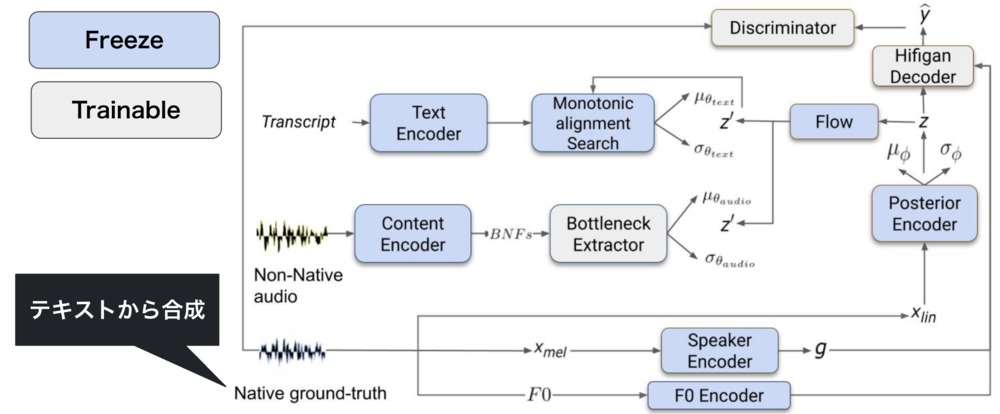
2段階目では、ネイティブ音声で学習されたTTSモデルを固定し、ノンネイティブ音声とペアになる正解データを生成します。次に合成した正解データを用いてノンネイティブ音声からネイティブ音声に変換するモデルを学習します。
結果
変換前のノンネイティブ音声やBaselineとの比較を以下に示します。
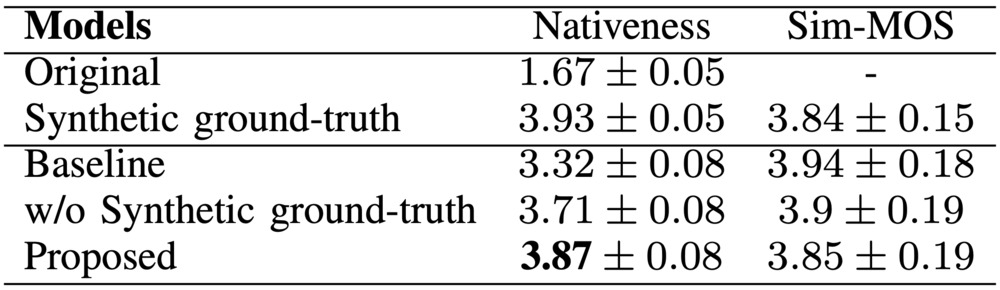
ここで、Baselineは1段階目の学習のみを実施したモデルとなります。Content Encoderが音声認識タスクを解けるように学習されており、アクセントや話者に依存しない特徴量を抽出しています。これにより、1段階目の学習を終えた時点でアクセント変換が可能なため、こちらをBaselineとしています。また、Nativenessはネイティブさ、Sim-MOSは入力音声の話者の類似度を表しています。結果を見るとテキストから合成したネイティブ音声を正解とすることで、変換結果のネイティブさが向上していることが分かります。一方、話者の類似度は低下しています。こちらは、テキストから合成した音声の話者の類似度が低いことが要因として考えられます。
4. 著名な研究者による講演
Plenary Talksと呼ばれるセッションでは各分野の著名な専門家が講演を行います。ICASSP2025では7名の方が登壇されました。その中でも今後の音声処理AI研究への影響が大きいと考えられる講演を紹介します。
Bridging Generative AI and Statistical Signal Processing
講演者: Dr. Ahmed H Tewfik (Fellow IEEE)
こちらの講演では、生成AIモデルと信号処理のつながりについて語られました。
具体的には、以下の3つの内容が紹介されました。
- Transformerの中間層を信号としてみなし、信号処理を適用することで、学習の収束速度や精度が向上した[*1]。
- Mambaのアーキテクチャの理論的背景として、連続関数で定式化されている微分方程式を離散化するために、信号処理のゼロ次ホールドが用いられている。
- Diffusionで行われているノイズ除去は、信号処理でもよく利用されており、逆拡散過程がフィルタリング処理に類似している。
これらの内容を通じて、講演者は1980年代から1990年代に提案されたような古典的な信号処理手法が最新のニューラルネットに応用できる可能性があることを主張しました。
From Dictionaries to Language Transparence
講演者: Prof. Alexander Waibel (Carnegie Mellon University)
こちらの講演では講演者のAlexander Waibel氏が、音声翻訳技術の進化と現状の課題について、自身の40年以上にわたる研究の歩みとともに解説しました。
Alexander Waibel氏は1980年代に音声認識の研究を開始し、当時主流だったルールベースの手法に限界を感じ、ニューラルネットを用いた研究に着目しました。1990年代では計算コストの低いHMMが主流でしたが、Alexander Waibel氏はニューラルネットの可能性を信じ続けました。時代とともに計算機の性能が向上し、2016年には対訳データが無い言語間の翻訳が可能となる中間言語を導入した、多言語翻訳システムを提案しました。
現在の音声翻訳の課題としては、翻訳された文章が冗長で読みにくいこと、対応できる言語が約100言語に限られマイナー言語への対応が不十分であること、唇の動きなど視覚情報を活用するマルチモーダル対応が不足していること、さらに周囲で複数の会話が行われている環境では認識精度が大きく低下することが挙げられました。
5. まとめ
今回はICASSP2025の調査、動向を整理しました。今年は、LLMと組み合わせた研究や、Mamba・KANなどの最新のアーキテクチャを用いた効率的なモデルの研究が増加していることが分かりました。AAAI2025でも同様の傾向が見られており、音声処理の分野のみならず、様々な分野で効率的なモデルを目指した研究が進められている事が分かりました。
本記事をご覧になり、各論文や技術にご興味を持っていただければ幸いです。引き続きトップカンファレンスの調査と分析を続けてまいりますので、今後ともよろしくお願いいたします。
おすすめの記事
条件に該当するページがございません



