フォーム読み込み中


ソフトバンク株式会社 BeyondAI推進室 R&D推進部の町田です。
この度、2025年6月11日〜6月15日に開催されたCVPR 2025にオンラインで参加しました。本記事では、CVPR 2025で得られた最新のAI研究動向や注目の論文を紹介します。
- AIの最新研究動向が気になる方向けの記事です
- CVPR 2025の論文の傾向などを分析してレポートしています
- 画像・動画生成や3D再構成といった既存の主軸に加え、マルチモーダル化が急速に進んでいます
1. CVPRとは
CVPR(IEEE/CVF Conference on Computer Vision and Pattern Recognition)は、コンピュータビジョンとパターン認識の分野において非常に影響力の大きい会議の一つであり、今回で42回目となります。
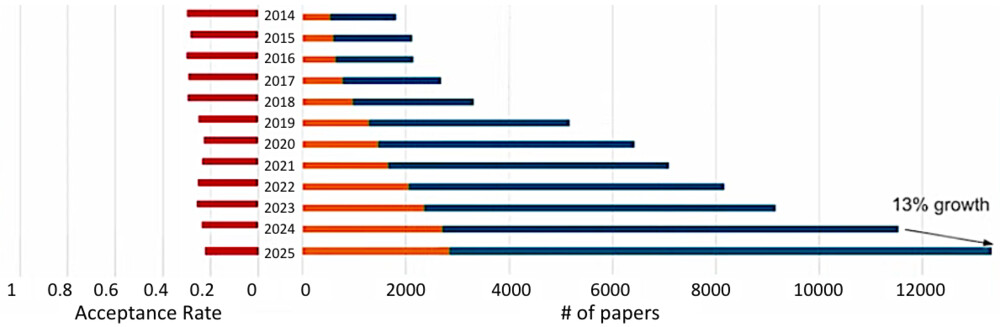
CVPR 2025に投稿された論文数は13,008本、採択数は2,872本、採択率は22.1%です。CVPR 2025は、昨年までと比較すると最も低い採択率となり、例年以上に難易度が高かったと言えます。(参考)
こちらのグラフは、各年の論文数(青)、採択数(オレンジ)、採択率(赤)の推移を示しています。投稿論文数は年々増加しており、採択率は25%前後で推移していることがわかります。
2. 研究トレンド
この章では、会議のOpening Remarksで公表された情報に基づき、CVPR 2025の研究トレンドを分析します。
論文の傾向
下の図は、各トピックの論文数を示したグラフです。
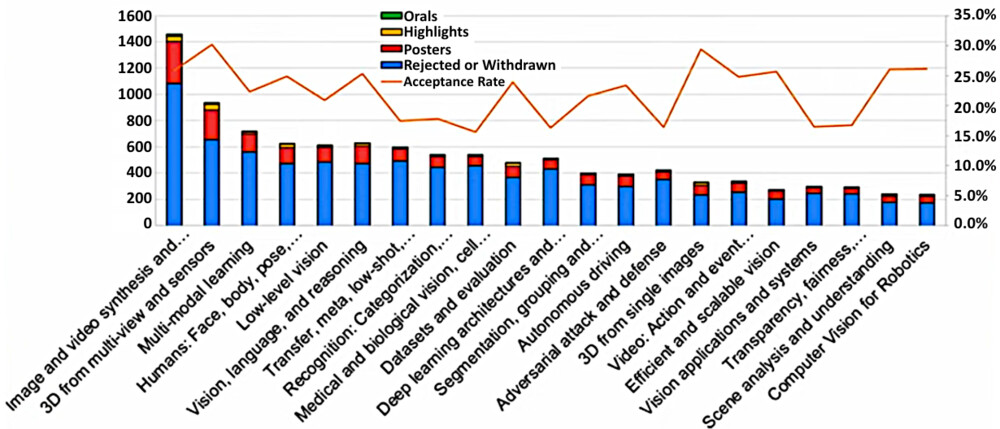
トピックのトップ3は以下の通りです。
- Image and video synthesis and generation(画像・動画の合成および生成)
- 3D from multi-view and sensors(複数視点とセンサーからの3D化)
- Multi-modal learning(マルチモーダル学習)
CVPR 2024と比較すると、1位は引き続き 画像・動画の合成および生成、2位も 複数視点とセンサーからの3D化 で変化はありません。一方で、 マルチモーダル学習 は9位から3位へと大きく順位を上げています。また、Vision, language, and reasoning(ビジョン・言語の推論)も上位に位置しており、マルチモーダルへの関心が高まっていることがうかがえます。1位から3位までの各トピックについて動向を整理します。
画像・動画の合成および生成
画像・動画の合成および生成では、出力の高品質化から、生成される画像の多様性や公平性の評価まで、幅広い課題が扱われています。拡散モデルを中心とした生成技術の進化が加速しており、テキスト情報を中心とした条件付けによって出力の制御性と高精度化が進んでいます。例を以下に示します。
- ロボットの行動と周辺環境の画像を元にナビゲーション動画を生成する手法
- 画像編集のためのデータセット構築と拡散モデルの提案
- 画像生成モデルの多様性・公平性の評価
- 収集困難な医療画像を高精度で生成する手法
- 詳細なテキスト記述を反映可能な人物画像生成手法
例で示したように、人物画像や医療画像など、適用先は多岐にわたることがわかります。特に、4本目の医療領域における高品質な画像生成は、データの収集が困難な他の分野にも応用可能性があることから、本記事の後半で詳しく紹介します。
複数視点とセンサーからの3D化
複数視点の画像やセンサーから取得した情報をもとに3Dモデルを生成する技術は、3D再構成とも呼ばれます。傾向として、時間的情報の活用や動的シーンの取り扱いなど、より現実に即した課題設定に基づく3D再構成手法が多く見られました。例を以下に示します。
3D再構成においては、カメラ姿勢推定や点群推定など複数の処理が必要です。1本目の論文はこれら複数のタスクを同時に扱うことが可能で、高速かつ高精度であることから、本記事の後半で詳しく取り上げます。
マルチモーダル学習
マルチモーダル学習では、画像・動画・言語・音声といった複数のモーダルを統合し、さまざまなタスクに取り組みます。特にコンピュータビジョンと言語処理を組み合わせた手法が多く見られ、オブジェクトトラッキングや動画字幕生成といった複雑なタスクへの応用が加速している印象です。以下にその一例を示します。
- 画像・テキストペアを用いた大規模マルチモーダルモデルの学習
- 画像の埋め込みに拡散過程を採用した高精度なマルチモーダルモデル
- RAGで検索した類似画像を活用するマルチモーダルQAモデル
- 時間情報を考慮したマルチモーダルモデルのオブジェクトトラッキングへの活用
- 音声認識書き起こしデータを活用した動画字幕生成モデル
いずれのタスクにおいても、今後の発展には基盤モデルの高精度化が重要です。大規模マルチモーダルモデルの高精度化に取り組む1本目の論文を、本記事の後半で詳しく紹介します。
3. 注目論文
この章では、CVPR 2025に採択された論文の中から、今後のAIの発展を考える上で重要だと考えられる論文を3本紹介します。掲載画像は、それぞれの論文または論文のプロジェクトページから抜粋しています。
画像群から3D情報(カメラの位置・向き・奥行きなど)を予測するモデルを提案した論文です。提案手法は、シーンごとに最適化を行う必要がなく、わずか数秒で高品質な3D再構築を実現可能な特長を持ちます。
背景
コアアイデア
この論文では、トランスフォーマーモデルである「Visual Geometry Grounded Transformer(VGGT)」を導入し、画像枚数や視点に依存せずに、カメラパラメータ・深度・3D点群・トラッキングのマルチタスク処理を実現しています。最適化処理を省略しつつ高精度な結果を得られるよう、大量のデータで事前学習を行い、下流タスクへの活用が可能であることを示しました。
提案モデル
以下の図は、VGGTのアーキテクチャ全体と、各モジュールが担う役割を表現しています。VGGTは複数枚の画像を入力として、カメラパラメータ、複数視点における深度、空間的に整合した3D点群、さらには時間的に一貫性のあるトラッキングを同時に出力します。標準的なトランスフォーマーをベースに構成されており、画像ごとのFrame Attentionと、画像間のGlobal Attentionを適用することで高精度かつ効率的な3D情報の抽出を実現しています。
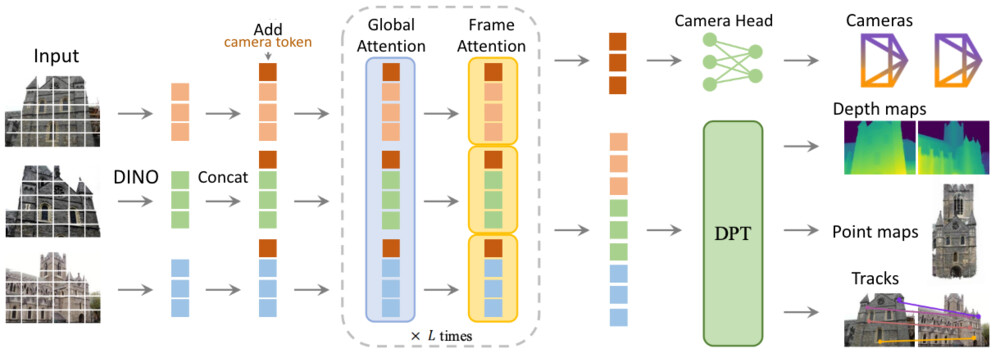
VGGTの学習には、屋内外のシーン、実写と合成データの両方を含む、多様な環境にまたがる大規模な3Dアノテーション付きデータセットを活用します。これにより、現実世界の幅広い状況に対応可能な3D理解能力を獲得しています。
結果
カメラ姿勢推定、点群推定、複数視点における深度推定の3つのタスクに焦点を当てて、それぞれの実験結果を示します。
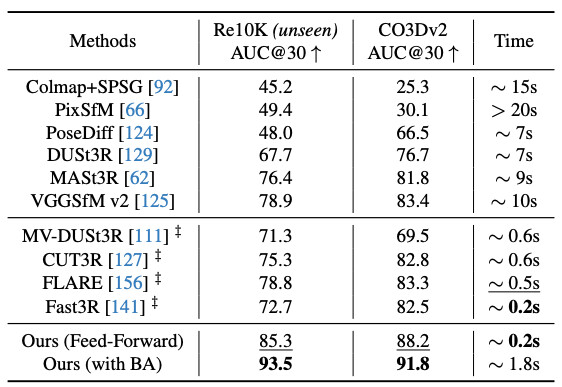
カメラ姿勢推定
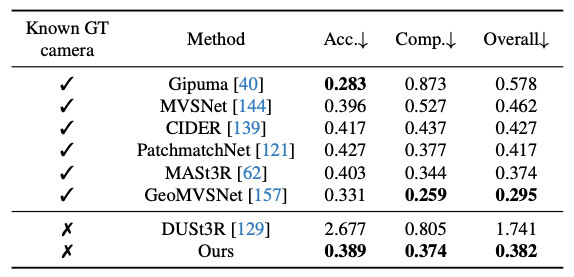
複数視点深度推定

点群推定
各タスクでは、従来手法であるVGGSfM、DUSt3R、MASt3Rなどと比較し、標準的な評価指標を用いて定量的な性能比較を実施しています。カメラ姿勢推定には、画像ペア間で推定した2つのカメラの位置関係の推定精度から導出するAUCを指標として使用します。点群推定および複数視点における深度推定では、推定結果の正確性(Accuracy)と完全性(Completeness)を評価指標とし、それぞれの再構成品質を定量化します。
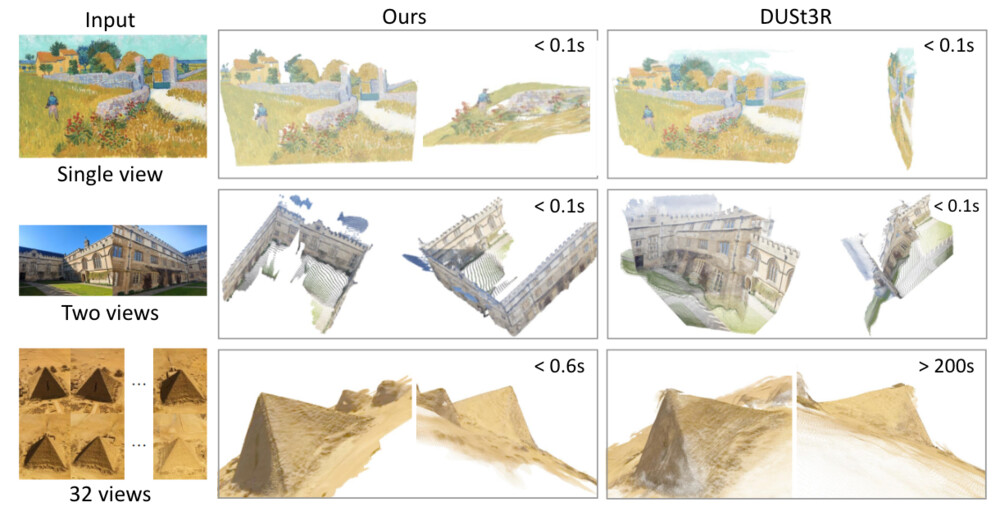
結果として、VGGTはすべてのタスクにおいて従来手法を上回る性能を示し、特にカメラ姿勢推定と点群の再構成において、精度向上と同時に高速化を実現しました。また、複数視点における深度推定においても高い一貫性と精度を保っており、単一のモデルで多様な3Dタスクを高精度に処理可能であることが示されています。
以下の図は、3D再構成結果を可視化しています。従来手法のDUSt3Rと比較して、提案手法のVGGTは非常に高速かつ高精度であることが確認できます。
拡散モデル(Diffusion Models)を利用した画像生成において、ある仮定条件下で想定される画像を高品質で生成する手法を医療ドメインに適用する研究です。
背景
近年、画像生成分野では、拡散モデルが急速に進化し、高品質な画像生成が可能になっています。こうしたモデルの多くはWebで収集可能な一般画像を中心に学習されており、医療画像のような専門的かつデータ量の限られた分野にモデルを適用する場合、分布のミスマッチや条件制御の難しさといった課題が存在します。
コアアイデア
本論文では、拡散モデルに「Latent Drift(LD)」と呼ばれる潜在空間のドリフト項を導入することで、反事実的画像の生成を柔軟かつ高精度で実現する手法を提案します。ここでの反事実的画像とは、例えば「アルツハイマー病に罹患していた場合」や「性別が異なっていた場合」といった、ある仮定条件下での想定画像を指します。LDにより、性別や疾患などの属性を制御した反事実的画像生成を可能にします。
提案手法
以下の図に、本研究で提案されている「Latent Drift(LD)」アーキテクチャを示します。提案手法では、一般画像で事前学習された拡散モデルを活用し、医療画像に特有の分布に適応させるために、潜在空間にドリフト項(δ)を導入します。入力となる画像やテキストは、VAEやU-Netを通じて潜在空間にマッピングされ、ノイズ除去の拡散過程が始まります。ここにLDの中核となる処理が加わります。
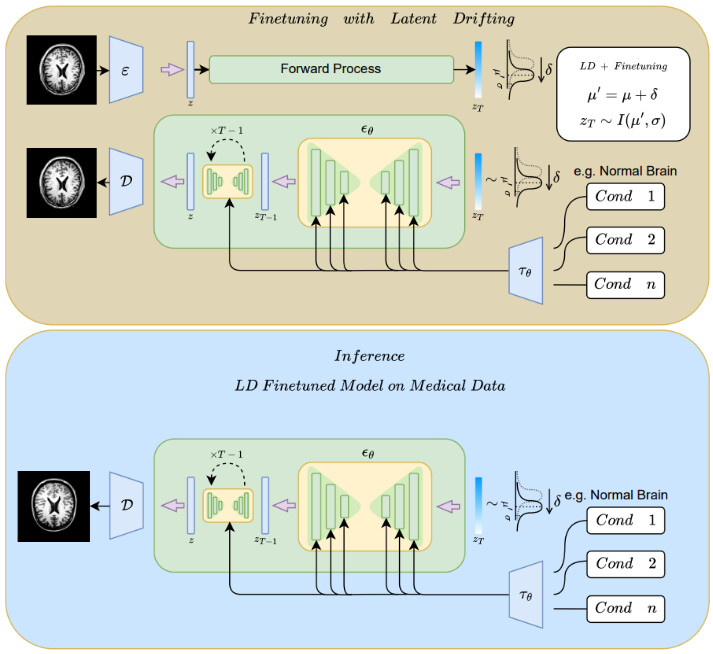
ドリフト項は単なる画像変換ではなく、「ある仮定条件(図中は正常な脳の場合を仮定)」を反映するように最適化されます。この条件付き最適化は、忠実性と多様性のバランスを取るためにmin-max形式で定式化されており、これにより反事実的画像の生成が可能になります。
結果
実験結果を以下に示します。
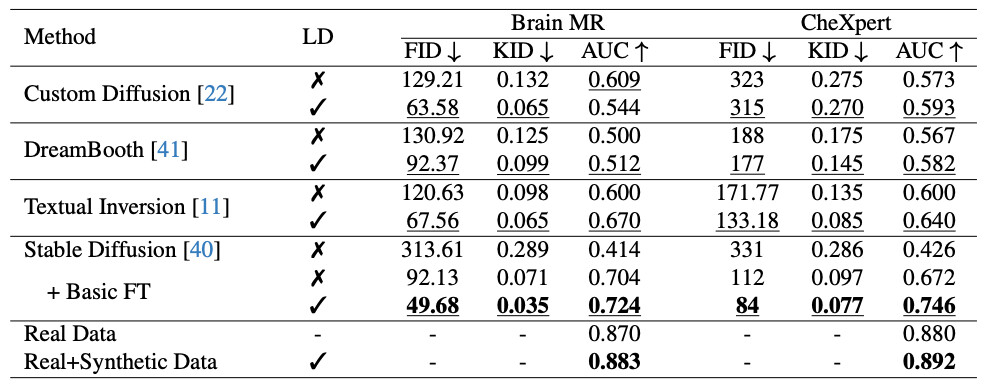
本実験では、BrainMRデータセットおよびCheXpertデータセットを用いて評価を実施しました。表は、各既存の画像生成手法に対して、提案手法のLD(Latent Drift)を導入した場合の精度変化を示しています。生成画像の品質評価には、FID(Fréchet Inception Distance)およびKID(Kernel Inception Distance)の指標を使用しました。さらに、各画像生成モデルによって生成された画像を用いて学習した分類器の、実画像に対する分類精度をAUC(Area Under the Curve)で評価しています。
結果として、提案手法LDを導入することで、生成画像の品質が向上し、さらにその画像を用いた分類器の性能も向上することが確認されました。
Vision-Language Model(VLM)のための学習データセットを収集し、フルスクラッチでVLMを学習して評価を行う研究です。
背景
OpenAIやGoogle、MetaなどのAIリーディングカンパニーが提供するVision-Language Model(VLM)は非常に高い精度を誇りますが、モデル、データ、コードのすべてを公開しているケースは極めて稀です。一方で、パブリックに公開されているVLMは精度面で課題があり、中には非公開VLMから生成したデータを学習に利用しているモデルも存在します。その結果、多くの企業や研究者は、高精度なVLMを構築するためのノウハウやリソースを持ち合わせていないのが現状です。
コアアイデア
この論文では、VLM学習用データセットであるPixMoを収集し、PixMoを用いた学習により高精度なVLMであるMolmoを構築します。さらに、研究コミュニティの発展と活発化を目的として、モデル、データ、コードを公開しました。
提案手法
以下の図は、PixMoに含まれるデータの種類とデータの収集方法、および学習によりMolmoが獲得するスキルを表現しています。画像へのアノテーションにより、キャプション、QA、物体の位置を表現するポインティングをラベリングします。アノテーションは、人間のアノテーターと大規模言語モデル(LLM)により実施します。
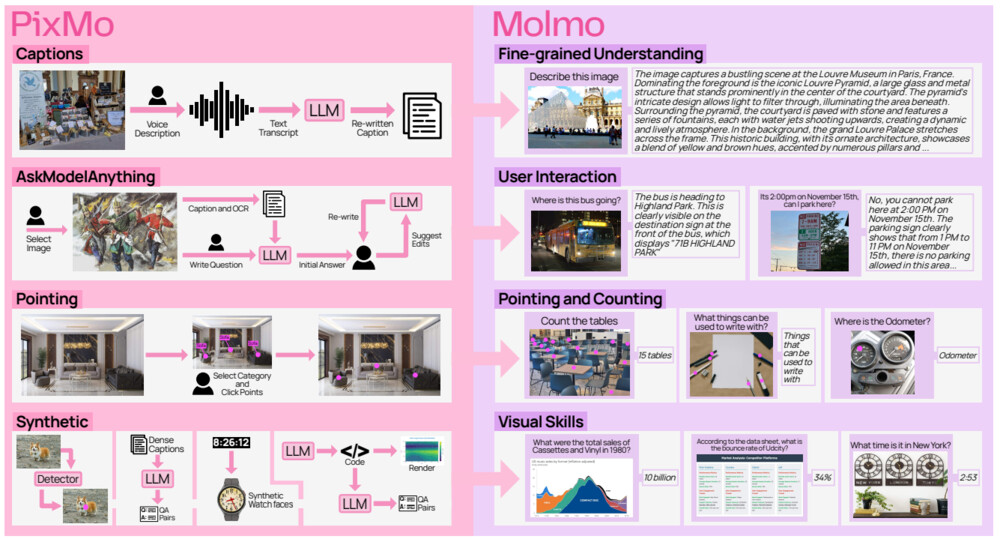
PixMoを利用してMolmoを学習します。Molmoの学習は、事前学習とファインチューニングの2段階で実施します。事前学習では、画像とキャプションのペアを利用します。ファインチューニングでは、QAデータやポインティングデータにより、図に示される複数のスキルを獲得します。
結果
既存モデルとの比較を以下に示します。

表は、上段から順に以下のモデルを表しています。
- APIを通じて推論機能のみを提供している独自開発モデル
- 重みのみが公開され、学習データは非公開のモデル
- 重みと学習データが公開されているモデル
- 提案手法のMolmo
表の Average は11のベンチマークによる評価スコアの平均を示しており、Elo score は人間評価者の嗜好を反映した指標です。いずれも数値が高いほど性能が優れていることを表します。
提案手法のMolmoは、公開モデル群の中でstate-of-the-artを達成しました。特にMolmo-72Bは、11のベンチマークにおける平均精度で最高精度を達成し、Elo scoreにおいてもGPT-4o-0513に次ぐスコアを達成しました。
4. Keynotes
この章では、AIに関わる著名な専門家の講演について紹介します。CVPR 2025では3つの講演が行われました。
Exploring the Low Altitude Airspace: From Natural Resource to Economic Engine
講演者:Harry Shum(香港科技大学)
本講演のテーマは、「低高度空域」と呼ばれる高度1000m以下の空域におけるドローンの利活用についてです。Shum氏はまず、近年のドローン技術の進歩と、それに伴って発展しているドローンサービスの例を紹介しました。その一方で、今後ドローンをさらに有効に活用するためには多くの課題が存在することも説明しました。例えば、現在のドローンやヘリコプターは、高度を測定する際にそれぞれ異なる指標を用いており、これを統一しなければ衝突の危険性があります。このような課題を解決し、ドローンを安全かつ効率的に利活用するための「SILAS」というシステムの開発を紹介しました。このシステムでは、ドローンの飛行を一元的に管理し、地形や天候などの条件に加えて、他のドローンの飛行情報も活用することで、重大なインシデントを回避できると説明しました。遠くない未来にドローンが人を運ぶ時代が到来することを主張し、そのためにもSILASのような管理システムの必要性を訴えました。
The Llama Herd of Models: System 1, 2, 3 Go!
講演者:Laurens van der Maaten (Meta AI)
2025年4月にリリースされたLlama4の開発に関する技術紹介、およびAIの今後の展望についての講演です。Llama4では、複数の専門家モデルを組み合わせるMixture-of-Expert(MoE)と呼ばれるアーキテクチャを採用しており、これにより高い性能と計算効率の両立を実現しています。Maaten氏は、教師なし学習による事前学習に加えて教師あり学習も取り入れ、指示に従う能力を備えたモデルを構築したと説明しました。さらに、計算並列化によるスケーラビリティの向上、コード生成や画像処理といった複数の能力の統合について紹介しました。AIの今後の展望については、人間とAIの協調的かつ相補的な相互作用によってAIはさらに発展していくとして、実現のためには、特化型AIを誰もが開発可能な汎用性、他のエージェントと疎通するためのネットワーク、効率的なコミュニケーション、そしてAIによる意図や感情の理解が必要になると主張しました。
Gemini Robotics, Bringing AI to the Physical World
講演者:Carolina Parada (Google DeepMind Robotics Team)
2025年3月に発表されたGemini Roboticsを中心とした、汎用ロボットについての講演です。現在、単純作業の自動化をはじめ、製造業や海底探索など、ロボットは様々な分野で活用されています。一方で、従来のロボットは、操作対象の色やサイズの変化への対応が困難であったり、複雑な操作性のため専門家でなければ扱うことができないなどの欠点がありました。本講演において、Parada氏は、Gemini 2.0を基盤として構築したVision-Language-Action(VLA)モデルであるGemini Roboticsを紹介しました。このモデルは、高い適応力と実用性、安全性を兼ね備えたロボットであると説明しました。汎用的かつ責任あるロボットにおいて、安全性を重視した設計が不可欠です。安全性の一例として、たとえば「ヒーターの上に可燃物を置いてはいけない」といった常識に基づいた判断能力が求められます。ロボットにもこのような人間の常識的判断を取り入れることが、安全性確保において重要であると述べました。また、今後のロボットの発展と利活用に向けて、学習していない未知の環境への対応能力がより一層求められると主張しました。
5. まとめ
今回はCVPR 2025にオンラインで参加し、その聴講内容と動向を整理しました。
画像・動画の合成および生成、3D再構成、マルチモーダル学習が主要なトピックとして注目を集め、実応用を意識した研究や複雑なタスクに取り組む研究が数多く見受けられました。注目論文では、複数タスクを高速・高精度に処理可能な3D再構成モデル、高度な条件制御が可能な医療画像生成、高品質なアノテーション付きデータで学習された高性能VLMを紹介しました。Keynotesでは、AIの活用先や社会との関わり方に焦点が当てられ、今後のAIの発展に向けた方向性と課題意識が示されました。今後も、画像・動画の合成および生成、3D再構成が引き続き注目される一方で、マルチモーダル化のトレンドがさらに加速していくと考えられます。
おすすめの記事
条件に該当するページがございません



