フォーム読み込み中
Agentic RAGは従来のRAGの課題をどう解決するか?

TASUIKI事業部 エンジニア
中村 友哉
ソフトバンク株式会社のIoTデバイス開発部門に入社。 エンジニアとして多様なデバイスの開発・検証をリードし、ロボティクスを用いたデバイス検証自動化にて社内表彰。
機械学習領域のバックグラウンドから、2022年から AI開発企業/生成AI導入企業向けデータ作成サービス「TASUKI Annotation」に参画。2023年よりマーケティングチームをリード。
2025年12月1日掲載

ソフトバンク アドベントカレンダー 2025 1日目の記事を担当する中村です。
普段は、RAGの回答精度向上を支援するデータ構造化ツール「TASUKI Annotation」のプロダクトマネージャーをしています。
ChatGPTの普及に伴い、業務での生成AI活用、特に「自社独自のデータをRAGで扱いたい」という要望が急増しています。しかし、そこで必ずと言っていいほど直面するのが「回答精度の壁」です。「思ったような精度が出ず、RAGの本導入に踏み切れない」というご相談も後を絶ちません。
そこで本記事では、RAGの実用化における課題と、それを乗り越える新たなアプローチである「Agentic RAG」のコンセプト・アーキテクチャについて詳しく解説します。数多くの現場課題に直面してきた視点から、技術的背景や実装例も交えながらその有効性を解説します。
- LLMやRAGをこれから業務活用したいと考えている方や企業担当者に向けた記事です。
- 「Agentic RAG」のコンセプト・アーキテクチャについて解説します。
RAGは、大規模言語モデル(LLM)に外部知識を与えて回答の正確性を高める手法です。しかし通常のNativeなRAGでは、質問に対しベクトル検索で関連文書を一度だけ取得し、その結果をもとにLLMが回答を生成するという固定的なワンショットな手順に留まります。このような単純なパイプラインには柔軟性がなく、複雑な要求に対処しきれないという問題があります。
本記事では、Native RAGの具体的な課題と、それらを克服するAgentic RAGのコンセプト・アーキテクチャについて解説します。研究論文や公式ドキュメント、企業の技術ブログをもとに、Naive RAGからAgentic RAGへの進化と価値を体系的に解説します。
Native RAGの限界
NativeなRAGアプローチには以下のような制約があります。
検索が一発勝負であること
一度のクエリで上位N件の文書を取得するだけなので、最初の検索結果に依存しすぎます。もし初回の検索で重要な情報を拾い損ねれば、その後に、訂正する機会がありません。実際、Native RAGはリコールが低い(関連情報を網羅的に引き出せない)上に、精度も低い(文脈とずれた断片が混入する)傾向があります。その結果、回答に不正確さが残ったり、モデルが情報不足から幻覚(誤情報の生成)を起こすリスクが高まります。ユーザーの質問が曖昧だと対処困難であること
単純なRAGでは質問をそのままベクトル検索しますが、ユーザーの問いが漠然としている場合、適切な検索結果を得られません。たとえば「有給休暇を見せて」という曖昧な質問では、それが「会社の有給休暇ポリシー」なのか、「自分の残り有給日数」なのか判別が付きません。Native RAGは質問の意味を深掘りせず、一律の検索を行うため、質問の意図を汲み取った検索ができません。また用語の使い方によっては知識ベースにマッチせず、検索結果が得られないこともあります。このように曖昧な質問への柔軟な対応が苦手です。高度な推論やマルチステップの質問に弱いこと
一問一答形式を前提としているため、複数の資料を参照したり、段階的な推論を必要とする問いには対応しにくいです。たとえば「最新の財務データに基づいて市場分析し、専門家の意見も踏まえて結論をまとめて」というような複雑な質問では、一度の検索で全ての情報を得るのは不可能です。また数値計算や外部APIを呼び出すような中間処理が必要なタスク(たとえば現在日時の取得や数式計算)も、固定パイプラインのRAGでは扱えません。結局、Native RAGはマルチホップな推論やツール使用を伴うタスクには非力で、そうした場面ではモデルは答えられなかったり、見当違いな回答を生成してしまうことがあります。
以上のように、Native RAGはシンプルで実装しやすい反面、逐次的な思考や動的な戦略変更ができないため、現実の複雑な質問や、変化する情報に対応するには不十分です。
Agentic RAGとは何か
こうした問題を解決するために登場したのがAgentic RAGです。Agentic(エージェンティック)とは「主体性を持つ」という意味で、LLMを単なる回答生成器ではなくエージェント(Agent)として位置づけ、動的な判断をさせるアプローチを指します。
つまり、Agentic RAGでは、LLM自身が「追加の情報が必要か?」「どのツールやデータソースを使うべきか?」を考えながら対話的・逐次的に処理を進めるのです。以下にNaive RAGとAgentic RAGの違いをまとめます。
Native RAG: 質問に対し一度だけ知識検索し、その結果をLLMに与えて回答を生成します。フローは固定で、LLMは与えられた情報内で答えます。
Agentic RAG: 質問に対しLLMをエージェントとして動かし、途中で追加の検索や外部ツール利用が必要かをモデル自身に判断させます。必要に応じて何度でも情報取得や計算などのステップを挿入し、十分なコンテキストが揃ってから最終回答します。
基本的なRAGが「検索して即回答」なのに対し、Agentic RAGではLLMが自律的に判断し、外部ツールの利用や追加データ収集を挟んでから回答します。この柔軟性により、複数回の反復や対話を要する複雑なワークフローにも対応できるわけです。
言い換えればAgentic RAGは、LLMにプランニングやツール操作といったエージェント的能力を持たせたRAGです。LLMが自身の“思考”を逐次展開し、「次に何をすべきか」「どの情報源を当たるか」を決定しながら問題解決に当たります。たとえば質問が曖昧ならまずサブクエリを立てて検索し、不足情報があれば再度別のデータソースから取得し、ある程度揃ったらそれらを総合して回答するといった具合に、検索と生成をインタリーブ(交互に挟み込む)して最適解を探ります。このプロセスではLLMがまるで人間のように「資料Aだけでは不十分だから資料Bも調べよう」「この部分は計算が必要だから電卓(ツール)を使おう」といった能動的な判断を行います。
Agentic RAGの概念をもう少し正式に捉えると、「RAGにエージェントレイヤーを組み込んだもの」と表現できます。アーキテクチャ上、基本要素はRetrieval System(検索システム)、Generation Model(LLM本体)に加え、LLMの振る舞いを制御するAgent Layerからなります。エージェントレイヤーが仲介役となり、LLMが単純回答する前に「この質問にはどのデータソースを使うべきか?追加の検索が要るか?」等を決め、必要なら複数の検索や外部システムとの対話を実行します。
NVIDIAの技術ブログでは、これを「RAGをLLMの推論プロセスに統合し、LLMが能動的に情報収集を管理する動的アプローチ」と説明しています。従来のRAGが単なるクイックルックアップ(手早い検索)なのに対し、Agentic RAGは、AIエージェントが検索クエリを最適化し、RAGをツールとして使いこなし、必要に応じて知識を管理する洗練された手法だと説明されています。
以上の特徴から、Agentic RAGを表すキーワードは「動的」「反復的」「自律的」です。一度きりの実行ではなく、LLMが対話とツール使用を駆使してゴールに向かうプランナー兼実行者となる仕組みと言えます。これによってNative RAGの持つ制約、すなわちワンショット検索の限界や曖昧な質問への弱さ、多段推論の不可能といった点を克服し、より知的で柔軟な情報検索・回答システムが実現が可能になるのです。
Agentic RAGはNative RAGの課題をどう解決するか
では、Agentic RAGは具体的にどのように前述の課題を解消するのでしょうか。いくつか重要なポイントに分けて整理していきます。
解決① 情報検索の反復アプローチ
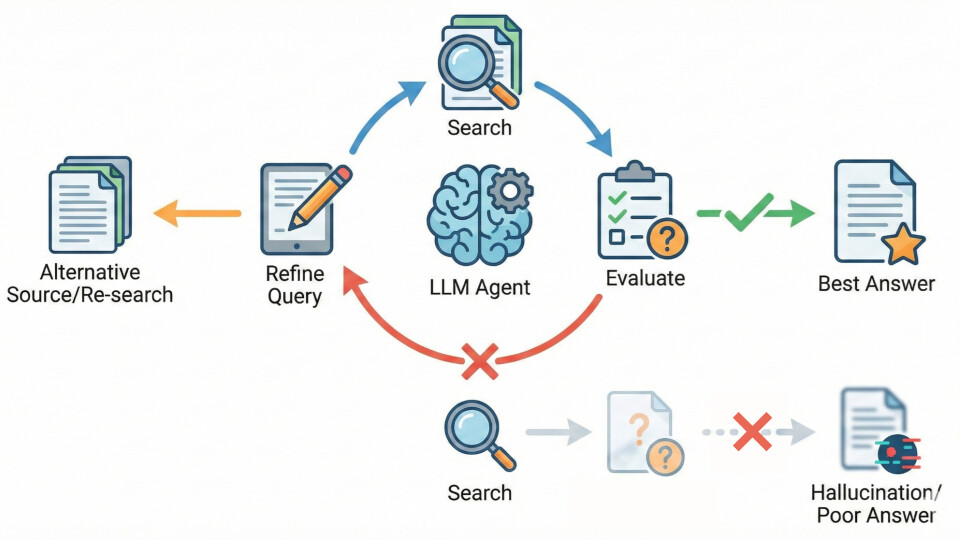
Agentic RAGでは、LLMエージェントが必要に応じて何度でも検索を繰り返すことができます。たとえば初回の検索結果が不十分だった場合、モデルが「まだ情報が足りない」と判断すれば、クエリを修正して再検索したり、別のデータソースにあたったりします。
NVIDIAの解説によれば、このような反復的検索とフィードバックループによって回答精度が向上することが確認されています。単発検索と異なり、「エージェントが回答の妥当性をチェックし、必要ならクエリを書き直して何度も検索し直すことで、最善の答えに近づける」ため、最終的な回答の正確性が大幅に高まるのです。言い換えれば、Agentic RAGは検索のリコールを高め、不要な断片を排除するようLLM自身に試行錯誤させることで、「一度で取り切れなかった情報」を取りこぼさなくします。
この仕組みにより、初回検索に依存したまま誤った回答を出す(いわゆる幻覚や見当外れの回答)リスクも低減します。
解決② 質問の曖昧さへの対応 – クエリの動的な最適化
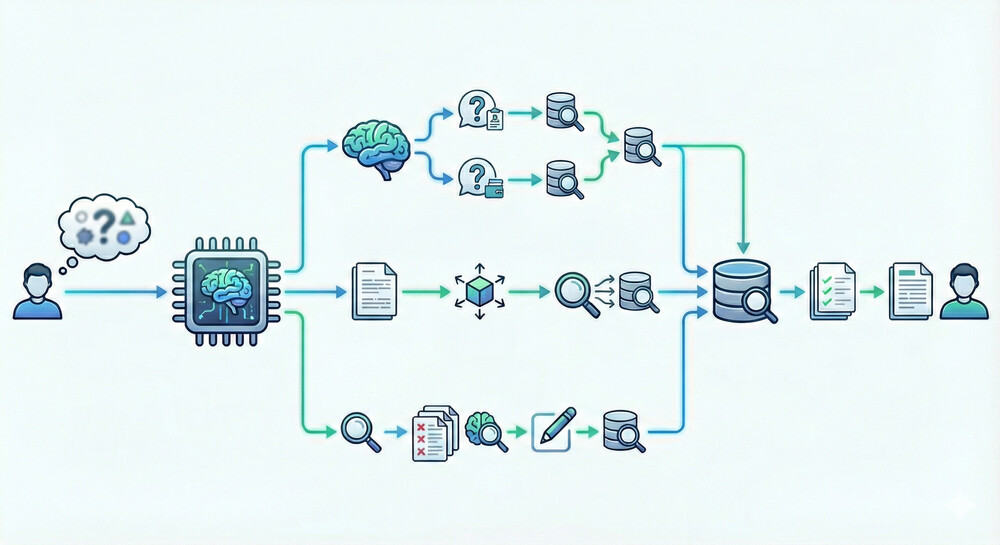
Agentic RAGのエージェントは、ユーザーの質問が不明瞭な場合に、自律的に質問の解釈を試みたり、適切な形に言い換えることができます。
たとえば先の「有給休暇を見せて」という例では、LLMがまず「これは社内ポリシーの質問か、それとも個人の残日数についてか?」と考え、内部で明確化するためのサブ質問を生成することが可能です。 “Self-Ask” 手法では、モデルが自問自答の形で疑問点を分解し、それぞれに検索を行って最終回答につなげるというアプローチが示されています。
また、HyDE(Hypothetical Document Embedding)のような技術では、モデルが最初に質問に対する仮想の回答文書を自力で作り、それをベクトル化して類似文書を検索するという方法で曖昧なクエリのマッチング精度を高めます。HyDEは「ユーザー質問が漠然としている場合、モデルが理想的な回答のイメージを先に生成し、それに近い知識を探す」手法で、実際に曖昧な問い合わせでも関連情報を引き出しやすくすることが報告されています。
さらに、先述のCorrective RAGではLLMが初回検索結果を精査し、少しでも質問と無関係な文書が混じっていれば問い合わせの言い回しを自動で改善してウェブ検索し直す、という手順を組み込みました。
このようにAgentic RAGでは、エージェント(LLM)が質問を理解・変換する役割も果たし、曖昧さを解消するための工夫を自律的に行います。結果として、ユーザーが何を求めているかを正しく捉えた上で適切なデータ取得ができるため、Native RAGが苦手とした曖昧な質問への対応力が飛躍的に向上します。
解決③ 複雑な推論・マルチステップ問題への対処
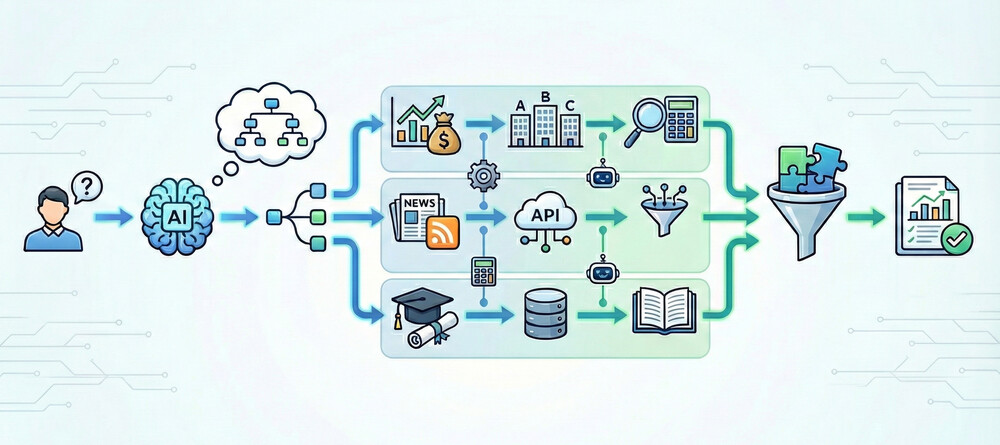
Agentic RAG最大の強みは、高度な推論タスクを複数段に分けてこなせる点です。LLMエージェントは一度のQAにとどまらず、サブタスクに分割して順に解決し、それらの結果を統合することができます。
たとえば「競合企業の最新動向を調査し、自社への示唆を報告せよ」という質問を受けたエージェントは、まず「競合企業A,B,Cの財務データを取得しよう」と判断してそれぞれ検索・集計し、次に「関連ニュース記事も収集しよう」と外部ニュースAPIを叩き、さらに「専門家の意見も欲しい」と論文データベースを参照する――といった具合に、複数の情報源・複数のステップを並行して進めます。必要に応じて別のエージェントを生成して処理を任せたり、計算タスクを外部ツールに委ねたりもしながら、最後にすべての成果を統合して総合的な回答を組み立てるのです。
この「プランニング→実行→統合」というマルチステップ推論能力により、本来であれば人間が何日もかけて行うような調査・分析も、Agentic RAGなら自律的に短時間で遂行できます。
エージェントは複数の文書にまたがる推論や中間計算、外部システムとの対話(例: データベースクエリやAPI呼び出し)を柔軟にこなすため、Native RAGでは不可能だった領域に対応が可能です。こうして高度な推論力と問題解決能力を備えたAgentic RAGは、単純なQAシステムを超えて汎用的なタスク自動化にも応用できるようになっています。
解決④ 回答の検証と改善(自己フィードバック)
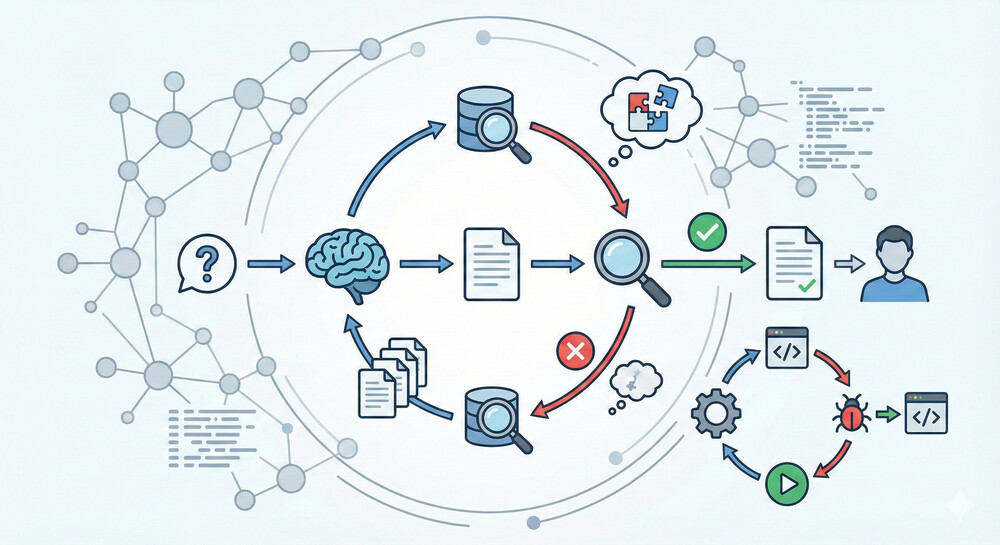
Agentic RAGでは、LLMが自分の出した回答を評価・検証して改善するループを取り入れることも容易です。
たとえばReflection(自己反省)のテクニックでは、モデルが一度回答を生成した後で「この答えは本当に質問に完全に答えているか?」とセルフチェックし、もし不十分な点があれば「何が欠けているか」を洗い出して追加の内部質問を作ります。そして新たな検索クエリを発行して不足情報を取りに行き、回答を補完するのです。これにより回答の正確性・完全性が一層保証されます。実際、n8nのブログではこの仕組みをAnswer Critic(回答批評家)と呼び、エージェントが回答を批評・改善しながら最終的にユーザーへ提示すると説明しています。
さらにLangChain/LangGraphの例では、コード生成エージェントに「生成したコードを実行し、エラーが出たら原因を分析して次の修正に活かす」というセルフフィードバックループを組み込んでいます。このような自己改善型エージェントにより、一発回答では見落としていた誤りも訂正され、より信頼性の高いアウトプットが得られます。Native RAGには無い、検証と再試行のプロセスを経られる点も、Agentic RAGが実運用で支持される理由の一つです。
以上のように、Agentic RAGはNative RAGの欠点を各所で補完・解決しています。固定的な一方向フローから、ループや条件分岐を持って臨機応変に振る舞うことで、情報アクセスの精度・網羅性・柔軟性が飛躍的に向上するのです。次章では、こうしたAgentic RAGを実現する具体的なアーキテクチャのパターンや実装手法について見ていきます。
Agentic RAGのアーキテクチャ
Agentic RAGを構築するには、いくつかの代表的なアーキテクチャパターンがあります。それぞれのアプローチがどのように実装されるか解説します。
ユーザーの質問を受け取ったエージェント(LLM)は、まずそのまま回答できるかを判断します。必要なコンテキストが十分でない場合、適切なツールを選択してデータ取得アクションを実行します(たとえば社内DBの検索やWeb検索APIの呼び出しなど)。そうして新たな知識を得たら再び判断し、まだ足りなければ追加のアクションをループします。十分な情報が揃った段階で、LLMが最終的な回答を生成する—という具合に、検索と生成がインタリーブされた柔軟なワークフローになっています。このような制御フローを実現する具体的アプローチとして、以下のようなものがあります。
単一エージェント+ツール利用(ReActパターン)
グラフベースのワークフロー(条件分岐・ループを組み込んだRAG)
マルチエージェント協調(複数LLMによる役割分担)
自己改善ループ(セルフコレクティングエージェント)
これらについて、それぞれ説明していきます。
①単一エージェント+ツール利用(ReActパターン)
最も基本的なAgenticアプローチは、一つのLLMエージェントが外部ツールを呼び出しながら推論する形式です。これはReAct(Reason+Act)で提案されたような、思考と言語アクションのインタリーブに基づく手法です。エージェントとなるLLMには、たとえば「必要に応じて検索ツールを使用せよ」といったプロンプトを与えておき、モデルが回答途中でSearch("...")のようなツール使用コマンドを出力したら実際に検索を行い、その結果をモデルにフィードバックします。モデルは得られた新情報を踏まえて再度思考をおこない、最終的な回答に至るまでこのプロセスを繰り返します。
LangChainなどのLLMオーケストレーションフレームワークでは、このシングルエージェント+ツールの仕組みが比較的容易に実装できます。LangChainでは「エージェント」という概念として組み込まれており、ツール(検索や計算機能など)のリストとLLMを紐付け、LLMが特殊トークン(たとえばAction:など)を出力したら対応するツールを実行する、というフレームで動作します。LangChain開発元が公開した例によれば、カスタム検索ツールを定義してRAG専用のエージェントを構築することも可能です。この単一エージェント方式は構成がシンプルで、Native RAGからの移行も容易です。ReActパターンによってエージェントが「考えて検索し、また考える」というループを回せるため、上述の反復検索や曖昧な質問への対応が実現できます。
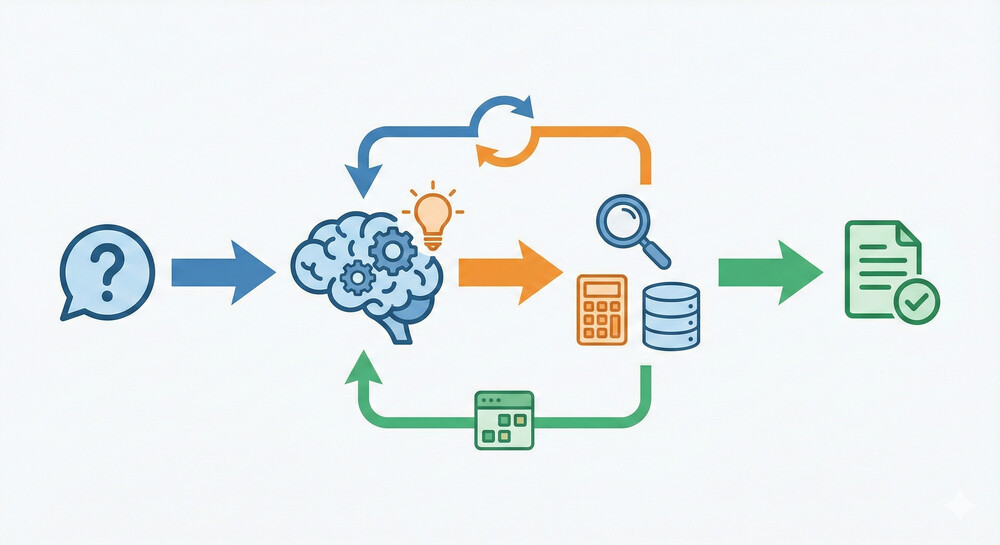
例: Self-Ask + Google検索(自己質問+検索)
例えば、LLMに対して「質問に直接回答せず、まず必要なサブ質問を自問し、それをGoogleで検索してから回答する」というプロンプトを与えることで、難問への正答率を高めることが可能です。この方法ではモデルが「[元の質問]を答えるには[サブ質問]が必要だ」→検索→「結果によると...だから、こう答えよう」という一人対話を行います。これは単一エージェントが検索ツールを使うAgentic RAGの一種であり、曖昧な質問や知識ギャップのある質問で有効性が示されています。
②グラフベースのワークフロー(条件分岐・ループを組み込んだRAG)
Agentic RAGでは、あらかじめフロー制御を設計したグラフ構造でエージェントを動かすアプローチも取られます。LangChainが2024年に公開したLangGraphはその代表例で、ノード(処理単位)とエッジ(遷移条件)でエージェントのワークフローを定義するフレームワークです。LangGraphでは各ノードにLLM呼び出しやツール実行、条件判定などを割り当て、エッジでノード間の遷移(場合によってはサイクルするループも)を表現できます。これにより「質問受取ノード→検索ノード→回答生成ノード」という基本フローに、条件付き分岐や繰り返しを自由に組み込める柔軟なRAGシステムを構築できます。
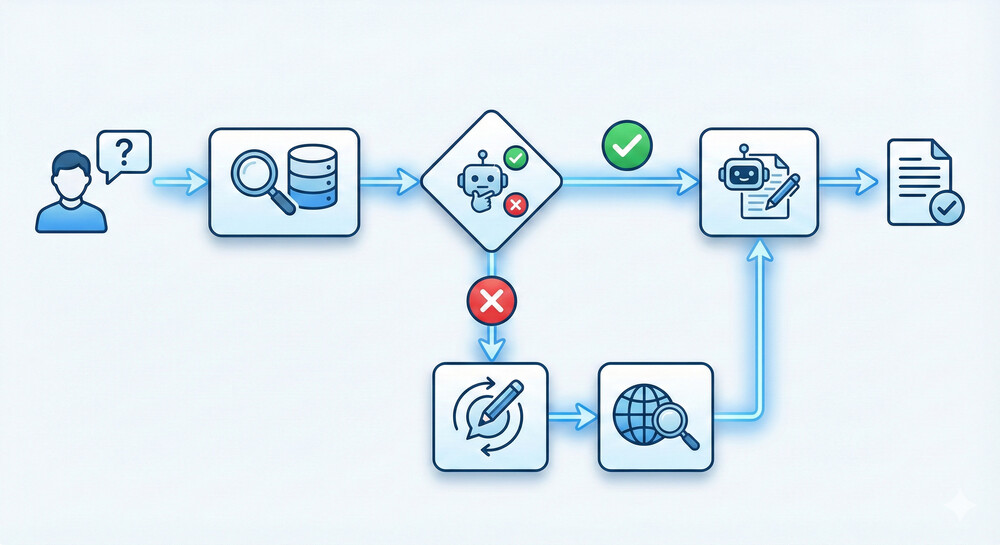
先述のCorrective RAGシステムは、このグラフベース設計の好例です。Dipanjan Sarkar氏の実装では、LangGraph上に以下のようなAgentic RAGグラフを構築しました。
Retrieve ノード – ユーザーから質問を受け取り、ベクトルDBから関連文書を検索します(通常のRAGと同じ)。
Grade ノード – LLMが検索結果の各文書について「質問と関連するか」を判定します。すべて「関連あり」なら次へ、一つでも「関連なし」があれば次の分岐へ進みます。
Generate ノード – (全文書関連ありの場合)LLMが文書群と質問を入力に回答を生成します。
Rewrite ノード – (関連なし文書があった場合)LLMが元の質問を言い換え・最適化します。たとえば用語をより一般的に変えたり不足しているキーワードを補ったクエリに書き換えます。
WebSearch ノード – 言い換えた質問でウェブ検索APIを叩き、最新情報を取得します。
Generate ノード – (分岐統合)改めて得られた追加情報も含め、LLMが最終回答を生成します。
このような条件付きルートを持つグラフ構造により、最初のベクトルDB検索だけでは答えられないケースでも自動で追加手段に訴えることができます。Sarkar氏の報告では、このAgentic RAGシステムを使うことでリアルタイム性の要求される質問(たとえば「昨日発表された〇〇について教えて」)にも対応でき、最初の社内DBに情報が無い場合でもウェブから補強して正確に回答できるようになったとされています。
LangGraphの強みは、状態管理とチェックポイント機能にもあり、対話の履歴やエージェントの内部状態を保存しつつループを回せるため、長時間にわたるエージェント動作にも耐えられます。グラフベースの手法は、視覚的・論理的にフローを設計できるため、複雑なワークフローを持つエージェントRAGを実装・デバッグしやすいのも利点です。
③マルチエージェント協調(複数LLMによる役割分担)

Agentic RAGには、複数のLLMエージェントが連携して問題解決に当たるアーキテクチャもあります。単一のLLMが全てをこなす代わりに、役割の異なるエージェント達(たとえば「プランナー役」「専門家役」「検証役」など)を用意し、互いに対話させながら回答を導く方法です。このマルチエージェント方式では、各エージェントが自律的な会話参加者のように振る舞い、必要な情報やタスクを分担します。Microsoftが提案したAutoGenフレームワークはその典型例で、複数のエージェント同士が会話(チャット)形式で協力する仕組みを提供します。AutoGenでは、開発者がエージェントの人格(たとえば「Pythonコーダー」「数学の専門家」等)や利用ツールを定義し、エージェント間の対話シナリオをシナリオとしてプログラムします。エージェント達はお互いにメッセージを送り合い、疑問点があれば質問し、知識を共有し、最終的に協調して解を組み立てます。研究論文によれば、この手法で数学問題やプログラミング課題、経路最適化問題など様々なドメインで成果を上げたとのことです。
④自己改善ループ(セルフコレクティングエージェント)
前述のReflectionのように、LLM自身が結果の良否を判断して改良を重ねる仕組みもAgentic RAGの重要なパターンです。これは単一エージェント・グラフ設計・マルチエージェントのどの方式とも組み合わせ可能な横断的テクニックですが、ここでは一例としてLangGraphでの自己修正型エージェントを紹介します。
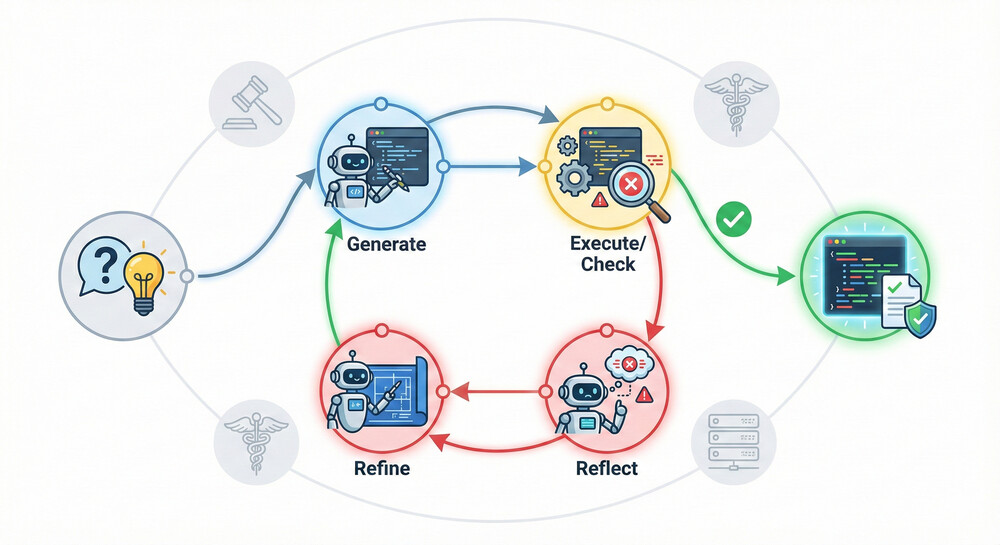
LangGraphから、コードを書くエージェントに自己フィードバックを組み込んだ事例が紹介されています。
このエージェントはまず与えられたお題に対しコードを書きます。次にそのコードを即座に実行し、エラーが出ないかテストします。もしバグやエラーがあれば、その内容をLLMが読み取って「何が問題だったのか」を分析し(Reflectノード)、改善策を考えた上でコードを修正して再生成します。これを成功するか所定の試行回数に達するまでループするのです。LangGraphではこのループをノードとエッジでモデル化し、Generate→Check→Reflect→(条件分岐で再度Generateへ)というサイクル構造を明示的に構築しています。この自己改善ループにより、一回生成しただけではエラーだらけだったコードも最終的には正しく動作するコードに洗練されました。同様の考え方はQAでも有効で、モデルが自分の回答を検証し、不備を見つけたら新たな調査を行って修正する、といった形で適用できます(回答検証エージェント/Criticエージェントの挿入)。このような自己訂正型のAgentic RAGは、人間のレビューアやデバッガのような役割をモデル自身が担う点で非常に強力です。Criticalな応用分野(法的助言や医療など)では特に、この仕組みにより信頼性を高めることが期待されています。
以上、Agentic RAGの主なアーキテクチャパターンを見てきました。それぞれ多少アプローチは異なりますが、本質的にはLLMを中心に据えつつ、外部知識やツールを動的に組み合わせるという点で共通しています。次章では、これらを実際に実装するためのオープンソース・商用のフレームワーク、およびAgentic RAGを支えるLLMの役割や設計上の工夫について触れます。
Agentic RAGを支える主なフレームワークとツール
現在、Agentic RAGシステムを構築するための便利なライブラリやプラットフォームがいくつか登場しています。ここでは、代表的なオープンソース/商用フレームワークを4つ紹介します。
LangGraph (LangChain) – グラフ指向のエージェント構築基盤:
LangGraphは、LangChain製の低レベルオーケストレーションフレームワークで、ステートフルなマルチステップAgentをグラフ構造で定義・管理できます。前述の通り、ノード(LLM呼び出しやツールなど)とエッジ(制御フロー)でAgenticワークフローを組め、条件分岐やループ、状態保存が可能です。LangChainの他コンポーネント(ベクトルDB・ツール類)とも統合されており、LangGraph上でカスタムRAGエージェントを実装できます。公式ブログでは「LangGraphはLLMとツールを統合したステートフルなワークフローをシームレスにオーケストレーションできる」とされ、LangChain既存ユーザにとってより柔軟なAgent設計を可能にする拡張機能となっています。LangGraphを用いたAgentic RAG構築ガイドも公開されており、先述のようなCorrective RAGや自己修正型エージェントも実装例として示されています。DSPy (Declarative Self-improving Python) – LLMプログラミングのフレームワーク:
DSPyは、スタンフォード大学の研究チームが開発したフレームワークで、プロンプトを書く代わりにコードでLLMのロジックを記述することを目指しています。具体的には、LLMへの入力出力をモジュール化した「モジュール」という単位で組み立て、それらを組み合わせてパイプラインやループを構築します。DSPyは内部でそれらモジュールに対応するプロンプトやモデルウェイト最適化を行い、最終的に高性能なLLM駆動プログラムを実現します。Agentic RAG的な振る舞い(条件付きの再検索や自己改善ループ等)もコード上で宣言的に記述することで、脆弱な手書きプロンプトに頼らず構築できるのが特徴です。LLMOpsの観点で再現性・保守性の高いAgenticシステムを作る基盤として注目されています。CrewAI – エンタープライズ志向のマルチエージェントプラットフォーム:
CrewAIは、強力なマルチエージェントワークフローをノーコードないし最小コードで設計・展開できるプラットフォームです。UIベースでフローを組み立てられるCrew Studioや、エージェント動作を監視・チューニングするダッシュボードなど、企業利用を見据えた機能が豊富です。特に大規模システム向けに観測性(Observability)やフェイルセーフ、権限管理の仕組みが組み込まれており、複雑なAgentic RAGを本番運用する際の土台として有用です。CrewAI自体は商用サービス(クラウド版・オンプレ版)ですが、OSS版も公開されており2025年10月にVer1.0がGA(一般利用可能)となりました。AutoGen (Microsoft) – マルチエージェント会話フレームワーク:
AutoGenは、MicrosoftがOSSとして提供しているフレームワークで、LLMエージェント同士の会話を通じてタスクを遂行するアプリケーションを構築します。AutoGenではエージェントを会話可能(Conversable)かつカスタマイズ可能なコンポーネントと位置づけ、人間やツールとの対話も含めた柔軟なモードで動作可能にしています。開発者は自然言語もしくはコードでエージェントの会話パターンを記述し、たとえば「エージェントA(質問役)– エージェントB(専門家役)が対話しながら解を絞り込む」ようなシナリオを実装できます。AutoGenの研究論文では、数学問題やコードデバッグ、サプライチェーン最適化、オンライン決断ゲームなど複数ドメインでの適用例が紹介されており、エージェント対話が解決策の創出に有効であることが示されています。AutoGenはLLMエージェントの汎用インフラを目指しており、開発者が会話パターンという高い抽象度でマルチエージェントアプリを構築できる点が特徴です。
この他にも、汎用的なLangChainやLlamaIndexも最近ではAgentic RAGを念頭に置いた機能拡張が進んでいます。たとえばLlamaIndexはGraph RAG(知識グラフ統合)やツール利用機能の拡充、LangChainはエージェントのメモリ管理や評価フレームワークLangSmithの提供など、エージェント構築をサポートする周辺エコシステムが整いつつあります。このように2024年以降、Agentic RAGを支えるフレームワーク群は百花繚乱の状況であり、ユースケースに応じて最適なツールを選択できる時代になりつつあります。
Agentic RAGにおけるLLMの役割と設計上の工夫
Agentic RAGの中核にあるLLM(大規模言語モデル)は、単なる回答生成装置ではなく思考エンジン兼制御タワーとして機能します。そこで、LLMに期待される役割や、エージェント的な振る舞いを実現するためのプロンプト設計・システム設計上の工夫について4点解説します。

①エージェントの「頭脳」としてのLLM
Agentic RAGでは、LLMが全体の意思決定を行う頭脳役です。具体的には「どのデータソースから情報を取るか」「次にどんなアクションを実行すべきか」「いつ回答を確定するか」といった判断をLLMが下します。これは従来の静的RAGにおけるLLMとは大きく異なる点です。LLMには単に与えられた知識を基に答えるだけでなく、目的達成のためにプランを立て実行する能力が求められます。そのため、システムプロンプトやチェーンの設計でモデルに明確な指示を与え、エージェントとして振る舞う人格を持たせることが重要です。
②思考と言語行動の分離(ReActプロンプト)
エージェントLLMが内部で推論しつつ外部ツールを使うためには、思考プロセス(思考チェーン)と実行アクションを明確に区別するフォーマットが有用です。ReAct手法ではこれを「Thought: ...」「Action: ...」という形でモデル出力に含めさせ、人間やフレームワーク側でパースして処理します。
この際、モデルはツール実行部分以外では内部思考(Thought)を自由記述できますが、それはそのまま外部に出さず次の入力にのみ使う仕組みです(いわゆるチェイン・オブ・ソート)。このような思考/行動の明示的プロンプトを与えることで、LLMが適切ではない文章を出力せず、適切にツールを呼び出すよう誘導できます。設計者は各ツールの使い方(引数や戻り値形式)をLLMに教える必要がありますが、一度フォーマットを覚えさせればモデルは高度に自律的に行動できるようになります。これは一種のプログラム記述言語をLLMに与えることとも言え、Agentic RAGの安定動作に寄与します。
③出力フォーマットの構造化とガードレール
Agentic RAGでは、LLMの出力がそのまま次の動作に繋がるため、出力フォーマットの乱れが以降のプロセスに深刻な影響を与える可能性があります。そこで、モデルの出力を厳密なフォーマット(たとえばJSON)にする工夫も重要です。LangGraphを用いたコード生成エージェントの例では、モデルに「結果は以下のPydanticスキーマのJSONで出力せよ」と指示し、{"description": ..., "code": ..., "explanation": ...}という構造化結果をパースする工夫なども可能です。これにより、モデルの生成内容を安全に受け取りプログラム的に扱えるため、ツールへの引き渡しや、UIへの表示においてミスが生じにくくなります。さらにCrewAIのような基盤では、ツール使用時のコンテキスト隔離や実行時間のモニタリング、例外時のフォールバックといった安全装置も用意されています。特に複数ステップを踏むAgentic RAGでは、部分的な失敗が全体崩壊に繋がらないような堅牢性設計(たとえば一定リトライ後に回答不能と伝える、代替手段に切り替える等)が必要です。こうしたガードレールを整備することで、LLMエージェントが暴走したり無限ループに陥ったりするのを防ぎます。加えて、モデルに与える知識ソースにもタグ付けや機密フィルタリングを施し、誤った情報利用や情報漏洩を防ぐ対策も取られます。要するに、LLMを信頼しすぎずエコシステムとして支える設計が、実用的なAgentic RAGには不可欠です。
④モデル選択とファインチューニング
Agentic RAGを成功させるには、用いるLLMそのものの性能も重要です。一般に、エージェント的タスクでは高い推論能力と従順性を持つモデル(例: GPT-4クラス)が望ましいと言われます。小規模モデルでは複雑なプランニングが難しかったり、ツール使用フォーマットを守らないといった問題が起こりやすいためです。しかし一方で、モデルに簡単な役割(たとえば「電卓計算」)だけを担わせる場合は、小型モデルで十分なケースもあります。そのため、タスクの種類に応じて適切なモデルを割り当てる設計も検討されます。たとえばマルチエージェント構成で、メタエージェントには強力なGPT-4を用い、サブのドメイン特化エージェントにはそれより小さいモデルを使う、といった最適化が考えられます。また最近は、Agentic RAG向けにモデルを追加学習させる試みもあります。オープンソースモデルに自己対話データを学習させてツール使用コマンドを素直に出力できるよう調教したり、強化学習でエージェントのタスク成功率を高めたりする研究も増えてきました。モデル開発の側面からも、今後Agentic RAGに適したエージェント最適化LLMが登場する可能性があります。
総じて、Agentic RAGではLLMをいかに意図通りに働かせるかが重要です。そのためのプロンプトデザイン、フォーマット規約、補助の仕組み、モデルチョイスの工夫が多面的に求められます。逆に言えば、これらを適切に整えればLLMは非常に創造的かつ有用なエージェントとして機能し、固定パイプラインでは到達できなかった問題解決能力を発揮してくれるでしょう。
Agentic RAGのエンタープライズ業務への適用
Agentic RAGは企業内の知的業務自動化において大きな可能性を秘めています。たとえば、社内の膨大なデータベース・ドキュメントにアクセスしながら最新の業界ニュースも参照してレポートをまとめるといったエンタープライズ知識アシスタントが実現できます。実際、PwCはAgent OSと称するプラットフォームを構築し、CrewAIを中核に据えて全社の様々な業務フローにエージェントを導入し始めました。これにより、社内問い合わせ対応やレポーティング、ナレッジマネジメントが自律エージェントによって行われ、生産性向上が期待されています。他にも、カスタマーサポートのチャットボットにAgentic RAGを取り入れ、製品マニュアルやFAQを参照しつつ必要に応じてユーザーのアカウント情報を引き出して回答する、といった高度な問い合わせ対応AIの例があります。金融分野では、社内の規程文書や法律データベースを横断検索しつつ、市場のリアルタイムデータも取り入れて助言を行うコンサルタントエージェントの研究も進んでいます。このように、Agentic RAGは複数のデータソースを扱う意思決定支援に向いており、企業の専門職をサポートまたは自動化するツールとして広がりつつあります。
最後に:RAG回答精度向上支援サービス
以上、Naive RAGから最先端のAgentic RAGに至るまで、RAG精度を高めるアーキテクチャと技術を詳説してきました。しかし、どれだけ動的で知的なRAGシステムを構築しても、RAGが決して回避できない大原則が最後に残ります。それは、「Garbage In, Garbage Out(入力がゴミなら出力もゴミ)」という原則です。不適切な入力からは適切な出力は得られません。
結論として、RAG精度向上とは「高度なRAGアーキテクチャ構築」と「高品質な入力データ整備」という二つの車輪を同時に回す作業です。現実には、多くのプロジェクトが前者(モデル側)に注力するあまり、後者(データ側)を後回しにして失敗します。
そんなときに思い出してほしいのが、TASUKI Annotaion が提供している生成AIに関するデータサービス「生成AI用データ構造化代行サービス」と「RAGデータ作成ツール」です。
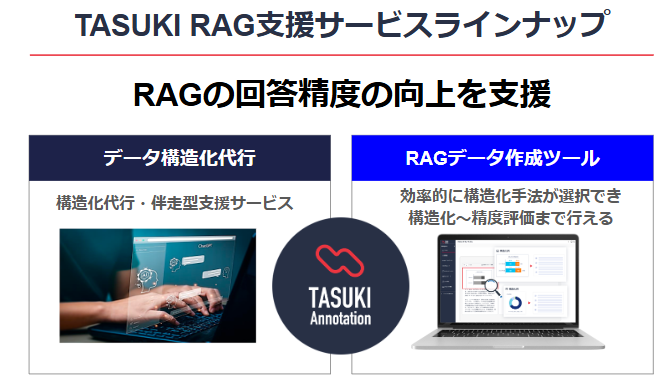
データ構造化代行
お客さまからRAGに取り込んで頂いたデータをお預かりし、回答精度が低いデータに関してデータ構造化処理を支援します。
また、単純なデータ構造化処理のみならず、キックオフでお客さまの課題を吸い上げ、アクション方針を決定・お客さまに合意頂いたうえで、プロジェクトとしてお客様とのゴールを設定させて頂きます。
その後、現在地の確認をし、現状分析〜回答精度の向上に関して伴走型として支援します。
RAGデータ作成ツール
ビジネスシーンで利用するデータの構造化は人手を介した作業が最も効果があるのは事実ですが、非常に工数がかかるという課題もあります。
RAGデータ作成ツールでは、TASUKIの構造化ナレッジを搭載した機能を利用でき、お客さま自身で工数を多くかけずにデータ構造化や精度評価を行うことができます。
〇テキスト化機能
ツール内に、ファイルを投入頂くだけで自動でテキスト化とチャンキングを行います。ファイル投入後にテキスト化を確認し、精度検証テストを実施し、現在地の把握、そこから改善に向けたアクションに移行できます。
〇精度評価機能
自動テキスト化後に精度検証テストがツール内で行えます。あらかじめ質問と模範解答をCSVでインポート、もしくは入力します。その後、ワンボタンで簡単に精度検証テストをおこなうことができます。
回答引用元のデータ、チャンクも紐づいており、画面上で確認できますので、簡単に確認や修正対応ができます。
〇図表書き起こし機能
精度検証テストで回答が誤りであった図表やグラフなどのデータ構造化を自動化します。対象の図表を選択することで、自動で図表のテキスト変換を行います。
まとめ
Agentic RAGの概要から具体的手法・応用例までを網羅的に解説しました。Native RAGからAgentic RAGへの進化は、言わばLLMに「道具を使いこなし自律行動する知性」を持たせる試みです。その価値は、単純なQAにとどまらず動的で複雑な現実世界の課題にAIが取り組めるようになる点にあります。実装面ではまだ課題もありますが、既に示したような成功例が増えており、信頼性や評価手法も整備されつつあります。
また、ソフトバンクでは、生成AIの活用やRAGの性能改善を支援する「TASUKI Annotation」サービスを提供しています。具体的には、データ構造化代行やRAGデータ作成ツールを通じて、効率的に高精度なRAGを構築するサポートを行っています。RAGの回答精度改善にお困りの企業の方がいましたら、ぜひソフトバンクにご相談ください。
それでは、ソフトバンク アドベントカレンダー 2025 2日目にバトンを渡します。
関連サービス
TASUKI Annotation RAGデータ作成ツールは、RAGを高度に活用する際に課題となるポイントをテクノロジーで支援するツールです。
RAGに関する知見がなくても、社内データを活用した精度の高いRAG回答生成を簡単に得ることが可能です。
関連セミナー・イベント

\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



