フォーム読み込み中
2025年10月リリース!AIデータセンター GPUサーバーを使ってNVIDIA Cosmosを実行してみた

次世代社会インフラ推進室
井手 晴香
2024年ソフトバンク株式会社新卒入社
2025年10月17日掲載

こんにちは、井手です。
本記事では、ソフトバンクが2025年10月に提供を開始した「AIデータセンター GPUサーバー」で利用可能な高性能GPU「NVIDIA A100 GPU」を用いて、NVIDIAの世界基盤モデル「NVIDIA Cosmos™」を実行し、テキストから動画を生成する一連の流れをご紹介します。
「AI データセンター GPUサーバー」の具体的な活用イメージを知りたい方や、「NVIDIA Cosmos」の実行方法に関心のある方にとって、参考になれば幸いです。
1.AIデータセンター GPUサーバーとは?
ソフトバンクが2025年10月に提供を開始した「AIデータセンター GPUサーバー」(以下、AIデータセンター)は、NVIDIA推奨構成の「NVIDIA DGX SuperPOD™」を採用した、次世代のAI計算基盤です。
提供プランには「NVIDIA DGX A100」および「NVIDIA DGX H100」の2種類のプランがあり、用途に応じて最適なGPUを選択できます。
主な特徴
- 柔軟な利用期間
最短7日から年間契約まで、サーバ台数・ストレージ容量・利用期間をニーズに応じて自由選択可能です。 - GPUサーバの専有利用
高速回線(InfiniBand)で接続されたGPUクラスタを1台から専有利用可能です。
数十台規模でもクラスタ構築済みで提供され、環境構築や管理の負担なく快適に利用できます。 - 開発支援ソフトウェアを標準提供
企業向けにAI開発を支援する「NVIDIA AI Enterprise」に加え、ジョブ管理に欠かせないジョブスケジューラー「Slurm」をあらかじめセットアップ済み。
複雑な環境設定なしで、すぐに開発に取り組める環境を提供しています。
これらの特長により、AIモデルの開発・学習から、科学技術計算や画像解析などの高度な計算処理を必要とするさまざまなユースケースにおいて、高性能なインフラ基盤として活用可能です。

NVIDIAのGPUを搭載したソフトバンクのAI計算基盤
「NVIDIA A100の詳細なスペック」については、NVIDIA A100 GPU 〜AIの未来を支える技術とは?~ にまとめましたのでご覧ください。
関連記事リンク
2. NVIDIA Cosmos とは
NVIDIA Cosmosは、テキスト・画像・動画といった多様な入力をもとに、物理法則に従った世界や物体の動作を理解し高品質な映像やシミュレーションを生成できる商用利用可能な事前学習済みAIモデルです。
特にロボティクスや自動運転など、物理的に正確な動きや環境の再現が求められる領域において、「Physical AI(物理志向型AI)」の開発を支援することを目的に設計されています。
また、公式GitHubリポジトリにて、NVIDIA Cosmosの使用方法やコードが提供されており、
誰でも手軽に高度な映像生成やシミュレーションを試すことが可能です。
3. 実行環境について
今回は、ソフトバンクが提供する「AIデータセンター」内の高性能計算ノード、「NVIDIA DGX A100」 クラスタを1ノード(NVIDIA A100 80GB ×8基)使用して動画生成ジョブを実行します。
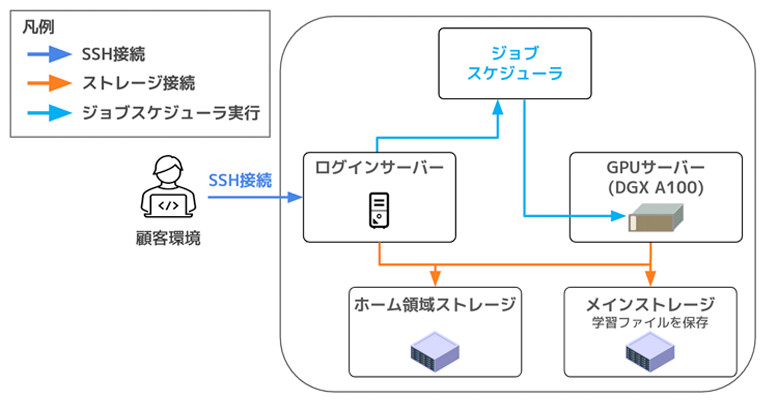
今回の実行環境
なお、実行環境の詳細や、AIデータセンターで利用可能なジョブスケジューラ「Slurm」を用いたジョブ実行の方法については、前回の記事 新卒エンジニアが挑戦!NVIDIA A100でLLMのファインチューニングを実行してみたで詳しく解説していますので、ぜひ合わせてご覧ください。
4.実装内容、流れ
今回は、NVIDIA Cosmosの「Text2Worldモデル」を用いて、テキストから映像を生成します。
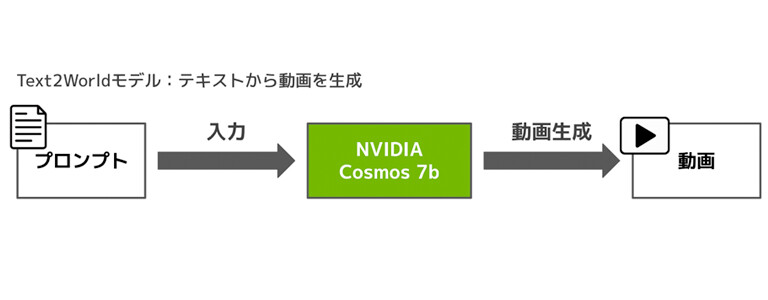
本記事では、推論の実行に必要な要素である
- モデル
- 推論プログラム
- コンテナ
を事前に準備する”準備フェーズ”と、それらを使って実際に推論を行う”実行フェーズ”に分けて解説します。
5.準備フェーズ
5.1.モデルの準備
まずは、NVIDIA Cosmosを実行するために必要な事前学習済みモデルを準備します。
今回は、AIデータセンターに付帯するNVIDIA AI EnterpriseのNGC™ Catalogから「Cosmos-1.0-Diffusion-7B-Text2World」を使用します。
このモデルの実行に必要なモデルは以下になります。
| モデルの種類 | モデル名 | 説明 | NGC | ライセンス |
|---|---|---|---|---|
| Diffusion モデル | Cosmos-1.0-Diffusion-7B-Text2World | テキストから映像を生成 | リンク | NVIDIA Open Model Licence |
セーフティ | 生成した動画を | |||
LLMモデル | 入力プロンプトを | |||
画像/動画 トークナイザー | 拡散モデルが作った圧縮表現を | |||
テキスト用 | テキストをベクトルに変換し、 その埋め込みを拡散モデルへ渡す (プログラム実行時に自動DL) | - | Apache licence 2.0 |
これらのモデルは商用利用が可能となっており、今回は事前にAIデータセンターのメインストレージに配置したうえで、ジョブを実行しています。
それぞれのモデルがどのように作用し、動画生成のプロセスにどのように関わるのかについては、後ほど「実行フェーズ」セクションで詳しく解説します。
5.2.プログラムの準備
続いて、NVIDIA Cosmosの実行に必要なプログラムコードを準備します。
今回は、「Cosmos-1.0-Diffusion-7B-Text2World」を実行するために、
NVIDIAがGitHub上に公開している「NVIDIA/Cosmos」リポジトリ(Apache License 2.0)を使用します。
使い方はシンプルで、GitHubからプロジェクトをクローンまたはダウンロードするだけで、環境構築が可能です。
今回は、このリポジトリをもとにDockerコンテナを作成し、作成したコンテナをAIデータセンターの環境に持ち込んで開発を行いました。
具体的なコンテナの準備方法については、次のセクションで詳しくご紹介します。
5.3.コンテナの準備
現在、AIデータセンター環境にコンテナを準備する方法は、主に以下の2通りです。
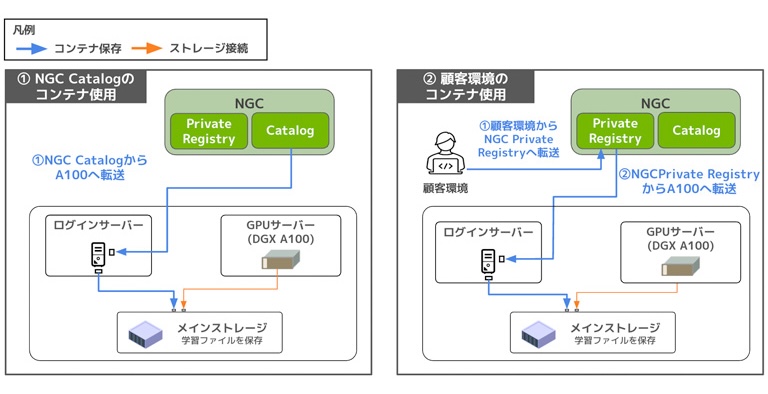
前回の記事では①の方法を用いてAIモデルの推論・学習方法について解説しました。
そのため、今回は②の「顧客環境のコンテナ使用」を実践していきます。
まずはコンテナの作成手順について説明し、続いて作成したコンテナをAIデータセンター環境へ移行する方法をご紹介します。
5.3.1.コンテナの作成(顧客環境)
まずは前のセクション「5.2 プログラムの準備」で用意した「NVIDIA/Cosmos」のフォルダを開きます。
プロジェクト内にはあらかじめDockerfileが含まれているため、こちらを使ってコンテナをビルドします。
カレントディレクトリにDockerfileがあることを確認したら、以下を実行してください。
$docker build -t cosmos .
これにより、cosmosという名前のDockerコンテナイメージを作成します。
5.3.2.コンテナの移動(顧客環境→AIデータセンター)
次に、顧客環境で作成したコンテナをAIデータセンター環境に移動する方法について、図の流れに沿って説明します。
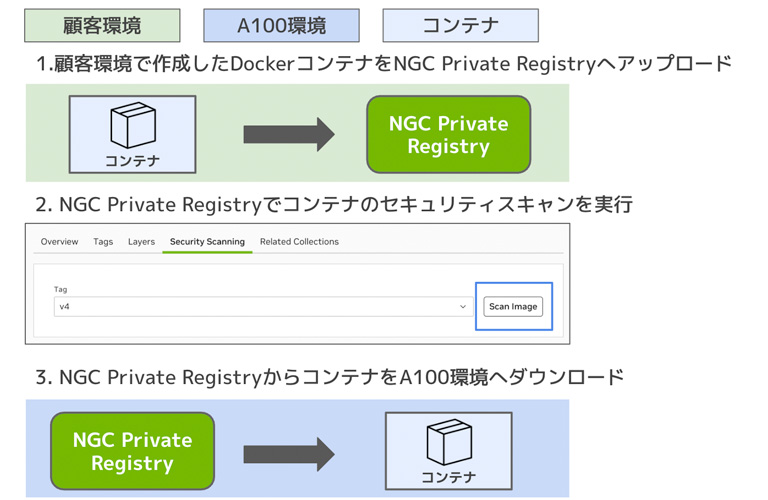
顧客環境からのコンテナの移動の流れ
<事前準備:NGCとA100環境の接続>
NGC Private Registryを利用するには、事前に顧客環境とA100環境の接続設定が必要ですので、以下の手順を実施してください。
- NGC CatalogとPrivate Registry を選択し、Personal Key(APIキー)を発行
- AIデータセンター環境に.credentialsファイルを作成
※詳しい設定手順は、前回記事の「6.3.1 NGCとA100環境の接続設定」をご参照ください。
①顧客環境で作成したコンテナをNGC Private Registryへアップロード
作成したコンテナを、まずはNGC Private Registryへアップロードします。
◆nvcr.ioへログイン
$docker login nvcr.io
※初回はユーザーネームとパスワードを入力し、NGCへログインします。
Username:$oauthtoken
Password:<API Key> #事前準備で作成したPersonal Key
◆イメージにタグ付け
$docker tag <DLコンテナイメージ名> nvcr.io/<指定の組織識別子>/<指定のTeam名>/<新しいコンテナイメージ名>:<バージョン識別タグ>
※組織識別子はユーザマニュアルに、Team名は開通通知書に記載されています。
◆NGC Private Registryへコンテナをアップロード
$docker push nvcr.io/<指定の組織識別子>/<指定のTeam名>/<新しいコンテナイメージ名>:<バージョン識別タグ>
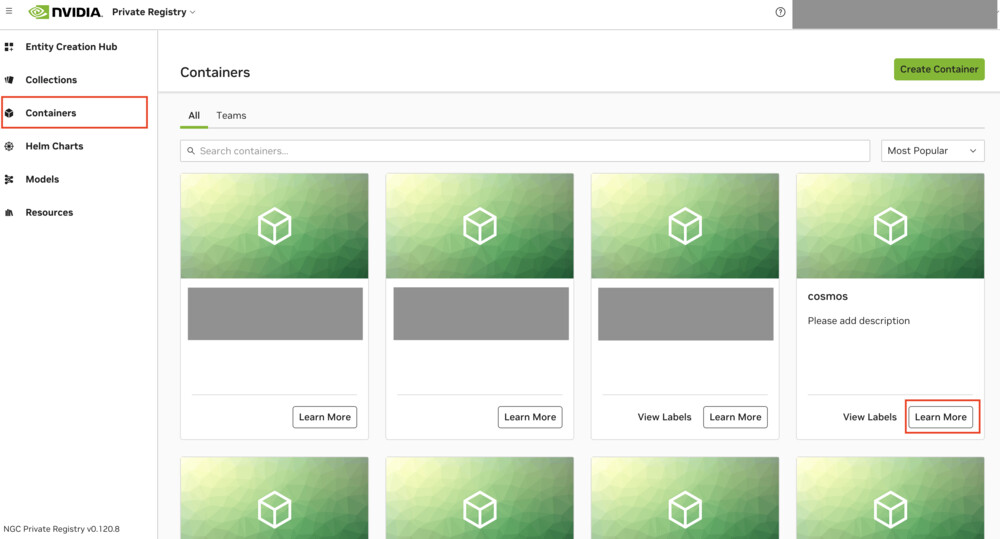
②NGC Private Registryでコンテナのセキュリティスキャンを実行
次に、NGC Private Registryにアクセスし、コンテナのセキュリティスキャンを実行します。
Containersを選択すると、先ほどアップロードしたコンテナが表示されるので、Learn Moreをクリックします。
Security Scanningタブをクリック後、Scan Imageをクリックし、セキュリティスキャンを実行してください。
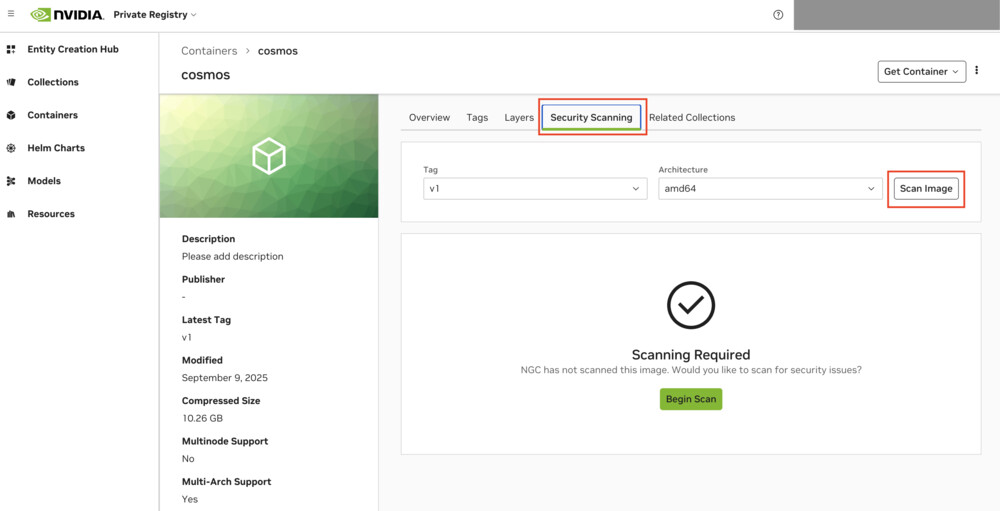
しばらく待つとセキュリティスキャンが完了します。
③NGC Private RegistryからコンテナをAIデータセンター環境へダウンロード
最後に、アップロードしたコンテナをAIデータセンターへダウンロードします。
NGC Private RegistryのTagsタブをクリックし、DLしたいバージョンのコンテナパスをコピーします。
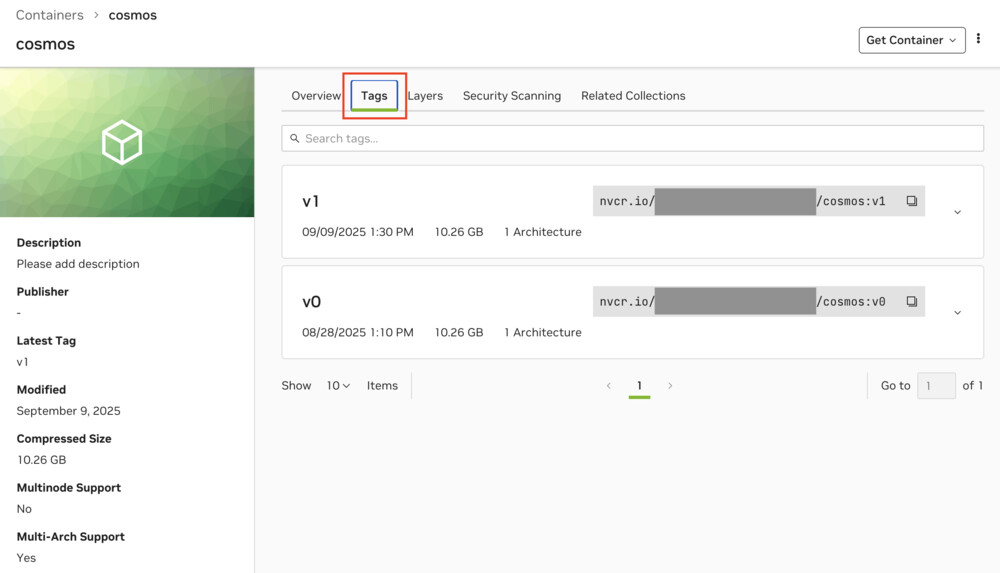
次からはログインサーバー上での作業になります。
◆NGCとの設定ファイルにパスが通るように環境変数を指定
$export ENROOT_CONFIG_PATH=”.credentialsファイルの保管場所”
◆enroot importコマンドでコンテナをダウンロード
$enroot import “docker://<コピーしたコンテナパス>"
この操作で、コンテナが「.sqshファイル」としてAIデータセンター環境のカレントディレクトリにダウンロードされます。
これで、AIデータセンター上で使用するコンテナの準備が完了です。
6.実行フェーズ
必要な準備が整ったので、いよいよNVIDIA Cosmosを用いた動画生成を実行していきます。
6.1 NVIDIA Cosmosの特徴
動画生成の具体的な流れに入る前に、特徴的な機能をいくつかご紹介します。
- Prompt_UpSampler
「Cosmos-1.0-Prompt-Upsampler-12B-Text2World」 という LLM を用いて、入力プロンプトをより詳細で豊かな表現に変換します。
下図のように、ユーザーが入力したプロンプトをPrompt Upsamplerに渡すことで、生成される動画の質や表現力を高めることが可能です。
※この機能は任意で、使用するかどうかを選択できます。

- フィルタリング機能
NVIDIA Cosmosには、生成内容の安全性を担保するためのフィルタリング機能が搭載されています。「Cosmos-1.0-Guardrail」モデルを利用し、以下の 2 種類のフィルタリングが適用されます。
Text Guardrail:禁止されている単語やフレーズを除外することで、安全でない、不適切な生成を防止
Video Guardrail:生成された動画に対し、顔ぼかしや不適切コンテンツの検出・除外を実行
- ネガティブプロンプト
「生成して欲しくない要素」や「避けたい特徴」をあらかじめ指定することで、ネガティブプロンプトの内容を避けた動画を生成することができます。
デフォルトでは以下のような品質の低い映像を避けるためのプロンプトが設定されています。
デフォルトのネガティブプロンプト(一部抜粋)
「The video captures a series of frames showing ugly scenes, static with no motion, motion blur, over-saturation, shaky footage, low resolution, grainy texture, pixelated images, poorly lit areas … Overall, the video is of poor quality.」
このネガティブプロンプトはカスタマイズ可能で、用途やコンテンツに応じて自由に設定することができます。
これらの機能により、NVIDIA Cosmosはより高品質かつ安全な動画生成を可能にしています。次のセクションでは、実際の動画生成の流れについて詳しくご紹介します。
6.2 動画生成の流れ
NVIDIA CosmosによるText2Worldの動画生成は以下の流れで行われます。
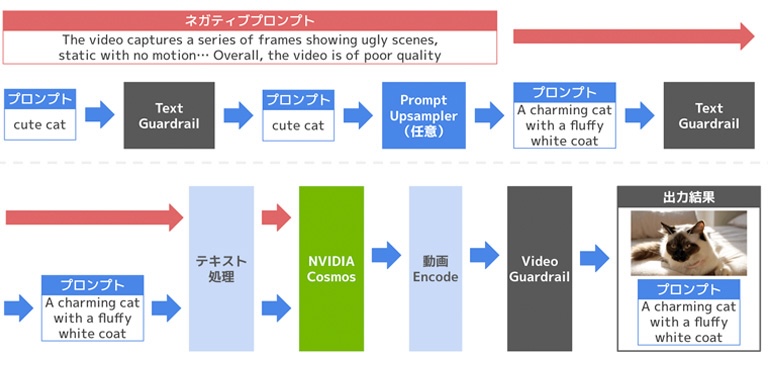
NVIDIA Cosmosによる動画生成の流れ
プロンプト、ネガティブプロンプトの入力
ネガティブプロンプトを指定しない場合はデフォルト文が適用されますText Guardrailによるプロンプトのフィルタリング
Promt Upsamplerによるプロンプトの高品質化(任意)
Upsampler後のプロンプトをText Guardrailにてフィルタリング
テキストエンコーダを用いてプロンプトをテキスト処理
NVIDIA Cosmosモデルにて動画を生成
動画トークナイザーで生成動画をエンコード
Video Guardrailにて生成した動画をフィルタリング
生成した動画ファイルとプロンプトを保存
以下は、prompt="cute cat" を指定して動画を生成した際のログの一部です。処理の流れがログに忠実に反映されています。
[generate] Run with prompt: cute cat #入力したプロンプト
[generate] Run with negative prompt: #ネガティブプロンプト
The video captures a series of frames showing ugly scenes, static with no motion, motion blur, over-saturation, shaky footage, low resolution, grainy texture, pixelated images, poorly lit areas, underexposed and overexposed scenes, poor color balance, washed out colors, choppy sequences, jerky movements, low frame rate, artifacting, color banding, unnatural transitions, outdated special effects, fake elements, unconvincing visuals, poorly edited content, jump cuts, visual noise, and flickering. Overall, the video is of poor quality.
[generate] Run with prompt upsampler: True #Prompt Upsamplerのフラグが立っているか
[generate] Run guardrail on prompt #Text Guardrailでプロンプトをフィルタリング
[generate] Pass guardrail on prompt #フィルタリングの終了
[generate] Run prompt upsampler on prompt #プロンプトを高品質化
[_run_prompt_upsampler_on_prompt] Upsampled prompt: In a sun-drenched room, a charming cat with a fluffy white coat and striking black markings lounges on a plush, light-colored bed. The cat's large, round eyes sparkle with curiosity as it gazes directly into the camera, its ears perked and alert. The soft, golden-hour light bathes the scene, enhancing the cat's playful demeanor. A delicate pink collar adorns its neck, adding a touch of elegance. The background is softly blurred, drawing focus to the cat's expressive features and the gentle sway of its tail. This intimate moment captures the essence of feline grace and companionship, inviting viewers to share in the joy of this enchanting creature.
[generate] Run guardrail on upsampled prompt #Text Guardrailでプロンプトをフィルタリング
[generate] Pass guardrail on upsampled prompt #フィルタリングの終了
[generate] Run text embedding on prompt #テキスト処理
[generate] Finish text embedding on prompt #テキスト処理終了
[generate] Run generation #動画生成開始
[generate] Finish generation #動画生成完了
[generate] Run guardrail on generated video #Video Guardrailでプロンプトをフィルタリング
[generate] Pass guardrail on generated video #フィルタリングの終了
[demo] Saved video to <生成した動画>.mp4 #生成した動画の保存
[demo] Saved prompt to <プロンプト>.txt #生成に使用したプロンプトの保存
6.3 AIデータセンター環境にて動画生成
ここまでで、動画生成の仕組みや準備の流れを理解いただけたと思います。
それでは実際に、AIデータセンター上で動画を生成していきましょう。
今回は、「5.2 プログラムの準備」で用意したプログラムをメインストレージに配置し、
「5.1 モデルの準備」でダウンロードしたモデルをcheckpointsフォルダに格納した上で、ジョブを実行します。
NVIDIA Cosmosでの動画生成は非常にシンプルで、実行用の .shファイル(シェルスクリプト)を作成すれば、複雑な手順なしに動画生成が可能です。
$ sbatch generate_text2world.sh #sbatchコマンドでジョブを実行
sbatch generate_text2world.sh
#!/bin/bash
#SBATCH -p <開通通知書に記載のpartition名>
#SBATCH --gpus=1 #使用するGPUの枚数
#SBATCH -o ./output/generate_%j.txt <標準出力の保存先>
#SBATCH -e ./error/generate_%j.txt <エラー出力の保存先>
export PYTHONPATH=<プログラムの保管場所>
srun -l --container-image=<sqshファイル> \
--container-mounts=<プログラムの保管場所>:$(pwd) \
python <プログラムの保管場所>
/cosmos1/models/diffusion/inference/text2world.py \
--checkpoint_dir <プログラムの保管場所>/checkpoints \
--diffusion_transformer_dir Cosmos-1.0-Diffusion-7B-Text2World \
--prompt <プロンプトを入力> \
--offload_prompt_upsampler \
--video_save_name <プログラムの保管場所>/<任意の名前>
7.動画生成結果
「Cosmos-1.0-Diffusion-7B-Text2World」を実行した結果が以下になります。
◆実行例①
入力プロンプト
A humanoid robot carrying heavy boxes inside a modern factory, walking smoothly between industrial machines
Promt Upsampler後のプロンプト
In a sleek, modern factory bathed in bright, industrial lighting, a humanoid robot glides effortlessly through the bustling workspace. The robot, adorned in a striking red and black color scheme, is equipped with a sophisticated mechanical arm that grips a large, brown cardboard box with precision. Its smooth, fluid movements are accentuated by the dynamic interplay of shadows and highlights, casting a dramatic chiaroscuro effect across its metallic surface. As it navigates the labyrinth of towering machinery, the camera captures its steady progress from a slightly elevated angle, emphasizing its agility and purpose. The background reveals a meticulously organized environment, with neatly stacked boxes and a large, metallic container, all contributing to the scene's industrial aesthetic. This cinematic portrayal of advanced robotics in action immerses viewers in a world where technology and efficiency harmoniously coexist.
◆実行例②
入力プロンプト
Dashcam view through the front windshield of a moving car,showing the road ahead, other vehicles, and roadside scenery.
Promt Upsampler後のプロンプト
Captured through a dashcam, this video unfolds from the perspective of a driver navigating a bustling urban landscape. The camera, mounted on the windshield, frames the expansive road ahead, where a steady stream of vehicles glides past in a harmonious dance of traffic. The scene is bathed in the warm glow of late afternoon sunlight, casting dynamic shadows that dance across the pavement. A striking red car, adorned with a bold '1' on its license plate, cruises alongside, its sleek design contrasting with the more modest vehicles around it. The camera remains steady, capturing the rhythmic flow of traffic, while the occasional pedestrian strolls along the sidewalk, adding a touch of life to the urban tableau. This cinematic journey invites viewers to experience the pulse of the city, where every moment is a testament to the beauty of motion and the art of driving.
いずれの例でも、NVIDIA Cosmosの強みである「Physical AI」を活かして、ロボットや車両などの動作が、物理法則に忠実な形でリアルに再現されていることが確認できました
一部、路上の車両の動きにやや不自然さが感じられる場面もありましたが、全体としては自然な動きが多く、物理的整合性の高い動画が生成されている印象です。
また、今回の動画生成において、実際に使用されたGPUメモリ量を確認した結果が以下になります。
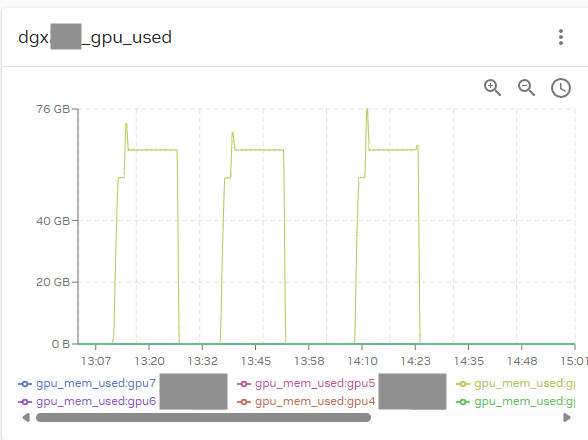
最大で約76GBのメモリが使用されており、高負荷な動画生成処理においても、A100のリソースが有効に活用されていることがわかります。
このように、高性能GPU環境+NVIDIA Cosmosの組み合わせによって、精度と品質の高い物理ベースの動画生成が実現可能となります。
まとめ
今回は、AIデータセンターが提供する「NVIDIA DGX A100」と、AIデータセンターに付帯するNVIDIA AI Enterprise内の「NVIDIA Cosmos」を活用し、動画生成を実行した事例をご紹介しました。
私自身、動画生成AIの実行は初めてでしたが、公式GitHubリポジトリには使用方法やコードが丁寧に整理されており、内容の調査から環境構築・実行までを含めて、約5日間で動画生成に到達することができました。
また、AIデータセンターにはジョブスケジューラー「Slurm」が標準で用意されており、スクリプトを準備するだけでジョブ実行を簡単に行える環境が整っています。
今後は、画像や動画を入力に使った生成にもチャレンジしていきたいと思います。
この記事を読んで「実際に使ってみたい」「自社のAIプロジェクトで活用できそう」と感じた方は、ぜひ
ソフトバンクのAIデータセンター GPUサーバーをご検討ください。
パワフルなGPU計算リソースをお探しの方へ
ソフトバンクの「AIデータセンター GPUサーバー」についての詳細なサービス情報や導入相談については、以下のリンクよりお気軽にお問い合わせください!
資料は以下のリンクよりダウンロード可能です。
関連サービス
ソフトバンクのAIデータセンター GPUサーバーは、大規模言語モデル(LLM)の学習から科学シミュレーションまで、多様なニーズに応える高性能の計算基盤です。
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



