フォーム読み込み中
画像分類モデルをゼロから構築してみた
– AIデータセンター活用記

AI向けGPU基盤 プロダクト担当
安田 崇政
かけだしGPU担当の安田です。
最新の技術動向、そして私自身の経験や学びを共有していきます。
<経歴>
- ソリューションエンジニア 4年
- 事業開発 1年
- GPU担当 NEW!
<趣味>
旅行、ドライブ、スキー、ゴルフ
<お問い合わせ>
何か質問やリクエストがあれば、お気軽にブログ末尾のフォームからお問い合わせください。
皆さんと一緒にナレッジを共有し合い、成長していけることを楽しみにしています。
2026年1月15日掲載

生成AIやディープラーニングの活用が進む中で、「ハイエンドGPUをフルで専有できる環境」が求められるケースが増えています。
今回は、SoftBankのAIデータセンター GPUサーバーにて、NVIDIA DGX ™A100を専有で使える環境を用いて、画像分類モデルを1から構築・学習・評価する一連の操作を試してみました。
この記事では、その手順とポイントを実例付きで紹介します。
環境構成
<AIデータセンター GPUサーバー>
今回のモデル構築には、AIデータセンターが提供する GPU サーバー・共有ストレージ・高速ネットワークで構成された学習環境を利用しています。
PyTorch など主要なフレームワークがそのまま使えるため、コードを持ち込むだけで簡単に学習ジョブを実行できます。
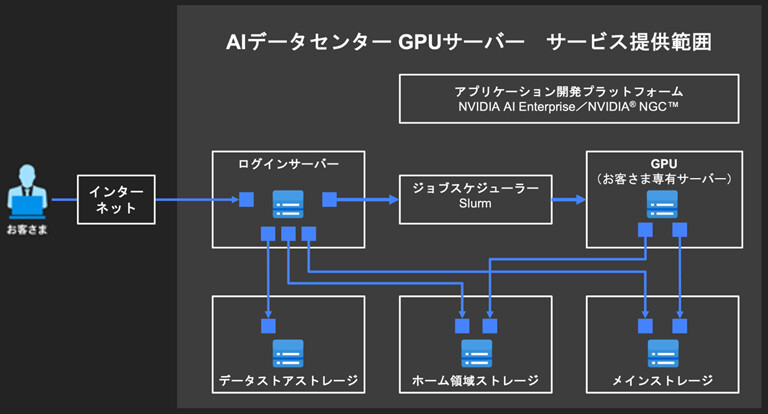
▲参考 AIデータセンター GPUサーバー サービス提供範囲
データセット CIFAR-10とは?
今回のタスクでは、画像分類の代表的なデータセットである「CIFAR-10」を使用します。最初にCIFAR-10のデータをダウンロードし、その後3エポック(=データセットを3周)学習を行う構成になっています。
CIFAR-10の学習用データは50,000枚あるため、3エポック分で合計150,000枚分の画像を使って学習することになります(ただし同じデータを3回繰り返して使います)。 CIFAR-10(Canadian Institute for Advanced Research 10)は、10種類の物体クラス(飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラック)に分類された 小さなカラー画像(32×32ピクセル)のデータセットです。各クラスに対して6000枚の画像があり、合計60,000枚の画像(50,000枚の学習用+10,000枚のテスト用)で構成されています。
参考URL:CIFAR-10 and CIFAR-100 datasets
小規模ながらも難易度が適度で、深層学習の入門やベンチマークとして広く使われています。
環境概要
下記に今回の環境概要をまとめました。
- GPU:NVIDIA DGX A100(A100 80GB ×8)
- フレームワーク:PyTorch(NGC公式コンテナ)
- モデル:SimpleCNN(軽量な畳み込みニューラルネットワーク)
- ジョブ管理:Slurm+Enroot(NGCイメージを展開)
- データセット:CIFAR-10(10クラス画像分類)
ステップ1:NVIDIA® NGC™ログイン&API Keyの発行
まず前提として、SoftBankのAIデータセンター GPUサーバーでは、ログインサーバーを中心に操作を行う構成となっており、ユーザーがGPUサーバー(計算ノード)に直接ログインすることはありません。ジョブはログインサーバーからSlurmを通じて投入され、NGCコンテナを用いてGPUサーバー上で処理が実行される形になります。
まずはNGC にログインし、API Keyを生成します。 ログインサーバーに以下のように設定します。(NGCとログインサーバーの認証接続設定です)
[ログインサーバー]$ vi ~/.config/enroot/.credentials
# 以下を追記して保存
machine nvcr.io login $oauthtoken password <Personal API Key>
machine authn.nvidia.com login $oauthtoken password <Personal API Key>
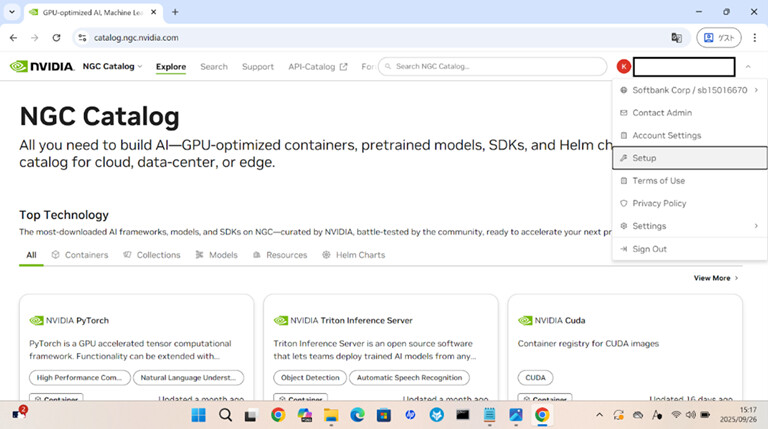
▲ NGC Catalog(右上Set upからGenerate API Key可能な画面に遷移できます)
※作成時、API Keyが一度しか表示されないのでしっかりコピーしておきましょう。
ステップ2:PyTorchコンテナの取得
NGC CatalogからPyTorchのイメージを選び、Enrootで取得します。
(PyTorchはNGC CatalogのTOPにあるのでそこから遷移できますし、検索してもOKです。)
コンテナイメージは容量が大きいので、必ずメインストレージのLustre配下の任意のディレクトリにインポートしましょう。インポートは少なくとも30分程度、時間を要します。
[ログインサーバ]$ cd /sample
[ログインサーバ]$ enroot import docker://nvcr.io/nvidia/pytorch:24.03-py3
取得後は .sqsh ファイルとして保存され、Slurm経由でのジョブ実行で使用できます。
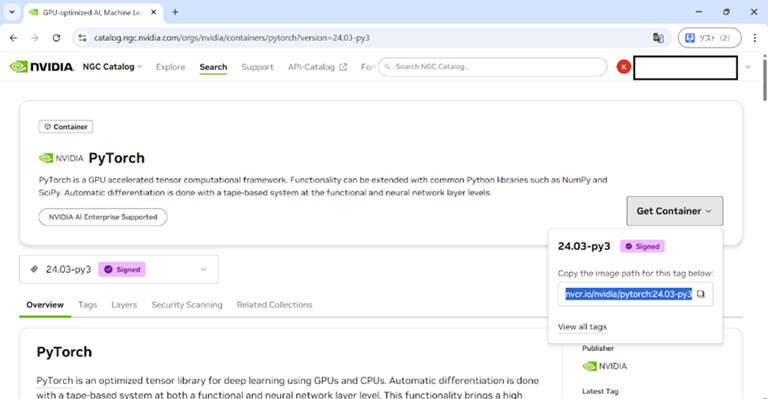
▲参考 PyTorchイメージパス取得
ステップ3:ジョブの準備と投入
ジョブを投入するためにSlurm+Enroot(下記コマンド)でコンテナを起動し、PyTorch環境を立ち上げます。
[ログインサーバー]$
srun -N1 -n1 --gpus=1 --time=00:30:00 \
-p <partition> \
--container-image=/sample/nvidia+pytorch+24.03-py3.sqsh \
--container-mounts=/sample:/sample \
--pty bash
このコマンドでGPUリソースを確保し、PyTorchが動作するコンテナ内に入ることができます。
ステップ4:学習
Pythonを動かせる環境が整ったので、下記CNN(畳み込みニューラルネットワーク)を用いてCIFAR-10画像分類を学習をしてみましょう。CNN は、画像から特徴(エッジや模様など)を自動的に抽出するためのモデルで、下記①~③といったシンプルな構成で動作します。
① 畳み込み層(特徴抽出)
→画像の中から特徴(形・模様)を見つける役割。細かいフィルタを画像に当てて、「ここに線がある」「ここに色の変化がある」などを読み取るイメージです。
②プーリング層(サイズ圧縮)
→大切な情報だけを残しながら画像をギュッと縮める役割。画像全体を小さくすることで、計算がラクになり、ノイズの影響も減ります。
③ 全結合層(分類)
→畳み込み層・プーリング層で得た特徴をまとめて、最終的に「猫?」「犬?」「車?」などのクラスに分類します。
ここでは、この基本構造をもとにした軽量モデル SimpleCNN を使って学習を進めます。
<学習スクリプト cifar_train.py>
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# CIFAR-10データをダウンロード
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
# シンプルなCNN
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(64*8*8, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.fc(self.conv(x))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 学習ループ
for epoch in range(3): # 3エポックだけ
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print(f"[{epoch+1}, {i+1:5d}] loss: {running_loss / 100:.3f}")
running_loss = 0.0
print("Finished Training")
torch.save(net.state_dict(), "/lustre/sample/cifar_net.pth")
print(" モデルを保存しました。")
<実行イメージ>
任意のディレクトリにviコマンドでスクリプト作成もしくscpでファイル転送しておいた上で、以下コマンドを実行します。
[ログインサーバ]$ python cifar_train.py
# 出力例
[1, 100] loss: 1.957
[1, 200] loss: 1.606
・
・(省略)
・
[3, 1500] loss: 0.716
Finished Training
モデルを保存しました。
<上記出力ログの意味>
[1, 100] loss: 0.920
^ ^ └─ この100バッチの平均損失(loss)が 0.920
| └─ バッチ番号:100番目のミニバッチ処理が終わったところ
└─ エポック番号:1エポック目
<loss(損失)とは?>
学習モデルの「予測」と「正解ラベル」のズレのこと。値が小さいほど「よく学習できている」ことを示します。 初期は大きく、エポックが進むごとに徐々に小さくなるのが理想です。
<epoch(エポック)とは?>
「訓練データ全体を一通り学習に使った回数」のこと。
今回CIFAR-10の訓練データが5万枚あって、バッチサイズが 32です。
バッチサイズ(batch size) は、一度にモデルへ渡すデータの枚数/件数を指し、
「モデルに画像を1枚ずつ見せるのではなく、まとめて何枚か一気に渡す」という感覚です。
つまり、1エポック = 50000枚 ÷ 32 ≒ 約1,500バッチ分の学習がログとして見えたということです。
ステップ5:テスト&精度評価
学習によって画像分類モデルが出来上がったので、精度検証用のテストスクリプトを用いて、学習済みモデルの精度を評価しましょう。
<評価スクリプト cifar_test.py>
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
# CIFAR-10のテストデータ
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)
# モデル定義(train.pyと同じにする必要あり)
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(64*8*8, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.fc(self.conv(x))
# デバイス設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = SimpleCNN().to(device)
# ② モデル読み込み
net.load_state_dict(torch.load("/lustre/sample/cifar_net.pth"))
net.eval()
# 推論と評価
correct = 0
total = 0
with torch.no_grad():
for i, data in enumerate(testloader): # ← enumerateを追加
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# ここに進捗表示を追加
if (i + 1) % 100 == 0:
print(f"[{i+1}] 現在の精度: {100 * correct / total:.2f}%", flush=True)
print(f" テスト精度: {100 * correct / total:.2f}%")
<実行イメージ>
userXXX@server:/sample$ python cifar_test.py
# 出力例
[100] 現在の精度: 71.56%
[200] 現在の精度: 71.28%
[300] 現在の精度: 71.72%
テスト精度: 71.65%
簡易的に作った軽量CNN(SimpleCNN)では精度7割くらいが一般的ですので、今回の画像分類モデルの構築は成功です。
<精度検証結果の補足>
各 [100], [200], ... の「現在の精度」はそれまでに処理した 合計画像数(=累積)に対する正解率 を計算して表示しています。
[100] 時点では:100バッチ × 32枚 = 約3200枚に対する正解率
[300] 時点では:9600枚分の正解率
(残りの400枚は、単に進捗表示のタイミングに含まれていないだけで、実際には全部処理されています。)
おわりに
今回はSoftBankのAIデータセンターGPUサーバーでNVIDIA DGX™ A100を専有利用できる環境を使い、画像分類モデルをゼロから構築・学習・評価する手順とポイントを実例付きで紹介しました。
今回の記事を通して、GPUサーバー環境におけるDeep Learningモデルの構築フローを追体験してもらえたら嬉しいです。
SoftBankのAIデータセンター GPUサーバーでは、1台からでも7日間からでも利用可能です。NVIDIA社のGPUサーバーが提供されており、短期間でリソースを使い切るようなスポット的な検証用途にも非常に適しています。
AIのモデル開発から研究用途まで、パワフルなGPU計算資源をお探しの方は、ぜひソフトバンクへお問い合わせください!
AIデータセンターに関するお問い合わせ
GPUクラウド、AIデータセンターの導入を検討のお客様向けのお問い合わせフォームからご連絡ください。
関連記事リンク
関連セミナー・イベント

おすすめの記事
条件に該当するページがございません



