フォーム読み込み中
SQL Serverの代わりにAlibaba Cloud ApsaraDB for PostgreSQLのBabelfish 機能でSQL Serverとして利用してみた

Batch/OLAP Software Engineer, CRE(Customer Reliability Engineer)
大原 陽宣
多様多種で複雑なデータを明確化し、テクノロジーでイノベーションを起こすことで、昨日までは不可能だったものを、明日は可能になるようなデータエンジニアを目指しています。Apache HBaseやRaftアーキテクチャなどの分散技術を得意としつつ分散データベースやデータ分析基盤、Kubernetesを担当。Apache Incubator等OSS活動中。Alibaba Cloud Expert、Google Cloud Expert。
2022年9月6日掲載

Windows Server 2012及びWindows Server 2012 R2が2023/10/10にサポート終了となります。サポート終了後はセキュリティ更新プログラムが提供されなくなり、セキュリティリスクが高まります。そのため、サポート終了までにOSのアップグレードやクラウドへのシフトを検討することが多いと思います。
しかし、Windows Server 2012及びWindows Server 2012 R2で稼働しているアプリケーションの要件からSQL Serverと併用利用を前提とするシナリオがあります。その場合、コスト面からAzure SQL Serverへ切り替えるパターンが主となります。
そこで、Azure以外の選択肢としてAlibaba Cloud ApsaraDB for PostgreSQLのBabelfish機能を使って、SQL Serverの代わりに使用してみます。
- Amazon Aurora PostgreSQLのBabelfish機能を使って、SQL Serverの代わりに使用できるので、互換性がどのくらいあるかを検証します
- SQL Serverの移行先を探している方向けの記事です
- Babelfish機能を検討されている方が、自分の利用に耐えることができるのかを確認することができます
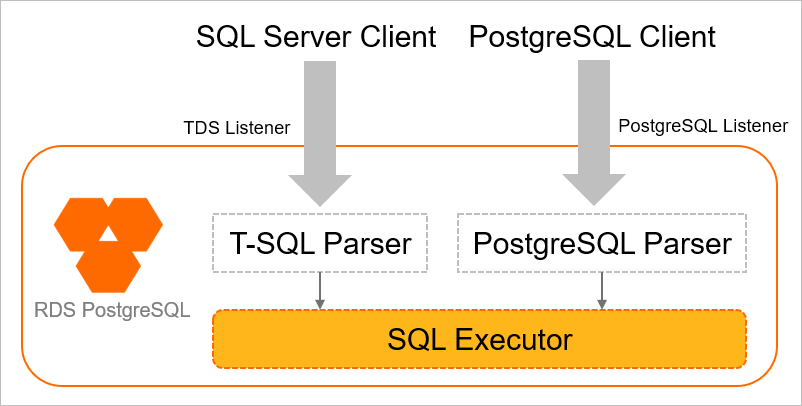
1. Babelfish機能とは
Babelfish機能は Microsoft SQL Server用に書かれたアプリケーションからのSQLクエリ処理をPostgreSQLへ変換しSQLクエリ処理してくれる、オープンソースサービスです。これにより、ユーザはSQL Serverが必要な要件でも、Babelfishを使うことで、PostgreSQLで稼働することができます。現在、主要クラウドベンダの中で、Babelfish機能が使えるRDBはAlibaba Cloud ApsaraDB for PostgreSQL、Amazon RDS PostgreSQL、Amazon Aurora PostgreSQL のみです。
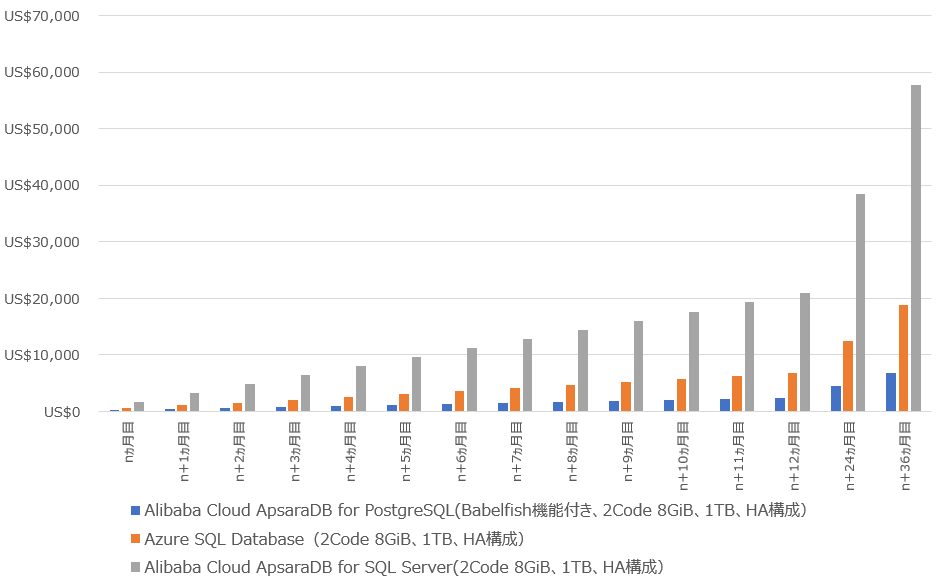
Babelfishを使うとデータベース基盤としてどれくらいコストが削減できるか?という点についても計算してみました。同じ2Core 8GiB 1TB HA構成で計算するところ、ApsaraDB for SQL Serverが$1,790.7USD/Monthに対し、ApsaraDB for PostgreSQLが$187.72USD/Monthと9倍近くのコスト差が出ています。Azure SQL Databaseは$521.28USD/Monthと、ApsaraDB for PostgreSQLの3倍近く安くなっています。ApsaraDB for PostgreSQLやAzure SQL Databaseより、ApsaraDB for PostgreSQLを利用すればするほど安くなることは目に見えています。
※Windows ServerなどIaaS基盤の料金は除きます
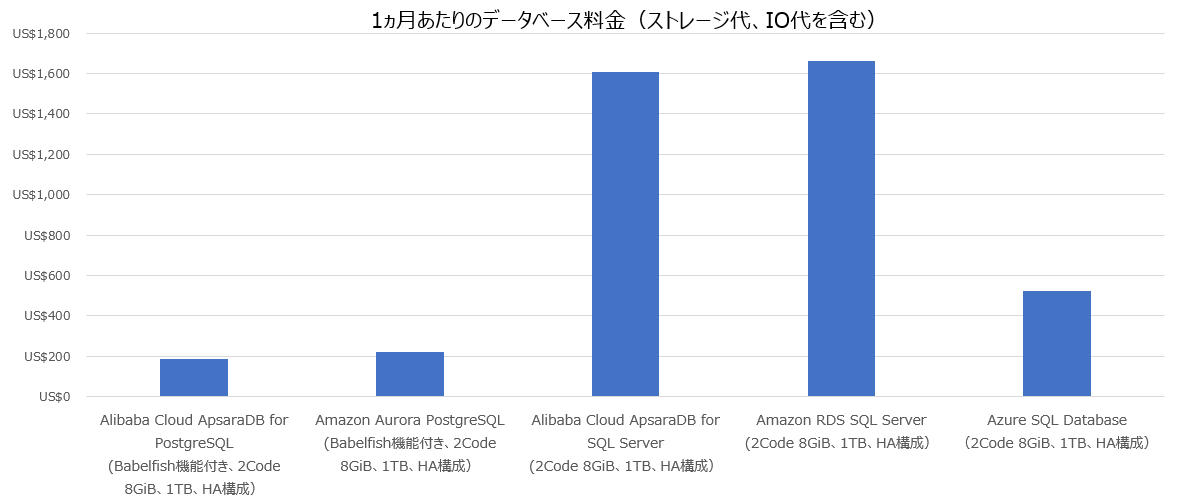
AWS Auroraも同じくBabelfishをサポートするため、AWS Auroraとの比較も入れてみました。AWS Auroraと比較してApsaraDB for PostgreSQLが若干安くなっていますが、元々ApsaraDB for PostgreSQLはAuroraのようにユーザのワークロードに応じてスケーリングするCloud-Native DBでなく純粋なリレーショナルデータベースサービスなので、SQL Serverに代わるデータベース基盤コストを最大限に抑えたい場合は参考にするといいでしょう。
2. 検証の流れについて
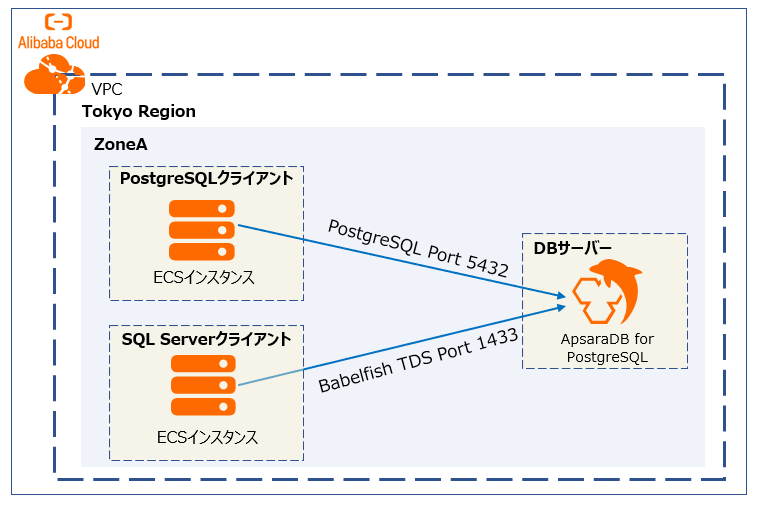
先述通りBabelfishはApsaraDB for PostgreSQLで、PostgreSQL、SQL ServerそれぞれのSQLクエリに対応させることができます。これを試すために、今回2つのECSインスタンスを準備し、PostgreSQLクライアント、SQL Serverクライアントをそれぞれ導入、そこからそれぞれのSQLクエリで動作確認をします。PostgreSQLとSQL ServerのDDL、DML、DCLそれぞれのコマンドを実施し、最後にT-SQLらプロシージャをしながらどれだけ適応できるかを検証します。
全体構成図としては次の通りになります。注意として、PostgreSQLクライアントからデータベースへの接続ポートは5432に対し、SQL Serverクライアントからデータベースへの接続ポートは1433と異なります。
3.PostgreSQL/SQL Serverクライアント用ECSインスタンスを作成
①ECSインスタンスを2台作成します。OSはどちらもUbuntuです。
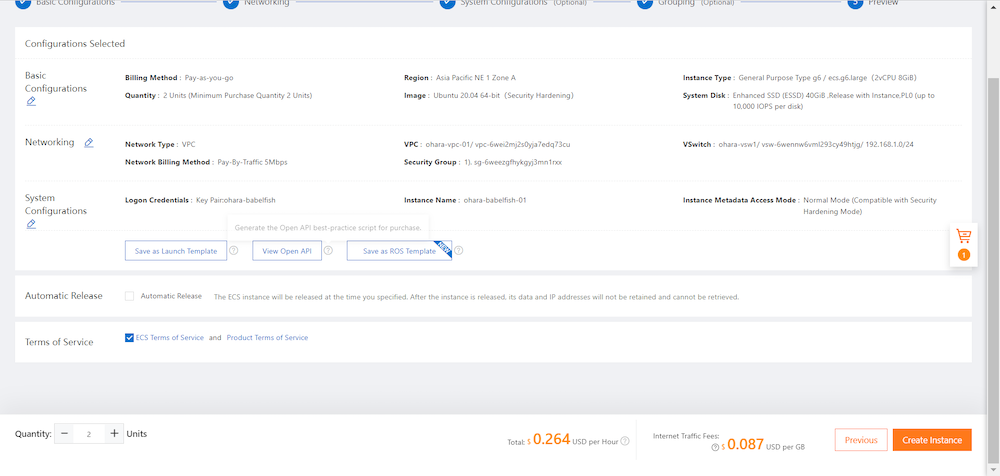
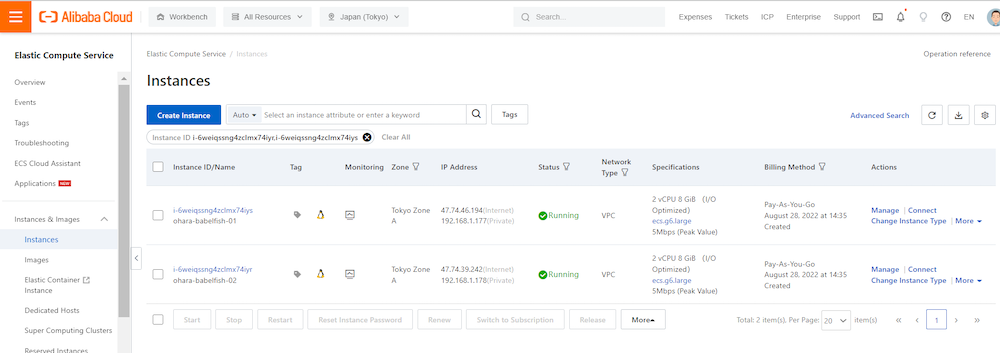
②ShellでPostgreSQLクライアントとなるECSインスタンス、SQL ServerクライアントのECSインスタンスへそれぞれ接続します。

4.ApsaraDB for PostgreSQLインスタンスを作成
コンソールからApsaraDB for PostgreSQLインスタンスを作成します。その際、コンソール画面にてBabelfish機能がありますので、これをチェックし有効化します。Babelfish機能は現在PostgreSQL13、14のみサポートしています。
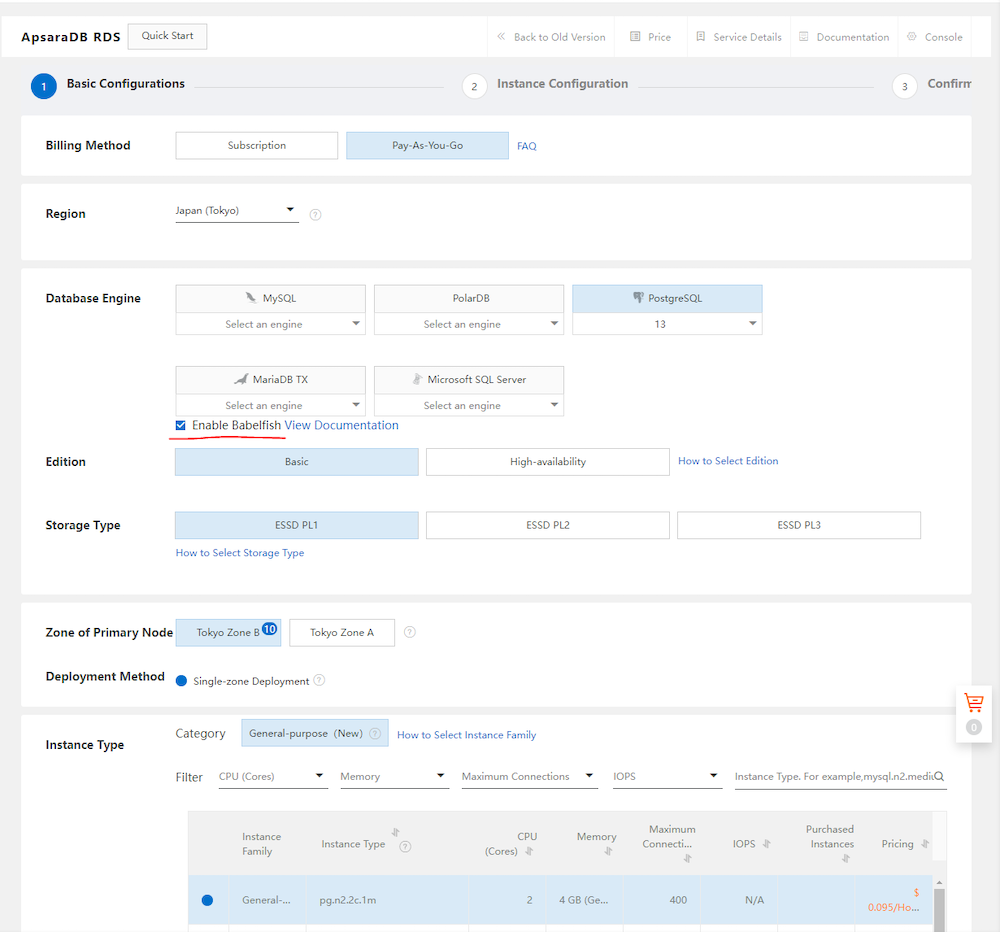
Babelfish機能を有効化しつつ、あとは往来通りにApsaraDB for PostgreSQLインスタンスを作成します。SingleやHA構成、Zone、低スペック、どんな構成でもBabelfish機能が付帯されてるApsaraDB for PostgreSQLが無事作成されます。
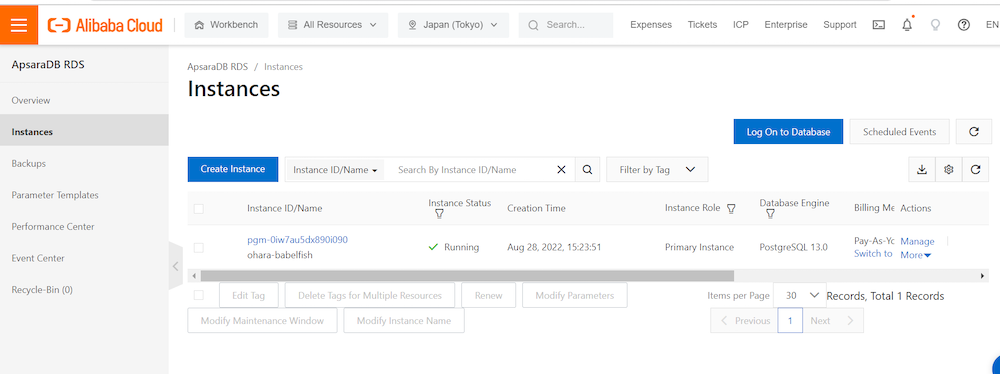
Babelfish機能が有効化されていれば、Babelfish機能のステータスがみえます。
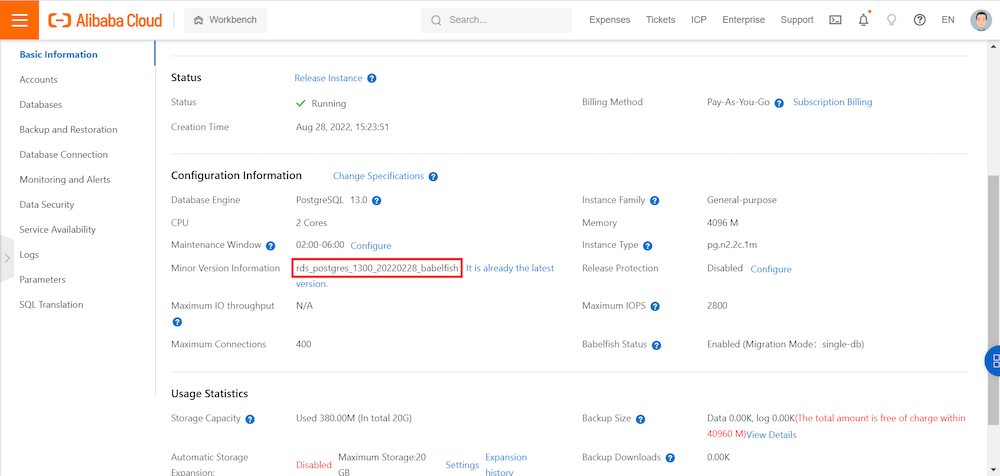
ApsaraDB for PostgreSQLインスタンスで接続、利用ができるよういくつか設定をします。
まずはホワイトリスト登録です。Data Security > Whitelist 画面へ遷移し、今回クライアントとなるECSインスタンスのIPアドレスをホワイトリストに登録します。
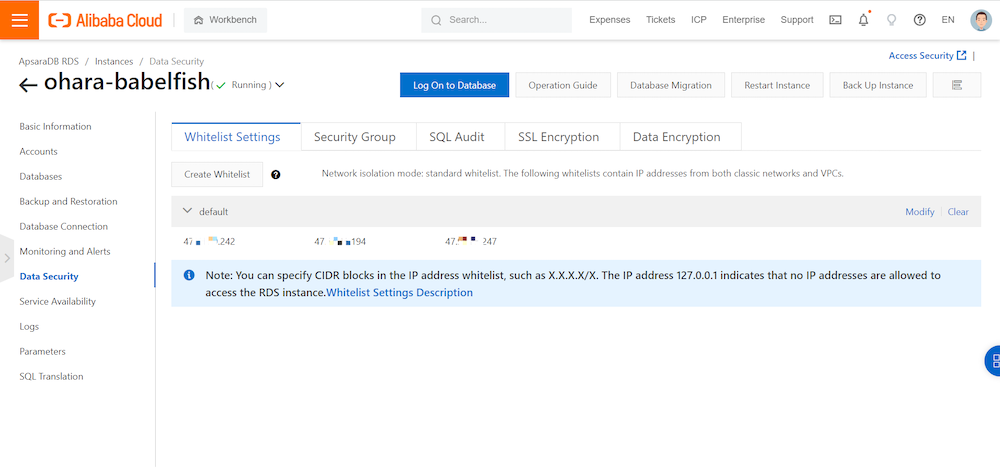
次はPublic Endpointを利用するように有効化設定をします。
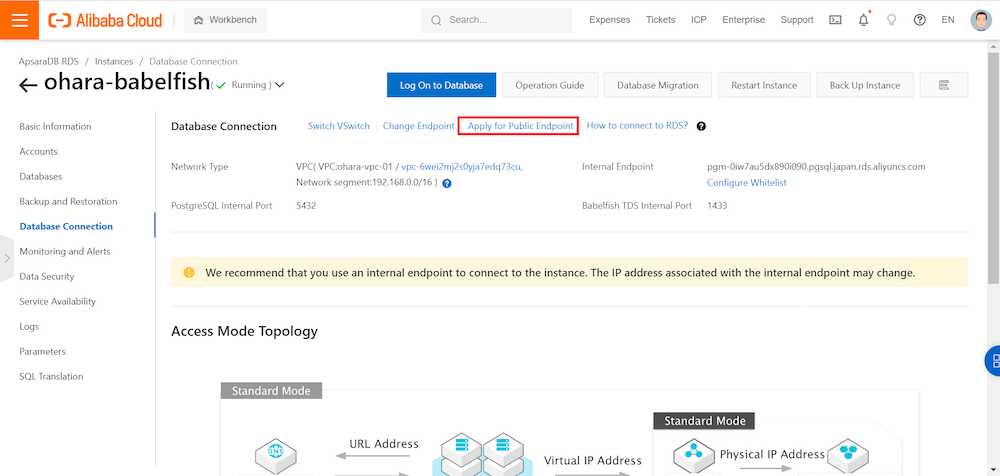
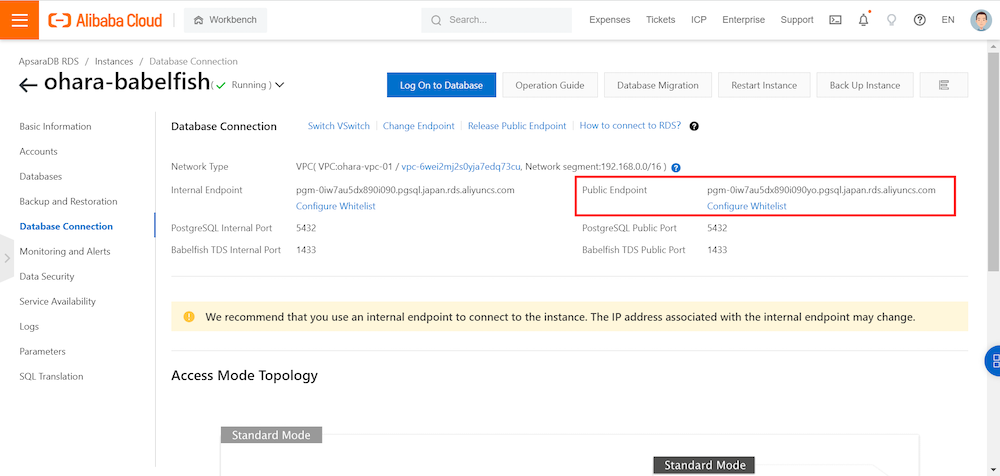
5.PostgreSQL CLI ツールから ApsaraDB for PostgreSQL へ接続
ECSインスタンスにて、PostgreSQL CLIツールをインストールします。流れとしてCLI導入に必要なリポジトリ設定からpackage導入をします。
リポジトリの設定をします
# sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'

公開リポジトリのキーをインポートします
# wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -

パッケージリストを更新します
# sudo apt-get update
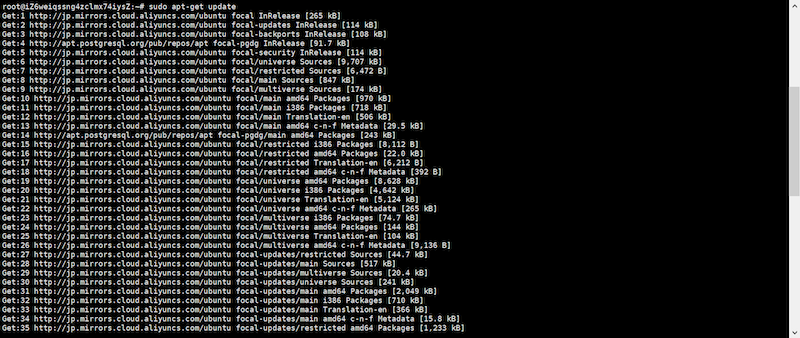
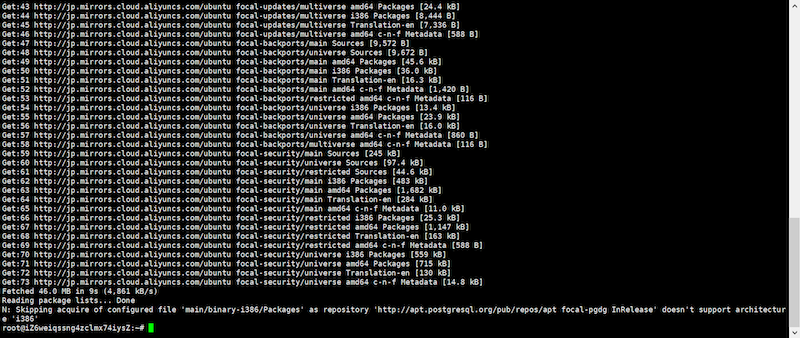
postgresqlをインストールします
# sudo apt-get -y install postgresql
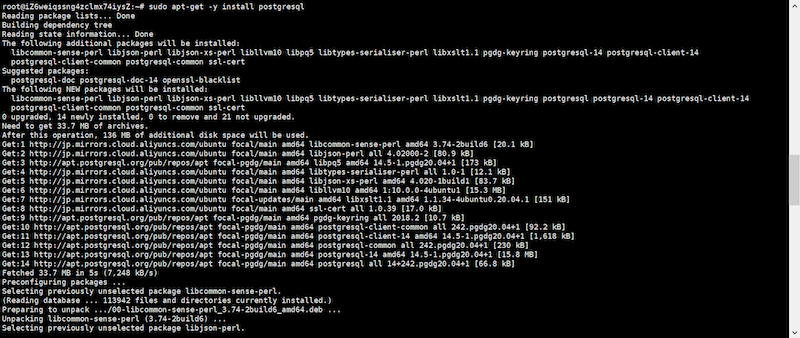
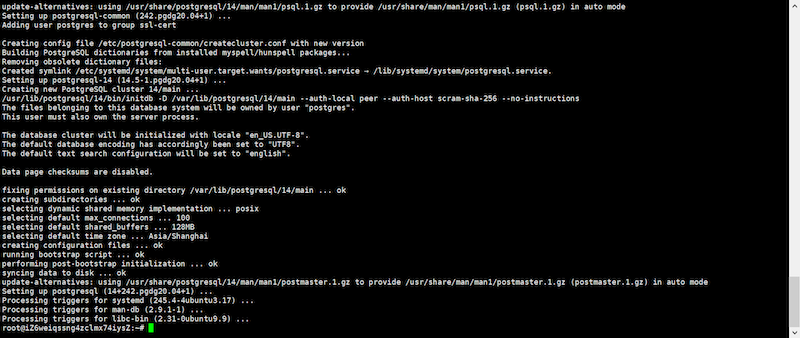
これで、PostgreSQL CLIクライアントの準備が完了できたので、早速接続してみます。
今回はアカウントを `inituser` にしています。

接続エンドポイントとして、PostgreSQL CLIツールからApsaraDB for PostgreSQLへ接続する際は、コンソール画面に表示されているEndpoint(pgm-<user endpoint>.pgsql.japan.rds.aliyuncs.com )、および、Port 5432を選定します。
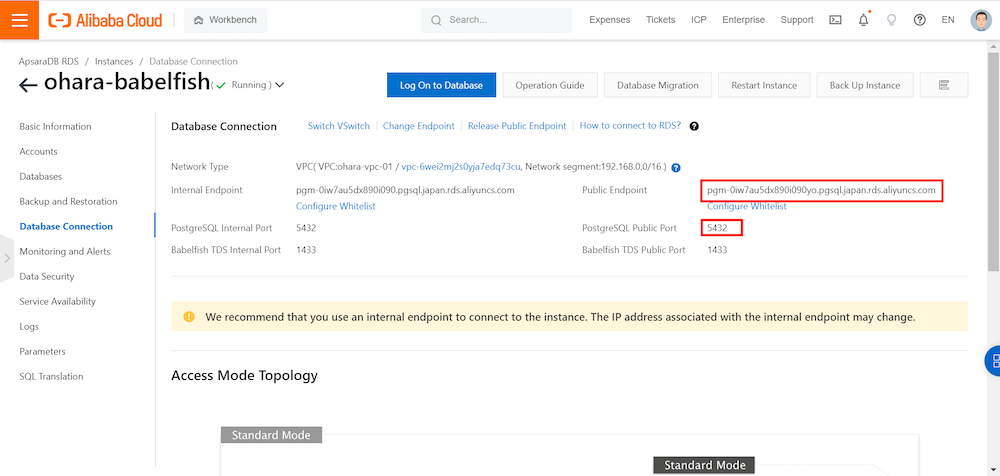
準備が出来たので、PostgreSQL CLIツールからApsaraDB for PostgreSQLへ接続します。
接続方法は
`psql -h<instance endpoint> -U <Username> -p <port> -d <DBname>`
となります。上記の例であれば、接続コマンドは以下の通りです。
# psql -h pgm-<user endpoint>.pgsql.japan.rds.aliyuncs.com -U inituser -p 5432 -d postgres
接続後、ユーザアカウントに対するパスワードが求められるので、パスワードを入力し、ApsaraDB for PostgreSQLのPostgreSQLへ接続します。

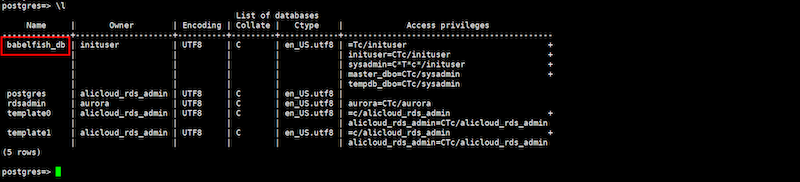
データベース一覧を確認し、babelfish_dbがあることを確認します。
babelfish機能が有効化されていれば、ApsaraDB側により、babelfish_dbという名前のデータベースが出来上がります。注意として、SQL ServerはTDSポート(Tabular Data Stream Protocol)というプロトコルを使ってクライアントとデータ通信を行います。 そのため、TDSポート経由でアプリケーションをApsaraDB for PostgreSQLへ接続すると、クライアントがSQL Serverと認識され、PostgreSQLクライアント用のbabelfish_dbデータベースが非表示になります。
postgres=> \l
babelfish_dbに接続します。
postgres=> \c babelfish_db

スキーマを確認します
babelfish_db=> \dn
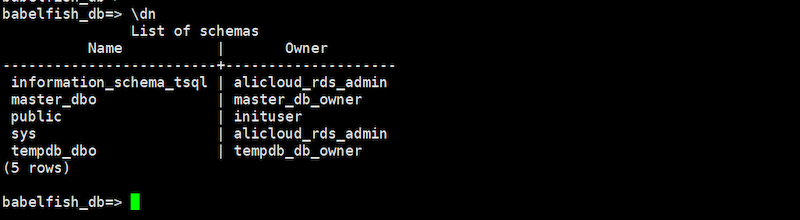
現在、データベースを作ったばかりの初期状態なので、データベースを作成しつつロールを付与することで、PostgreSQLによるDDL操作(Data Definition Language、データベースやテーブルなどを定義するコマンド)でPostgreSQLが一通り操作できるか確認します。
PostgreSQLによるデータベース作成のコマンドは次の通りです。
CREATE DATABASE name [ [ WITH ] option [ ... ] ]
CREATE DATABASE db_test;

データベースを変更します。PostgreSQLによるコマンドは次の通りです。
ALTER DATABASE name [ [ WITH ] option [ ... ] ]
ALTER DATABASE name RENAME TO new_name ALTER DATABASE db_test RENAME TO test_db;

PostgreSQLによるデータベースを削除します
DROP DATABASE [ IF EXISTS ] name [ [ WITH ] ( option [, ...] ) ]
DROP DATABASE test_db;

これで一通りPostgreSQLベースのDDL操作ができることを確認できました。
今度はデータベース、テーブルを作成しつつ、PostgreSQLによるDCL操作(Data Control Language、権限などでデータを制御するコマンド)でApsaraDB for PostgreSQLが一通り操作できるか確認します。まずは再度データベースを作成します。
CREATE DATABASE test_db;

パスワード付きのロールを新しく作成します。PostgreSQLによるコマンドは次の通りです。
CREATE ROLE name [ [ WITH ] option [ ... ] ]
babelfish_db=> CREATE ROLE role_test WITH LOGIN PASSWORD 'Test1234';

GRANT — アクセス権限を定義してみます。PostgreSQLによるコマンドは次の通りです。
GRANT { { CREATE | CONNECT | TEMPORARY | TEMP } [, ...] | ALL [ PRIVILEGES ] }
ON DATABASE database_name [, ...]
TO role_specification [, ...] [ WITH GRANT OPTION ]
※注意として、PRIVILEGESキーワードはPostgreSQLでは省略可能ですが、SQLServerなど厳密なSQLデータベースの場合は必須です
GRANT ALL PRIVILEGES ON DATABASE test_db TO role_test ;

作成したばかりのRoleを確認します。新しいロールで新しいデータベースに接続します。
psql -h pgm-0iw7au5dx890i090yo.pgsql.japan.rds.aliyuncs.com -U role_test -p 5432 -d test_db

これでPostgreSQLベースのDCL操作ができることを確認できました。今度はPostgreSQLベースによるDML操作(Data Manipulation Language、データを操作するコマンド)でApsaraDB for PostgreSQLが一通り操作できるか確認します。まずはテーブルを作成します。
CREATE TABLE product (
product_id integer,
product_name text,
product_price numeric
);

作成したばかりのテーブルに対し、データを挿入します。PostgreSQLによるデータ挿入コマンドは次の通りです。
INSERT INTO table_name [ AS alias ] [ ( column_name [, ...] ) ]
[ OVERRIDING { SYSTEM | USER } VALUE ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
[ ON CONFLICT [ conflict_target ] conflict_action ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]
INSERT INTO product (product_id , product_name , product_price )
VALUES (121, 'Yombook', 109.98);
INSERT INTO product (product_id , product_name , product_price )
VALUES (111, 'Engbook', 190.12);

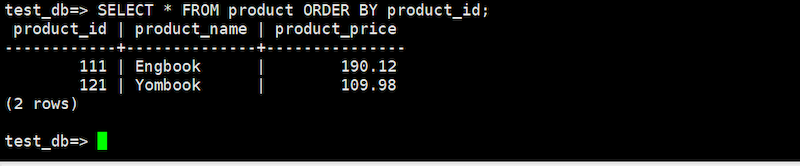
データの挿入が無事完了したら、そのデータをターゲットにSELECT文で検索してみます。
PostgreSQLによるSELECT構文のコマンドは次の通りです。
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
[ * | expression [ [ AS ] output_name ] [, ...] ]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition ]
[ WINDOW window_name AS ( window_definition ) [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES } ]
[ FOR { UPDATE | NO KEY UPDATE | SHARE | KEY SHARE } [ OF table_name [, ...] ] [ NOWAIT | SKIP LOCKED ] [...] ]
SELECT * FROM product ORDER BY product_id;
行数を数えるコマンドを確認します。PostgreSQLにはCount関数がありますので、COUNT関数を使って確認します。
SELECT COUNT(*) FROM product;

一方、PostgreSQLにはなく、SQL ServerにはCount関数では処理しきれない大きなレコード件数を返却できるCOUNT_BIG関数がありますので、試しにこのコマンドを使って確認します。
SELECT COUNT_BIG(*) FROM product;

結果、PostgreSQLクライアントからの接続ではCOUNT_BIG関数らSQL Serverコマンドは使えませんでした。
※詳細なPostgreSqlコマンドは下記リンクをご参照くださいhttps://www.postgresql.jp/document/13/html/sql-commands.html
最後に、PostgreSQLベースでPL/SQLらプロシージャ操作を確認してみます。
PL/SQLはSQLクエリの代わりにプログラミング言語(変数、代入、エラー処理、ループ、IF文など)で実行するものです。
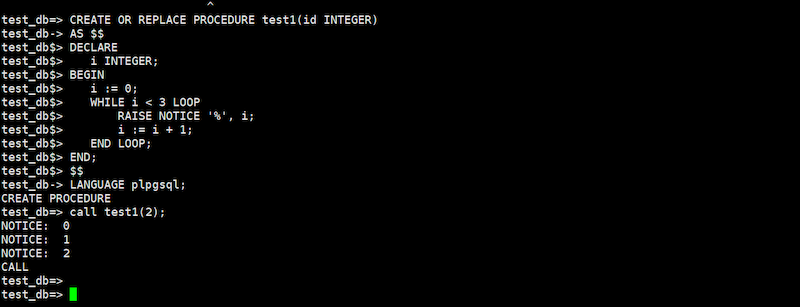
今回は値が増加していく変数に対し、その変数の値が一定の値になれば例外処理、ユーザ定義エラーを発生させます。PostgreSQLの場合、RAISEを使うことで、その変数の動きを確認することが出来ます。
CREATE OR REPLACE PROCEDURE test1(id INTEGER)
AS $$
DECLARE
i INTEGER;
BEGIN
i := 0;
WHILE i < 3 LOOP
RAISE NOTICE‘ % ’ , i;
i := i + 1;
END LOOP;
END;
$$
LANGUAGE plpgsql;
call test1(2);
6.SQLServer CLI ツールから ApsaraDB for PostgreSQL へ接続
今度はSQL ServerをクライアントとするECSインスタンスにて、SQL Server CLIツールをインストールします。流れとしてPostgreSQL CLIと同じく、CLI導入に必要なリポジトリ設定からpackage導入をします。
ShellでSQL ServerクライアントのECSインスタンスへ接続します。
公開リポジトリの GPG キーをインポートします
# curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -

Microsoft Ubuntu リポジトリを登録します。
# curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list | sudo tee /etc/apt/sources.list.d/msprod.list

パッケージリストを更新します
# sudo apt-get update

mssql-toolsをインストールします
# sudo apt-get install mssql-tools

ライセンスを承認します

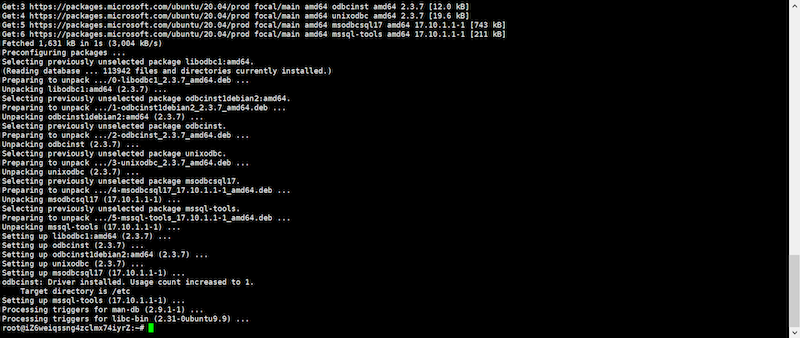
環境変数を追加します
# echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile # echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc # source ~/.bashrc

これで、SQL Server CLIクライアントの準備が完了できたので、早速接続してみます。
今回はアカウントを `inituser` にしています。
接続エンドポイントとして、SQL Server CLIからApsaraDB for PostgreSQLへ接続する際は、コンソール画面に表示されているEndpoint(pgm-<user endpoint>.pgsql.japan.rds.aliyuncs.com )、およびBabelfish TDS ポート 1433 を使用します。
準備が出来たので、SQL Server CLIツールからApsaraDB for PostgreSQLへ接続します。
接続方法は `sqlcmd -S <instance endpoint> ,1433 -U <Username>` となります。上記の例であれば、接続コマンドは以下の通りです。
# sqlcmd -S pgm-<user endpoint>.pgsql.japan.rds.aliyuncs.com,1433 -U inituser
接続後、ユーザアカウントに対するパスワードが求められるので、パスワードを入力し、ApsaraDB for PostgreSQLのPostgreSQLへ接続します。

早速ながら、SQL ServerによるSQLコマンドが通じているか確認してみます。まずはSQL Serverベースでバージョンを確認します
SELECT @@version; GO
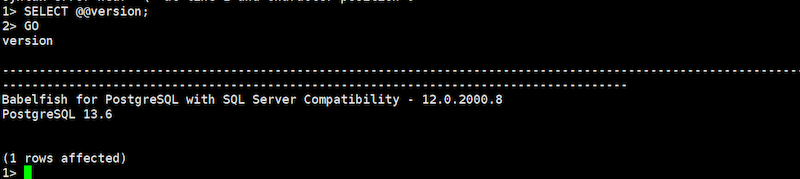
SQL Serverベースのバージョン確認コマンド `SELECT @@version;` で、PostgreSQLのバージョンが返ってきました。
ApsaraDB for PostgreSQLのBabelfish 機能でどこまでSQL Server操作ができるか、確認のために、DDL、DCL、DMLを試してみます。まずはSQL ServerによるDDL操作(Data Definition Language、データベースやテーブルなどを定義するコマンド)でPostgreSQLが一通り操作できるか確認します。
SQL Serverによるデータベース作成のコマンドは次の通りです。
CREATE DATABASE name [ [ WITH ] option [ ... ] ]
CREATE DATABASE testdb;

USE testdb;

データベースを変更します。PostgreSQLだとALTER DATABASEで実現できますが、SQL Server は ALTER DATABASE をサポートしないため、試しにやってみます。
ALTER DATABASE testdb Modify Name=dbtest;

SQL Serverによるデータベースを削除します
DROP DATABASE [ IF EXISTS ] name
DROP DATABASE testdb;
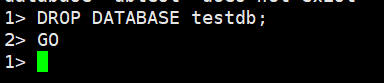
これで一通りSQL ServerベースのDDL操作ができることを確認できました。
今度はデータベース、テーブルを作成しつつ、SQL ServerによるDCL操作(Data Control Language、権限などでデータを制御するコマンド)でApsaraDB for PostgreSQLが一通り操作できるか確認します。まずは再度データベースを作成します。
CREATE DATABASE testdb;
ログイン、パスワード付きのユーザを新しく作成します。SQL Serverによるコマンドは次の通りです。
CREATE LOGIN ... PASSWORD
CREATE LOGIN testuser WITH PASSWORD = 'Test1234';

ログインのデータベースユーザを作成します。
CREATE USER testuser FOR LOGIN testuser ;

ユーザ情報を確認します。
SELECT name FROM sys.server_principals;

なお、PostgreSQLではCREATE ROLEをサポートしていますが、SQL Serverではサポートしていないので、これも想定通りサポートしていないか確認に入力してみます。

結果、サポートしていないことを確認できます。
GRANT — アクセス権限を定義してみます。
GRANT ALL ON dbo.testdb TO testuser;

testuserで接続します
# sqlcmd -S pgm-0iw7au5dx890i090yo.pgsql.japan.rds.aliyuncs.com,1433 -U testuser
データベースのSELECT構文の権限を確認します。

データベースを使用する権限がないことを確認します。
use testdb;

注意として、Babelfish機能でGRANT コマンドは対応していない部分があります。詳しくは下記リンクをご参照ください。
https://babelfishpg.org/docs/usage/limitations-of-babelfish
これでSQL ServerベースのDCL操作ができることを確認できました。今度はSQL ServerベースによるDML操作(Data Manipulation Language、データを操作するコマンド)でApsaraDB for PostgreSQLが一通り操作できるか確認します。まずはテーブルを作成します。
CREATE TABLE dbo.product (product_id integer, product_name text, product_price numeric);

作成したばかりのテーブルに対し、データを挿入します。
INSERT INTO product (product_id , product_name , product_price ) VALUES (121, 'Yombook', 09.98); INSERT INTO product (product_id , product_name , product_price ) VALUES (111, 'Engbook', 90.12);

データの挿入が無事完了したら、そのデータをターゲットにSELECT文で検索してみます。
SELECT * FROM product ORDER BY product_id;

SQLServerにはCOUNTコマンドと、COUNT_BIGコマンドの両方があり、COUNT_BIGコマンドは大きな行数を返却することができるSQLServer独自の関数です。この2つの関数を使って行数を数えるコマンドを確認します。
COUNTコマンド:
SELECT COUNT(*) FROM product;

COUNT_BIGコマンド:
SELECT COUNT_BIG(*) FROM product;
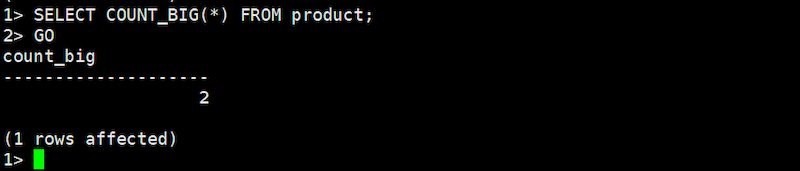
この結果から、PostgreSQLでもBabelfishを使うことでSQLServer独自関数に対応することができます。
最後に、SQL ServerベースでPL/SQLらプロシージャ操作を確認してみます。
上記、PostgreSQLのプロシージャ操作と同じ条件で、値が増加していく変数に対し、その変数の値が一定の値になれば例外処理、ユーザ定義エラーを発生させます。SQL Serverの場合、RAISERRORを使うことで、その変数の動きを確認しつつエラーを発生することが出来ます。
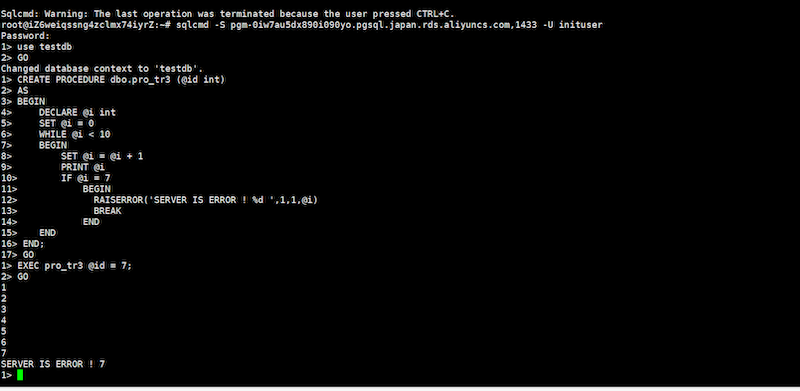
CREATE PROCEDURE dbo.pro_tr3 (@id int)
AS
BEGIN
DECLARE @i int
SET @i = 0
WHILE @i < 10
BEGIN
SET @i = @i + 1
PRINT @i
IF @i = 7
BEGIN
RAISERROR('SERVER IS ERROR ! %d ',1,1,@i)
BREAK
END
END
END;
EXEC pro_tr3 @id = 7;,
7. さいごに
今回、Alibaba Cloud ApsaraDB for PostgreSQLのBabelfish 機能でSQL Serverとしての操作ができることをご紹介しました。SQL Serverはセキュリティやバックアップ、負荷監視などさまざまな面でエンタープライズなデータベースとして便利な一方、ライセンス料からコストが高額です。それだけでなく、SQL Serverに対する運用の学習コストが高いという課題もあります。そのため、SQL Serverを利用したいけど、コストが高いことや、運用に苦労しやすい、と考えているユーザはこのBabelfish 機能を使うことで、ランニングコスト、運用コストを削減するといった選択肢もあります。
関連サービス
関連記事
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



