フォーム読み込み中
PolarDB for PostgreSQL 分散エディションについて

クラウドエンジニア
蒋 渊舒
AlibabaCloudを中心にクラウドエンジニアとして活動しています。よろしくお願いいたします。
2026年3月4日掲載

ご覧いただきありがとうございます。ソフトバンクの蒋です。
近年、データ量の増加やアプリケーションの高度化に伴い、従来の単一ノード型データベースでは性能や拡張性の限界が課題となるケースが増えています。特に、大規模なトランザクション処理や分析処理を同時に求められるシステムでは、単純なスケールアップだけでは対応が難しくなっています。
PostgreSQL は高い信頼性と豊富な拡張機能を備えたオープンソースデータベースとして広く利用されていますが、基本的には単一ノード構成を前提としています。そのため、大規模なスケールアウトを実現するには、シャーディングやミドルウェアの導入など、設計・運用面での追加対応が必要になります。こうした背景のもと、Alibaba Cloud が提供する PolarDB for PostgreSQL 分散エディションは、PostgreSQL 互換性を維持しながら分散アーキテクチャを採用し、高い拡張性と性能を実現するマネージドデータベースサービスです。
本記事では、Alibaba Cloud PolarDB for PostgreSQL 分散エディションの基本的な特徴やアーキテクチャ構成に加え、検証シナリオの違いによってパフォーマンスがどのように変化するのかを解説します。
1.PolarDB for PostgreSQL 分散エディションの特徴
PolarDB for PostgreSQL 分散エディションは、単一ノード構成とは異なり、複数ノードによる分散アーキテクチャを採用しています。これにより、スケールアップだけでなく、スケールアウトによる性能拡張が可能になります。主に以下のようなコンポーネントで構成されています。
・コンピュートノード(CN)
コンピュートノードは、クライアントからの接続を受け付け、SQL の解析・最適化・実行計画の生成を行う役割を担います。分散環境では、クエリをどのデータノードへ送信するかを判断し、必要に応じて複数ノードに対して並列実行を指示します。
コンピュートノードを追加することで、同時接続数の増加やクエリ処理能力の向上に対応できます。
・データノード(DN)
データノードは、実際のデータを保持するストレージ層を担います。テーブルは内部的に分散配置され、シャーディングされたデータが複数のデータノードに保存されます。
データノードを追加することで、ストレージ容量および書き込み性能を水平に拡張することが可能です。
・分散トランザクション制御
分散構成では、複数ノードにまたがるトランザクションの整合性を維持する必要があります。PolarDB for PostgreSQL 分散エディションでは、内部的に分散トランザクション制御を行い、ACID 特性を維持しています。これにより、アプリケーション側で特別な制御を実装することなく、従来の PostgreSQL と同様のトランザクション操作を行うことができます。
それでは、実際に PolarDB for PostgreSQL 分散エディションを購入し、クラスター作成時の設定項目や構成を確認していきます。
2.分散エディションクラスタの作成
2-1.PolarDB のコンソールから「Create Cluster」をクリックします。
2-2.購入ページで「Distributed PostgreSQL」を選択すると、分散エディション専用の購入ページへ遷移します。
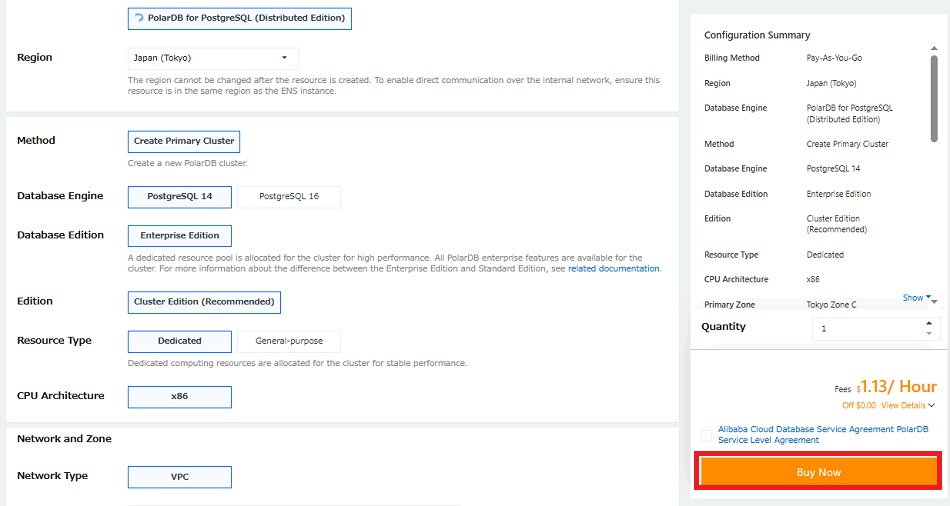
2-3.以下のクラスタ情報を選択し、「Buy Now」をクリックします。
Billing Method | Pay-As-You-Go |
|---|---|
Region | Japan(Tokyo) |
Database Engine | PostgreSQL14 |
Database Edition | Enterprise Edition |
HA Mode | Single Zone |
Resource Type | Dedicated |
Compute Node Specifications | Dedicated:2 cores, 8GB |
Data Node Specifications | Dedicated:2 cores, 8GB |
Compute Node | 1 |
Data Node | 2 |
Storage Type | PSL5 |
2-4.クラスタ作成完了後、以下の初期準備を行います。
管理用アカウントの作成
検証用データベースの作成
Private Network Endpoint の有効化
クラスタと同一 VPC 内への新規 ECS の作成
「Whitelist」への ECS プライベート IP アドレスの追加
これらの準備が完了すると、ECS からクラスタへ接続可能な状態となります。次章では、分散エディションクラスタのパフォーマンスを検証していきます。
3. ポイントクエリ性能の検証
前章では、2 台のデータノード(DN)を持つクラスタを作成しました。データを分散して保存することで、本当に性能は向上するのでしょうか。ここからは、PolarDB for PostgreSQL 分散エディションのパフォーマンスを検証します。
・検証ツール
検証ツールには、PostgreSQL 公式のベンチマークツールである pgbench を利用します。
pgbench は、トランザクション処理性能(TPS)やレイテンシを測定するために広く利用されているツールです。
・検証方法
同一クラスタ内に以下の2種類のテーブルを用意し、それぞれに対して同じワークロードを実行し、結果を比較します。
Local Table
Distributed Table
Local Table はコンピュートノード(CN)上で処理が完結するテーブルであり、Distributed Table は複数のデータノード(DN)に分散配置されるテーブルです。
同一条件で負荷をかけることで、ローカル処理と分散処理のパフォーマンス特性の違いを確認します。
3-1. 以下のコマンドで pgbench 用のテーブルとデータを作成します。この初期化が完了すると、テーブルは Local Table として作成されます。
pgbench -i -s 100 -h <Endpoint> -p 5432 -U <ユーザー名> <データベース名> |
主な引数:
-i:初期化モード
-s 100:スケールファクター(1,000万件規模のデータ)
3-2. 以下のコマンドで Select-only ワークロードを実行します。
pgbench -S -c 128 -j 128 -T 30 -P 5 -h <Endpoint> -p 5432 -U <ユーザー名> <データベース名> |
主な引数:
-S:Select-only モード
-c 128:同時接続数
-j 128:ワーカースレッド数(通常は -c と同じ値)
-T 30:テスト時間(30 秒)
-P 5:5 秒ごとに途中経過を表示
3-3. Local Tableに対する Select-only ワークロードの実行結果です。
pgbench (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1), server 14.20) starting vacuum...end. progress: 5.0 s, 0.0 tps, lat 0.000 ms stddev 0.000, 0 failed progress: 10.0 s, 64267.2 tps, lat 1.991 ms stddev 3.490, 0 failed progress: 15.0 s, 66578.5 tps, lat 1.922 ms stddev 0.863, 0 failed progress: 20.0 s, 66598.1 tps, lat 1.922 ms stddev 0.900, 0 failed progress: 25.0 s, 66748.4 tps, lat 1.918 ms stddev 0.776, 0 failed progress: 30.0 s, 65818.2 tps, lat 1.944 ms stddev 1.377, 0 failed transaction type: <builtin: select only> scaling factor: 100 query mode: simple number of clients: 128 number of threads: 128 maximum number of tries: 1 duration: 30 s number of transactions actually processed: 1649106 number of failed transactions: 0 (0.000%) latency average = 1.939 ms latency stddev = 1.784 ms initial connection time = 5017.839 ms tps = 65922.869444 (without initial connection time) |
3-4. 以下のコマンドで aid カラム(主キー)を分散キーとして指定し、テーブルを Distributed Table に変換します。これにより、aid の値に基づいてデータが複数のデータノードへ分散配置されます。
SELECT create_distributed_table('pgbench_accounts', 'aid'); |
3-5. 3-2 と同じコマンドを使用して、Distributed Tableに対する Select-only ワークロードの実行結果です。
pgbench (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1), server 14.20) starting vacuum...end. progress: 5.0 s, 0.0 tps, lat 0.000 ms stddev 0.000, 0 failed progress: 10.0 s, 23042.0 tps, lat 5.552 ms stddev 10.483, 0 failed progress: 15.0 s, 23745.6 tps, lat 5.391 ms stddev 2.434, 0 failed progress: 20.0 s, 23695.0 tps, lat 5.402 ms stddev 2.801, 0 failed progress: 25.0 s, 24125.0 tps, lat 5.306 ms stddev 2.763, 0 failed progress: 30.0 s, 23741.9 tps, lat 5.391 ms stddev 4.311, 0 failed transaction type: <builtin: select only> scaling factor: 100 query mode: simple number of clients: 128 number of threads: 128 maximum number of tries: 1 duration: 30 s number of transactions actually processed: 591450 number of failed transactions: 0 (0.000%) latency average = 5.410 ms latency stddev = 5.434 ms initial connection time = 5018.487 ms tps = 23602.086657 (without initial connection time) |
今回の Select-only ワークロードでは、Distributed Table の方が低い TPS と高いレイテンシを示しました。
TPS:約 64% 低下(23602.08 ÷ 65922.86 ≒ 0.36)
レイテンシ:約 2.79 倍増加(5.41 ms / 1.939 ms ≒ 2.79)
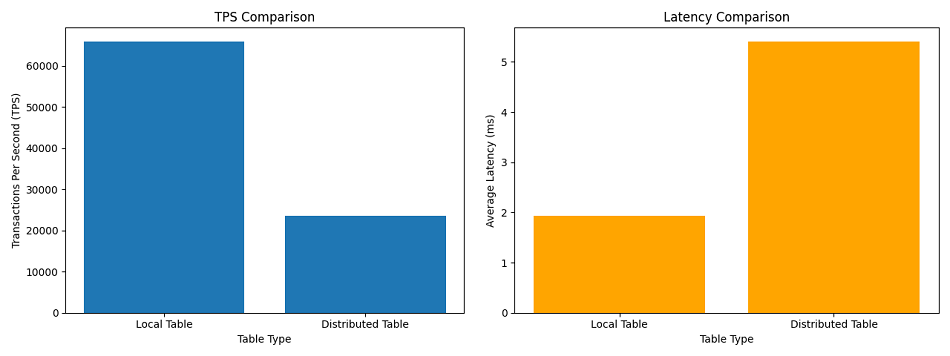
これは、Local Table では処理が単一ノード内で完結するのに対し、Distributed Table では以下のオーバーヘッドが発生するためです。
クエリの分散実行
ノード間通信
結果の集約処理
今回のワークロードは単純な単一テーブルの SELECT 処理であり、分散による並列化の恩恵よりも、分散処理に伴うオーバーヘッドの影響が大きく現れたと考えられます。
一方で、データ量がさらに増加した場合や、複数ノードで並列処理が有効に機能する集計・分析系クエリでは、Distributed Table の優位性が発揮される可能性があります。
この結果から分かる重要なポイントは、分散エディションは常に高速になるわけではなく、ワークロード特性に応じた設計が重要であるという点です。
4.フルスキャン性能の検証
前章の Select-only ワークロードでは、Distributed Table の方が低い TPS と高いレイテンシを示しました。では、PolarDB for PostgreSQL 分散エディションの真価を発揮できるワークロードとはどのようなものでしょうか。
この点を検証するため、本章ではフルスキャン処理を伴うクエリを実行し、Distributed Table の特性を確認します。実行したクエリは以下の通りで、テーブル全体を対象に行数を集計する単純な集約クエリです。
count.sql
select count(*) from pgbench_accounts; |
4-1. 前回の検証の影響を受けないよう、検証用データベースを初期化し、再度 pgbench 用のテーブルとデータを作成します。
pgbench -i -s 100 -h <Endpoint> -p 5432 -U <ユーザー名> <データベース名> |
4-2. 以下のコマンドでフルスキャンワークロードを実行します。
pgbench -n -f count.sql -c 4 -j 4 -T 60 -P 5 -h <Endpoint> -p 5432 -U <ユーザー名> <データベース名> |
主な引数:
-f:実行対象の SQL 文を記載したファイル
4-3. Local Tableに対するフルスキャンワークロードの実行結果です。
pgbench (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1), server 14.20) progress: 5.0 s, 4.4 tps, lat 804.930 ms stddev 324.329, 0 failed progress: 10.0 s, 4.8 tps, lat 826.265 ms stddev 327.398, 0 failed progress: 15.0 s, 4.8 tps, lat 857.607 ms stddev 381.063, 0 failed progress: 20.0 s, 4.8 tps, lat 813.440 ms stddev 346.699, 0 failed progress: 25.0 s, 5.2 tps, lat 752.453 ms stddev 310.763, 0 failed progress: 30.0 s, 4.8 tps, lat 845.756 ms stddev 513.025, 0 failed transaction type: count.sql scaling factor: 1 query mode: simple number of clients: 4 number of threads: 4 maximum number of tries: 1 duration: 30 s number of transactions actually processed: 148 number of failed transactions: 0 (0.000%) latency average = 818.314 ms latency stddev = 374.410 ms initial connection time = 7.712 ms tps = 4.868234 (without initial connection time) |
4-4. aid カラム(主キー)を分散キーとして指定し、テーブルを Distributed Table に変換します。
SELECT create_distributed_table('pgbench_accounts', 'aid'); |
4-5. 4-2と同じコマンドを使用して、Distributed Table に対するフルスキャンワークロードの実行結果です。
pgbench (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1), server 14.20) progress: 5.0 s, 7.4 tps, lat 512.305 ms stddev 42.933, 0 failed progress: 10.0 s, 8.0 tps, lat 507.006 ms stddev 46.018, 0 failed progress: 15.0 s, 7.6 tps, lat 509.051 ms stddev 43.009, 0 failed progress: 20.0 s, 8.0 tps, lat 517.857 ms stddev 38.314, 0 failed progress: 25.0 s, 7.4 tps, lat 538.642 ms stddev 79.564, 0 failed progress: 30.0 s, 7.8 tps, lat 505.287 ms stddev 95.018, 0 failed transaction type: count.sql scaling factor: 1 query mode: simple number of clients: 4 number of threads: 4 maximum number of tries: 1 duration: 30 s number of transactions actually processed: 235 number of failed transactions: 0 (0.000%) latency average = 514.207 ms latency stddev = 62.820 ms initial connection time = 5.760 ms tps = 7.747087 (without initial connection time) |
今回のフルスキャン検証では、Distributed Table の方が明確に優位な結果となりました。
TPS:約 1.59 倍向上(7.75 ÷ 4.87 ≒ 1.59)
レイテンシ:約 37% 短縮(514 ms / 818 ms ≒ 0.63)
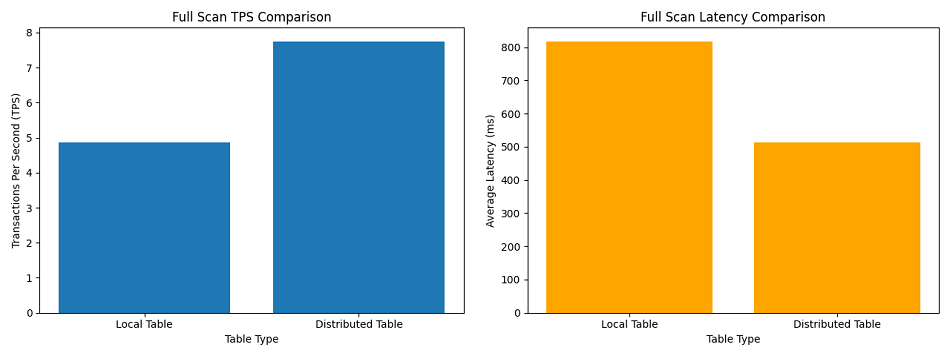
今回の構成では、データノード(DN)が 2 台構成であるため、count(*) 実行時には 2 台の DN がそれぞれ自身のデータを同時にフルスキャンします。つまり、単一ノードで順次処理するのではなく、2 台分の処理能力を同時に活用できる構造となっています。
その結果、フルスキャンという CPU・I/O 負荷の高い処理においては、分散による並列処理の効果が大きく表れました。今回の検証では、分散処理に伴うオーバーヘッドよりも、2 台の DN による並列スキャンの効果が上回ったことが確認できました。
5.おわりに
本記事では、Alibaba Cloud PolarDB for PostgreSQL 分散エディションのアーキテクチャ概要からクラスター作成、そしてワークロード別のパフォーマンス検証までを通して、その特性を確認しました。
ポイントクエリ中心のワークロードでは Local Table が優位となる一方、count(*) のようなフルスキャン処理では、2 台のデータノードによる並列実行が効果を発揮し、Distributed Table が明確に優位となることが分かりました。この結果から、分散エディションは常に高速になるわけではなく、ワークロード特性に応じて性能が大きく変化するデータベースであることが示されました。
分散アーキテクチャの効果を最大限に引き出すためには、実行されるクエリの特性や将来的なデータ増加を見据えた設計が重要です。単一ノード構成では限界が見えてくるような大規模ワークロードにおいて、PolarDB for PostgreSQL 分散エディションは有力な選択肢の一つとなるでしょう。
本記事が、分散データベースの選定や設計検討の一助となれば幸いです。最後までお読みいただき、ありがとうございました。
関連サービス
Alibaba Cloudは中国国内でのクラウド利用はもちろん、日本-中国間のネットワークの不安定さの解消、中国サイバーセキュリティ法への対策など、中国進出に際する課題を解消できるパブリッククラウドサービスです。
MSP(Managed Service Provider)サービスは、お客さまのパブリッククラウドの導入から運用までをトータルでご提供するマネージドサービスです。
\ 業務課題をデジタルで支援 /
デジタルツールの選定から導入の手引きまで、中小規模のお客さまへわかりやすくお伝えします。
メールマガジン登録(無料)
ビジネスに役立つ記事やウェビナー情報をお届けします。
おすすめの記事
条件に該当するページがございません



