Press Releases 2026
SoftBank Corp. and Ampere to Launch Joint Validation
to Improve Operational Efficiency
of Small-scale AI Models Using CPUs
Companies enabling highly efficient distributed operation of multiple small-scale AI models
on CPUs for the AI agent era
February 17, 2026
SoftBank Corp.
SoftBank Corp. ("SoftBank") began a joint validation project with Ampere® Computing LLC ("Ampere"), a U.S.-based semiconductor company, to improve the operational efficiency of AI models running on CPUs, one of the key components for next-generation AI infrastructure.
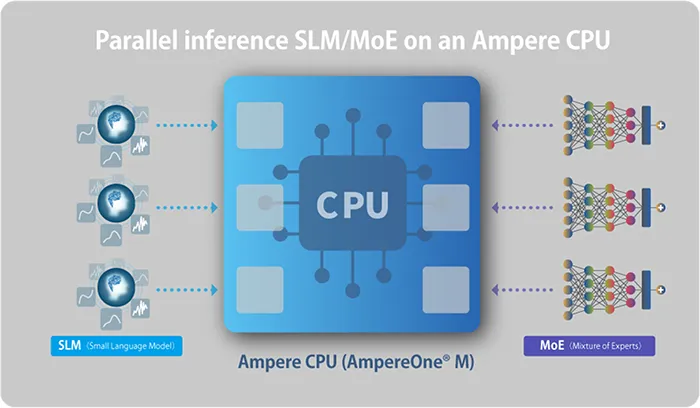
In this joint validation, SoftBank is combining its under-development Orchestrator—which manages compute resources and optimally allocates AI models—with Ampere CPUs designed for AI inference processing. Together, they confirmed that CPUs can be effectively used as compute resources for AI inference. By running SLMs (Small Language Models) commonly used in AI agents and inference models, such as Mixture of Experts (MoE)*, on CPUs, it is possible to optimize AI model operations and improve the utilization efficiency of compute resources.
- [Note]
-
- *A model architecture that limits computation load by activating only a subset of "experts" during inference.
- *
Background
With the utilization of AI, demands are growing not only for large language models (LLMs), but also for AI models specialized for specific use cases that can deliver high practical utility with a relatively small number of parameters. In particular, fields such as AI agents, business process automation and network control require inference processing that offers both low-latency responses and high power efficiency under always-on operating conditions. In this context, SoftBank and Ampere launched this initiative to improve the utilization efficiency of compute resources in next-generation AI infrastructure by enhancing the operational efficiency and deployment of CPU-based AI inference environments.
Overview of the joint validation
In this joint validation, SoftBank and Ampere assumed a distributed computing environment and evaluated the performance, scalability and operability of CPU-based AI inference environments using SLMs and MoE models for AI agents. Both companies also experimented in multi-node environments that include nodes equipped only with CPUs as well as nodes equipped with both CPUs and GPUs. By implementing optimal allocation and control functions into the Orchestrator, they confirmed that AI models can be flexibly placed, managed and optimized according to use case characteristics and compute load profiles.
In addition, by implementing "Ampere® optimized llama.cpp," an Ampere CPU–optimized version based on the open-source AI inference framework llama.cpp, the evaluation confirmed that it is possible to increase the number of concurrent inference workloads while reducing power consumption compared to typical GPU-based configurations. The evaluation also demonstrated significantly reduced AI model loading times, which enables fast and dynamic model switching.
Future outlook
Leveraging these results, SoftBank and Ampere will continue working toward the realization of an AI inference platform for AI agents that can dynamically switch between multiple models while maintaining stable TPS (Tokens Per Second: the number of tokens generated per second). Through its collaboration with Ampere, SoftBank will promote the establishment of a low-latency, high-efficiency AI inference environment as one of the key technologies for next-generation AI infrastructure, thereby contributing to the broader use of AI agents and SLMs.
Ryuji Wakikawa,Vice President and Head of the Research Institute of Advanced Technology at SoftBank Corp., said:
"Through our work with Ampere, we have validated the practicality of CPU-based AI inference. The performance of Ampere CPUs, powered by Arm, provides the efficiency and scalability required for widespread AI agent deployment."
Sean Varley, Chief Evangelist at Ampere, said:
"Ampere CPUs are purpose-built to deliver predictable performance and exceptional power efficiency for dynamic, distributed AI inference workloads, like those found in SLMs and MoE models. This joint effort validates that CPUs can be a highly efficient, cost-effective, and scalable foundation for next-generation AI infrastructure, paving the way for broader AI agent adoption."
- SoftBank, the SoftBank name and logo are registered trademarks or trademarks of SoftBank Group Corp. in Japan and other countries.
- Other company, product and service names in this press release are registered trademarks or trademarks of the respective companies.
- About the SoftBank Research Institute of Advanced Technology
-
Guided by its mission to implement new technologies into society, SoftBank Corp.'s Research Institute of Advanced Technology promotes R&D and business creation for advanced technologies that support next-generation social infrastructure, including AI-RAN and Beyond 5G/6G, as well as telecommunications, AI, computing, quantum technologies, and technologies in the space and energy sectors. Through industry-academia collaboration and joint research with universities, research institutions and partner companies in Japan and abroad, the SoftBank Research Institute of Advanced Technology is contributing to the creation of global businesses and a sustainable society. For more details, please visit the official website.